
РДД-03. Изготовитель оставляет за собой право вносить изменения в конструкцию и принципиальную схему изделия, не ухудшающие его характеристик.
СИГНАЛИЗАТОР УРОВНЯ РСУ-1. ПАСПОРТ
СИГНАЛИЗАТОР УРОВНЯ РСУ-1. ПАСПОРТ Все права защищены. Авторское свидетельство Российского агенства по патентам и товарным знакам 22820 от 27.04.2002 г. Продукция соответствует ТР ТС 010/2011 «О безопасности
ПодробнееРС У -2. СИГНАЛИЗАТОР УРОВНЯ ПАСПОРТ
СИГНАЛИЗАТОР УРОВНЯ РС У -2. ПАСПОРТ Все права защищены. Авторское свидетельство Российского агенства по патентам и товарным знакам 22820 от 27.
СИГНАЛИЗАТОР УРОВНЯ РСУ-1Р. ПАСПОРТ
СИГНАЛИЗАТОР УРОВНЯ РСУ-1Р. ПАСПОРТ Все права защищены. Авторское свидетельство Российского агенства по патентам и товарным знакам 22820 от 27.04.2002 г. Продукция соответствует ТР ТС 010/2011 «О безопасности
ПодробнееРДКС-03АРС. СОДЕРЖАНИЕ
Общество с ограниченной ответственностью «Промрадар» 143517, Московская область, Истринский район, станция Холщёвики. Тел./факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
ПодробнееИСТОЧНИК ПИТАНИЯ ББП-20М
ИСТОЧНИК ПИТАНИЯ ББП-20М ТУ 4372 002 63438766 14 СЕРТИФИКАТ СООТВЕТСТВИЯ ТС RU С-RU.AЛ16.B.02558 Серия RU 0228076 ПАСПОРТ ВВЕДЕНИЕ Настоящий паспорт предназначен для изучения обслуживающим персоналом правил
ПодробнееИСТОЧНИК ПИТАНИЯ ББП-24
ИСТОЧНИК ПИТАНИЯ ББП-24 ТУ 4372 002 63438766 14 СЕРТИФИКАТ СООТВЕТСТВИЯ ТС RU С-RU.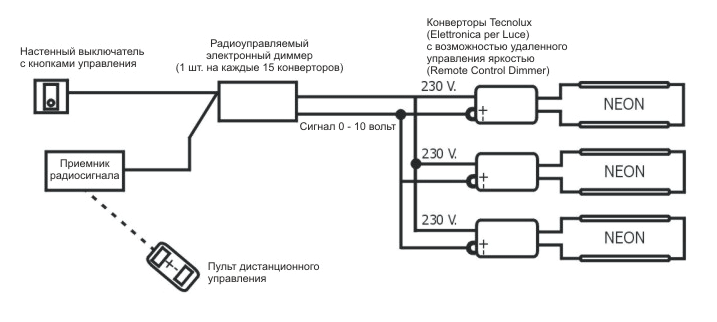 AЛ16.B.02558 Серия RU 0228076 ПАСПОРТ ВВЕДЕНИЕ Настоящий паспорт предназначен для изучения обслуживающим персоналом правил
AЛ16.B.02558 Серия RU 0228076 ПАСПОРТ ВВЕДЕНИЕ Настоящий паспорт предназначен для изучения обслуживающим персоналом правил
ТЕРМОРЕГУЛЯТОР ТР 111
10. Свидетельство о приемке Терморегулятор ТР 111 прошел заводские испытания и признан годным к эксплуатации. Дата выпуска Штамп ОТК Дата продажи Штамп магазина ИЗГОТОВИТЕЛЬ: ООО «Специальные Инженерные
ПодробнееБЛОК РЕЧЕВОГО ОПОВЕЩЕНИЯ ЯНТАРЬ БРО
БЛОК РЕЧЕВОГО ОПОВЕЩЕНИЯ ЯНТАРЬ БРО 1. Назначение Блок речевого оповещения ЯНТАРЬ БРО (далее «изделие») предназначен для работы в составе системы речевого оповещения в качестве устройства формирования
Зав. АА Дата приемки Штамп ОТК
БЛОК РЕЧЕВОГО ОПОВЕЩЕНИЯ АРИЯ-БРО-Р ТУ 4372-021-49518441-10, изм.4 1. Назначение Блок речевого оповещения АРИЯ-БРО-Р (далее «изделие») предназначен для работы в составе системы речевого оповещения АРИЯ
ПодробнееЗав.
 АА Дата приемки Штамп ОТК
АА Дата приемки Штамп ОТКБЛОК РАСШИРЕНИЯ АРИЯ-БР-Р ТУ 4372-021-49518441-10, изм.4 1. Назначение Блок расширения АРИЯ-БР-Р (далее «изделие») предназначен для работы в составе системы речевого оповещения АРИЯ в качестве усилителя
ПодробнееПаспорт ЮКСО ПС
ПАУК-В Извещатель (прибор) охранный вибрационный Паспорт ЮКСО 33.02.000 ПС Декларация о соответствии ТС RU Д-RU.АЛ16.В.20431 Декларация о соответствии ТС RU Д-RU.АГ03.В.81010 2015 г. 1 Общие сведения 1.1
ПодробнееЗав. АА Дата приемки Штамп ОТК
БЛОК РАСШИРЕНИЯ ТУ 4372-021-49518441-10, изм.4 1. Основные отличительные особенности – повышена выходная мощность; – расширен диапазон воспроизводимых частот; – повышена частота проведения контроля целостности
ПодробнееТС , (498) , (496) (495) , (495) (498) /2011 «О
Общество с ограниченной ответственностью «Промрадар» 143517, Московская область, Истринский район, станция Холщёвики. Тел./факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
Тел./факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
ТС , (498) , (496) (495) , (495) (498) /2011 «О
Общество с ограниченной ответственностью «Промрадар» 143517, Московская область, Истринский район, станция Холщёвики. Тел./факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
ПодробнееЗав. АА Дата приемки Штамп ОТК
БЛОК РЕЧЕВОГО ОПОВЕЩЕНИЯ АРИЯ-БРО-М-МИНИ ТУ 4372-019-49518441-12 ПАСПОРТ 1. Назначение Блок речевого оповещения АРИЯ-БРО-М-МИНИ (далее «изделие») предназначен для работы в составе системы речевого оповещения
ПодробнееПаспорт Руководство по эксплуатации
О О О «Н П Ф Т е х э н е р г о к о м п л е к с» Блок питания от токовых цепей и управления высоковольтным выключателем БП-ТЭК-220-5-2 У4 Паспорт Руководство по эксплуатации 2013г.
ЩИТ СИГНАЛИЗАЦИИ ЩСМ-31-8
ЩИТ СИГНАЛИЗАЦИИ ЩСМ-31-8 Руководство по эксплуатации г. Херсон 2010 г. 1 1. НАЗНАЧЕНИЕ Щит сигнализации ЩСМ-31-8 предназначен для контроля состояния сигнализаторов загазованности типа «ЛЕЛЕКА» или аналогичных,
Подробнее2. ТЕХНИЧЕСКИЕ ДАННЫЕ И ХАРАКТЕРИСТИКИ
1. НАЗНАЧЕНИЕ Источники питания постоянного тока серии БП-98 (далее источники питания) предназначены для преобразования сетевого напряжения 220В в стабилизированное напряжение 5 36В. Прибор выпускается
ПодробнееРЕГУЛЯТОР УРОВНЯ ДВУХКАНАЛЬНЫЙ
Чернигов РУ2 РЕГУЛЯТОР УРОВНЯ ДВУХКАНАЛЬНЫЙ (c логикой сигнализатора) Руководство по эксплуатации и паспорт Содержание 1 Назначение 3 2 Описание работы прибора 3 3 Технические характеристики 9 4 Техническое
Модуль LightControl Техническое описание
Модуль LightControl Техническое описание www. tecel.ru Описание модуля Автомобильный модуль LightControl (далее модуль) является программируемым электронным устройством, которое предназначено для управления
tecel.ru Описание модуля Автомобильный модуль LightControl (далее модуль) является программируемым электронным устройством, которое предназначено для управления
РЕЛЕ ВРЕМЕНИ РВВ-1ВК
ООО Т А У РЕЛЕ ВРЕМЕНИ РВВ-1ВК Техническое описание и инструкция по эксплуатации. ТС5.021.03-07 Сертификат соответствия ТС RU C-RU.МЛ02.В.00820 САНКТ-ПЕТЕРБУРГ 2019г. 1. НАЗНАЧЕНИЕ РЕЛЕ ВРЕМЕНИ РВВ-1ВК.
ПодробнееРЕГУЛЯТОР УРОВНЯ ТРЕХКАНАЛЬНЫЙ
Чернигов РУ3 РЕГУЛЯТОР УРОВНЯ ТРЕХКАНАЛЬНЫЙ Руководство по эксплуатации и паспорт Содержание 1 Назначение 3 2 Описание работы прибора 3 3 Технические характеристики 10 4 Техническое обслуживание 12 5 Хранение
ПодробнееМОДУЛЬ УПРАВЛЕНИЯ Neptun Base
МОДУЛЬ УПРАВЛЕНИЯ Neptun Base ОБРАБАТЫВАЕТ СИГНАЛ ОТ ДАТЧИКОВ КОНТРОЛЯ ПРОТЕЧКИ ВОДЫ И ВЫДАЕТ УПРАВЛЯЮЩИЙ СИГНАЛ НА КРАН ШАРОВОЙ С ЭЛЕКТРОПРИВОДОМ ПАСПОРТ-ИНСТРУКЦИЯ ПО МОНТАЖУ И ЭКСПЛУАТАЦИИ РЭА. 00055.04
00055.04
Зав. АА Дата приемки Штамп ОТК
БЛОК РЕЧЕВОГО ОПОВЕЩЕНИЯ АРИЯ-БРО-М ТУ 4372-021-49518441-10, изм.4 1. Назначение Блок речевого оповещения АРИЯ-БРО-М (далее «изделие») предназначен для работы в составе системы речевого оповещения АРИЯ
Зарядное устройство ЗУ.240В.5А
Зарядное устройство ЗУ.240В.5А Руководство по эксплуатации МИДН9.165.00.00 РЭ г. Киев 2009 г. 1. Введение Настоящее руководство по эксплуатации (РЭ), является документом, удостоверяющим гарантированные
ПодробнееМОДУЛЬ УПРАВЛЕНИЯ Neptun Base
МОДУЛЬ УПРАВЛЕНИЯ Neptun Base ОБРАБАТЫВАЕТ СИГНАЛ ОТ ДАТЧИКОВ КОНТРОЛЯ ПРОТЕЧКИ ВОДЫ И ВЫДАЕТ УПРАВЛЯЮЩИЙ СИГНАЛ НА КРАН ШАРОВЫЙ С ЭЛЕКТРОПРИВОДОМ ПАСПОРТ-ИНСТРУКЦИЯ ПО МОНТАЖУ И ЭКСПЛУАТАЦИИ РОСС RU. ME67.B07820
ME67.B07820
ПАСПОРТ и ИНСТРУКЦИЯ ПО ЭКСПЛУАТАЦИИ
МОДУЛЬ КОНТРОЛЯ ПЛАМЕНИ МКП-1D ТУ 3113-009-54596443-2003 Разрешение Федерального горного и промышленного надзора России РРС-33-075 от 02.02.2004г. ПАСПОРТ и ИНСТРУКЦИЯ ПО ЭКСПЛУАТАЦИИ СОДЕРЖАНИЕ. Страница
ПодробнееМОДУЛЬ УПРАВЛЕНИЯ Neptun Base
МОДУЛЬ УПРАВЛЕНИЯ Neptun Base ОБРАБАТЫВАЕТ СИГНАЛ ОТ ДАТЧИКОВ КОНТРОЛЯ ПРОТЕЧКИ ВОДЫ И ВЫДАЕТ УПРАВЛЯЮЩИЙ СИГНАЛ НА КРАН ШАРОВОЙ С ЭЛЕКТРОПРИВОДОМ ПАСПОРТ-ИНСТРУКЦИЯ ПО МОНТАЖУ И ЭКСПЛУАТАЦИИ РЭА.00055.04
ПодробнееТЕПЛОКОМ БЛОК УПРАВЛЕНИЯ БУ
ТЕПЛОКОМ БЛОК УПРАВЛЕНИЯ БУ 2 Руководство пользователя РБЯК.648233.030 Д1 www.teplocom.nt-rt.ru с. 2 Руководство пользователя 1 Общие положения Блок управления БУ 2 используется для силового управления
ПодробнееРДД-02А.
 ВНИМАНИЕ! Напряжение, подаваемое на клеммы 4 и 5 данного экземпляра прибора, должно находиться в диапазоне от 21 до 27 В постоянного тока!
ВНИМАНИЕ! Напряжение, подаваемое на клеммы 4 и 5 данного экземпляра прибора, должно находиться в диапазоне от 21 до 27 В постоянного тока! СИГНАЛИЗАТОР УРОВНЯ РСУ-1. ПАСПОРТ
СИГНАЛИЗАТОР УРОВНЯ РСУ-1. ПАСПОРТ Все права защищены. Авторское свидетельство Российского агенства по патентам и товарным знакам 22820 от 27.04.2002 г. Продукция соответствует ТР ТС 010/2011 «О безопасности
ПодробнееРС У -2. СИГНАЛИЗАТОР УРОВНЯ ПАСПОРТ
СИГНАЛИЗАТОР УРОВНЯ РС У -2. ПАСПОРТ Все права защищены. Авторское свидетельство Российского агенства по патентам и товарным знакам 22820 от 27. 04.2002 г. Продукция соответствует ТР ТС 010/2011 «О безопасности
04.2002 г. Продукция соответствует ТР ТС 010/2011 «О безопасности
СИГНАЛИЗАТОР УРОВНЯ РСУ-1Р. ПАСПОРТ
СИГНАЛИЗАТОР УРОВНЯ РСУ-1Р. ПАСПОРТ Все права защищены. Авторское свидетельство Российского агенства по патентам и товарным знакам 22820 от 27.04.2002 г. Продукция соответствует ТР ТС 010/2011 «О безопасности
ПодробнееРДКС-03АРС. СОДЕРЖАНИЕ
Общество с ограниченной ответственностью «Промрадар» 143517, Московская область, Истринский район, станция Холщёвики. Тел./факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
ПодробнееТС , (498) , (496) (495) , (495) (498) /2011 «О
Общество с ограниченной ответственностью «Промрадар» 143517, Московская область, Истринский район, станция Холщёвики. Тел. /факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
/факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
ТС , (498) , (496) (495) , (495) (498) /2011 «О
Общество с ограниченной ответственностью «Промрадар» 143517, Московская область, Истринский район, станция Холщёвики. Тел./факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
ПодробнееИСТОЧНИК ПИТАНИЯ ББП-24
ИСТОЧНИК ПИТАНИЯ ББП-24 ТУ 4372 002 63438766 14 СЕРТИФИКАТ СООТВЕТСТВИЯ ТС RU С-RU.AЛ16.B.02558 Серия RU 0228076 ПАСПОРТ ВВЕДЕНИЕ Настоящий паспорт предназначен для изучения обслуживающим персоналом правил
ПодробнееТЕРМОРЕГУЛЯТОР ТР 111
10. Свидетельство о приемке Терморегулятор ТР 111 прошел заводские испытания и признан годным к эксплуатации. Дата выпуска Штамп ОТК Дата продажи Штамп магазина ИЗГОТОВИТЕЛЬ: ООО «Специальные Инженерные
ПодробнееПаспорт Руководство по эксплуатации
О О О «Н П Ф Т е х э н е р г о к о м п л е к с» Блок питания от токовых цепей и управления высоковольтным выключателем БП-ТЭК-220-5-2 У4 Паспорт Руководство по эксплуатации 2013г. 22 Блок питания от токовых
22 Блок питания от токовых
ИСТОЧНИК ПИТАНИЯ ББП-20М
ИСТОЧНИК ПИТАНИЯ ББП-20М ТУ 4372 002 63438766 14 СЕРТИФИКАТ СООТВЕТСТВИЯ ТС RU С-RU.AЛ16.B.02558 Серия RU 0228076 ПАСПОРТ ВВЕДЕНИЕ Настоящий паспорт предназначен для изучения обслуживающим персоналом правил
ПодробнееРУП «Белэлектромонтажналадка»
РУП «Белэлектромонтажналадка» БЛОК ПИТАНИЯ ОТ ТОКОВЫХ ЦЕПЕЙ БПТ-615 ПАСПОРТ ПШИЖ 190.00.00.001 ПС БЕЛАРУСЬ 220050, г. Минск, ул. Революционная 8, т./ф. (017) 226-88-11, 226-88-02 1 СОДЕРЖАНИЕ 1 Описание
ПодробнееЗав. АА Дата приемки Штамп ОТК
БЛОК РАСШИРЕНИЯ ТУ 4372-021-49518441-10, изм.4 1. Основные отличительные особенности – повышена выходная мощность; – расширен диапазон воспроизводимых частот; – повышена частота проведения контроля целостности
Подробнееelektroservice.
 com.ua
com.uainternet: Реле скорости РС-67* (складского хранения) Обозначение краткое: РС-67 Реле скорости РС-67 выпускается с искробезопасными цепями управления, коэффициент искробезопасности которых равен 1,5. Реле
ПодробнееФОТОЭЛЕКТРИЧЕСКИЕ СИГНАЛИЗАТОРЫ СУФ-5
Научно-производственное предприятие “ТЕХНОПРИБОР” ФОТОЭЛЕКТРИЧЕСКИЕ СИГНАЛИЗАТОРЫ СУФ-5 Паспорт 2010 2 СУФ-5. ПС 1. Назначение Сигнализаторы серии СУФ-5 предназначены для контроля прозрачности среды. Если
ПодробнееБЛОК ПОДКЛЮЧЕНИЯ КРАНОВ PROW
Вопросы, связанные с установкой и работой блока подключения кранов ProW можно задать консультанту по телефону: Горячая линия: 8 (800) 775-40-42 БЛОК ПОДКЛЮЧЕНИЯ КРАНОВ PROW УВЕЛИЧИВАЕТ ЧИСЛО ПОДКЛЮЧАЕМЫХ
ПодробнееРЕГУЛЯТОР УРОВНЯ ДВУХКАНАЛЬНЫЙ
Чернигов РУ2 РЕГУЛЯТОР УРОВНЯ ДВУХКАНАЛЬНЫЙ (c логикой сигнализатора) Руководство по эксплуатации и паспорт Содержание 1 Назначение 3 2 Описание работы прибора 3 3 Технические характеристики 9 4 Техническое
ПодробнееТС , (498) , (496) (495) , (495) (498) /2011 «О
Общество с ограниченной ответственностью «Промрадар» 143517, Московская область, Истринский район, станция Холщёвики. Тел./факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
Тел./факс (498) 729-28-74, (496) 315-71-26. Тел. (495) 507-51-24, (495) 924-36-39.
Паспорт ЮКСО ПС
ПАУК-В Извещатель (прибор) охранный вибрационный Паспорт ЮКСО 33.02.000 ПС Декларация о соответствии ТС RU Д-RU.АЛ16.В.20431 Декларация о соответствии ТС RU Д-RU.АГ03.В.81010 2015 г. 1 Общие сведения 1.1
ПодробнееПаспорт Руководство по эксплуатации
ООО «НПФ Техэнергокомплекс» Блок питания от токовых цепей и управления высоковольтным выключателем БП-ТЭК-220-5-1 Паспорт Руководство по эксплуатации 2006г. 22 Блок питания от токовых цепей и управления
ПодробнееТермошкаф ТШ-3В ПАСПОРТ ИМПФ ПС
Внимание! Температура корпуса обогревателя во время работы превышает 70 С, во избежание повреждения аппаратуры и кабелей производите их монтаж на расстоянии не менее 3 см от обогревателя. Свободное пространство
Свободное пространство
Пульт сигнализации ПС. Паспорт ЯРКГ ПС
Пульт сигнализации ПС Паспорт ЯРКГ 3.624.001 ПС 2015 ЯРКГ 3.624.001 ПС 1 Пульт сигнализации ПС (далее пульт) предназначен для формирования звуковых и световых сигналов с целью оповещения персонала о наступлении
ПодробнееБлок питания одноканальный
БП60Б-Д Блок питания одноканальный 109456, Москва, 1-й Вешняковский пр., д.2 тел.: (495) 174-82-82, 171-09-21 Р. 308 Зак. 781 паспорт и руководство по эксплуатации СОДЕРЖАНИЕ 1. Назначение… 2 2. Технические
ПодробнееМОДУЛЬ УПРАВЛЕНИЯ Neptun Base
МОДУЛЬ УПРАВЛЕНИЯ Neptun Base ОБРАБАТЫВАЕТ СИГНАЛ ОТ ДАТЧИКОВ КОНТРОЛЯ ПРОТЕЧКИ ВОДЫ И ВЫДАЕТ УПРАВЛЯЮЩИЙ СИГНАЛ НА КРАН ШАРОВОЙ С ЭЛЕКТРОПРИВОДОМ ПАСПОРТ-ИНСТРУКЦИЯ ПО МОНТАЖУ И ЭКСПЛУАТАЦИИ РЭА. 00055.04
00055.04
Многоканальный блок питания
БП07-Д3.2.-Х Многоканальный блок питания 109456, Москва, 1-й Вешняковский пр., д.2 тел.: (495) 174-82-82, 171-09-21 Р. 283 Зак. паспорт и руководство по эксплуатации СОДЕРЖАНИЕ Введение… 2 1. Технические
ПодробнееЗАЩИТНОЕ УСТРОЙСТВО АЛЬБАТРОС-1500 DIN
ЗАЩИТНОЕ УСТРОЙСТВО АЛЬБАТРОС-1500 DIN РУКОВОДСТВО ПО ЭКСПЛУАТАЦИИ ФИАШ.425519.131 РЭ Благодарим Вас за выбор нашего защитного устройства. Настоящее руководство по эксплуатации предназначено для ознакомления
ПодробнееЗАЩИТНОЕ УСТРОЙСТВО АЛЬБАТРОС-1500 DIN
ЗАЩИТНОЕ УСТРОЙСТВО АЛЬБАТРОС-1500 DIN РУКОВОДСТВО ПО ЭКСПЛУАТАЦИИ ФИАШ.425519.190 РЭ Благодарим Вас за выбор нашего защитного устройства АЛЬБАТРОС-1500 DIN Перед эксплуатацией ознакомьтесь с настоящим
Подробнее|
Тип |
Основные особенности |
|
|
Блок А-01 |
Для малорукавных фильтров (от 1 до 8 ЭПК с рабочим напряжением 24-250 В AC/DC). |
|
|
Блоки А-02, А-02-1 |
Для фильтров с числом электропневмоклапанов от 1 до 24. К блоку А-02 подключаются клапаны с сетевым рабочим напряжением (220 В, 50 Гц), а блок А-02-1 управляет клапанами с номинальным напряжением от 24 до 250 В постоянного или переменного тока. |
|
|
Блок А-03 |
Для фильтров, на которых установлено 8, 16 или 24 ЭПК с сетевым рабочим напряжением. Схема подключения ЭПК минимизирует количество соединительных проводов (6 проводов – для 8-ми клапанов, 8 проводов – для 16-ти, 10 проводов – для 24-х клапанов). |
|
|
Блок А-04 |
Для управления электромеханическим пневмораспределителем фирмы «Ocrim» (Италия), который, вращаясь, поочерёдно подаёт сжатый воздух в 24 фильтровальных элемента. |
|
|
Индикатор диф. давления ИРД-4 |
Контролирует загрязнённость фильтра по разности давлений на его входе и выходе. Выдаёт токовый сигнал диапазона 4-20 мА, пропорциональный перепаду давления. Автоматически включает и отключает очистку фильтровальных элементов, управляя блоками регенерации (А-01, А-02 и т. д.). Экономит сжатый воздух, сигнализирует об авариях фильтра. |
|
|
Модульная система управления регенерацией А-05 обслуживает фильтры с числом электропневмоклапанов от 1 до 96. В состав системы входят управляющий контроллер А-05К, а также требуемое количество (от 1 до 24-х) блоков коммутации А-05Р4 – по 4 клапана на каждый блок. Соединение контроллера с блоками производится по 5-проводной неэкранированной линии связи. Запуск и остановка регенерации производятся в зависимости от степени запылённости фильтра. |
||
|
Контроллер А-05К |
Содержит встроенный датчик, измеряющий перепад давлений грязного и чистого воздуха. Автоматически запускает и останавливает процесс регенерации, управляя блоками коммутации. Выдаёт токовый сигнал диапазона 4-20 мА, пропорциональный перепаду давления. |
|
|
Блок А-05Р4 |
Может устанавливаться в непосредственной близости от ЭПК, например, под крышкой фильтра. Выдав импульсы встряхивания на 4 электропневмоклапана, подключает к линии связи следующий блок. Представляет собой «управляемую» распределительную клеммную коробку. |
|



2Р – Реле разности давлений
Цена: По запросу
Наличие на складе: Уточняйте
Для заказа или получения информации по продукции отправьте заявку:
Реле перепада давления РДД (дифференциальное реле давления, реле разности давлений) предназначены для коммутации электрических цепей в зависимости от изменения разности двух давлений неагрессивных к медным сплавам жидких и газообразных, не вязких и не кристаллизующихся сред с температурой до 110 °C (воздух, масло, вода, хладоны).
Принцип действия реле разности давлений состоит в сравнении двух давлений, подаваемых с двух сторон на сильфон, который деформируясь переключает одноплюсный перекидной контакт.
Основными параметрами дифференциального реле давления выступают диапазон измеряемой разности давления, фиксированный дифференциал, а также максимальное статическое давление на входе прибора.
Область применения реле перепада давления: теплоснабжение, водоснабжение, вентиляция, машиностроение. Идеально подходят для регулировки потери давления в фильтрах в технике кондиционирования и вентиляции.
Основные параметры
Дифференциальные реле давления
| Диапазон показаний, МПа | Дифференциал, МПа (фиксированный) |
|---|---|
| 0,05…0,2 | 0,03…0,05 |
| 0,05…0,4 | 0,06…0,2 |
| 0,1…0,6 | 0,06…0,2 |
Модификации РДД-2Р
| Обозначение | Диапазон | Резьба |
|---|---|---|
| РДД-2Р-0,2 МПа-G¼ | 0,05 … 0,2 МПа | G¼ |
| РДД-2Р-0,4 МПа-G¼ | 0,05 … 0,4 МПа | G¼ |
| РДД-2Р-0,6 МПа-G¼ | 0,1 … 0,6 МПа | G¼ |
Габариты РДД-2Р
Кронштейн дифференциального реле давления РДД-2Р:
Монтаж и эксплуатация РДД-2Р
Монтаж прибора выполняется на приборную панель или с помощью кронштейна.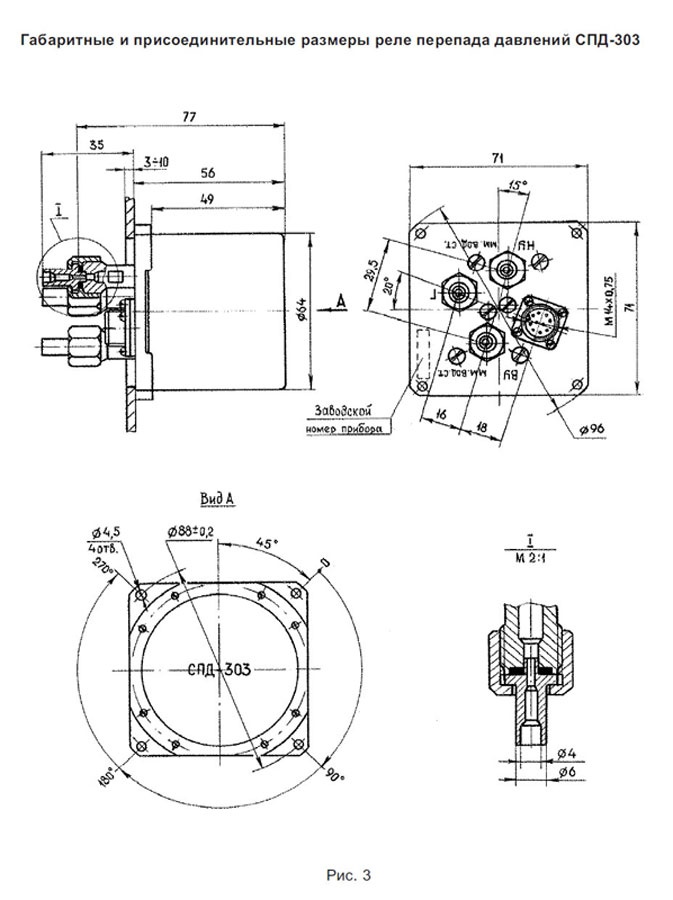 Капиллярная трубка присоединяется к штуцеру с помощью накидной гайки. Предварительно капиллярную трубку необходимо развальцевать. Электрический кабель подключается согласно схеме:
Капиллярная трубка присоединяется к штуцеру с помощью накидной гайки. Предварительно капиллярную трубку необходимо развальцевать. Электрический кабель подключается согласно схеме:
Схема подключения электрических контактов представлена также на внутренней стороне крышки изделия.
Техническое обслуживание в процессе эксплуатации заключается во внешнем осмотре крепления на ;объекте, в проверке заземления и перенастройке изделия по мере необходимости изменения режима работы агрегата и устранению дефектов.
Перенастройка диапазона производится путем вращения регулировочного колеса по часовой стрелке, если необходимо уменьшить уставку, и против часовой стрелки, если необходимо увеличить уставку.
МИКРОВОЛНОВЫЕ ДАТЧИКИ ПРОМЫШЛЕННОГО ПРИМЕНЕНИЯ – Журнал Горная промышленность
Д.Н.Шестаков, генеральный директор ООО «ПромРадар»
Ни одна система управления производством не может обойтись без источников первичной информации – датчиков состояния технологического оборудования. На смену кнопочно – релейным пультам приходят микропроцессорные АСУ ТП высочайшей производительности и надежности, датчики оснащаются цифровыми интерфейсами связи, однако это не всегда приводит к повышению общей надежности системы и достоверности ее работы. Причина заключается в том, что сами принципы действия большинства известных типов датчиков накладывают жесткие ограничения на условия, в которых они могут использоваться.
На смену кнопочно – релейным пультам приходят микропроцессорные АСУ ТП высочайшей производительности и надежности, датчики оснащаются цифровыми интерфейсами связи, однако это не всегда приводит к повышению общей надежности системы и достоверности ее работы. Причина заключается в том, что сами принципы действия большинства известных типов датчиков накладывают жесткие ограничения на условия, в которых они могут использоваться.
Основной задачей АСУ ТП является точное соблюдение технологии переработки сырья в готовую продукцию. Кроме непрерывного контроля за состоянием оборудования и предупреждения аварийных ситуаций, грамотно построенная система должна следить за перемещением продукта по всей цепочке перерабатывающих машин.
Технологические процессы, связанные с изменением химического состава сырья, смешиванием в потоке различных веществ, увлажнением и т. д. должны при пропадании одного из компонентов обеспечивать надежную отсечку остальных. Для контроля наличия потока продукта до сих пор используются подпружиненные поворотные пластины с микропереключателями. В процессе работы они подвергаются непрерывным ударным нагрузкам влажных и агрессивных сред, что, естественно, очень скоро приводит к «залипанию» контактов или механическому разрушению пластин.
В процессе работы они подвергаются непрерывным ударным нагрузкам влажных и агрессивных сред, что, естественно, очень скоро приводит к «залипанию» контактов или механическому разрушению пластин.
Таким образом, отсутствие надежных и недорогих датчиков для контроля состояния промышленных механизмов приводит к снижению эффективности систем управления производством, уменьшает отдачу от средств, вложенных в автоматизацию. Сложные и дорогостоящие АСУ ТП, привязанные к датчикам традиционных типов, являются лишь средством для удобного группового включения-выключения технологических цепочек и часто не способны улучшить качество продукции, экономить сырье и ресурсы.
Необходимость постоянного технического обслуживания и регулировок датчиков приводит к простоям – для очистки емкостного датчика от налипшего продукта следует разгрузить бункер, подготовить и установить лебедку для опускания в него человека, по окончании работ вновь отрегулировать прибор; для замены тахогенераторного или магнитоиндуктивного датчика скорости на нории необходима полная разборка ее башмака – все это обычно занимает несколько часов, снижая производительность предприятия в целом.
Указанные проблемы несколько лет назад привели к разработке принципиально новых типов приборов – радиолокационных датчиков контроля скорости, датчиков движения и подпора, работа которых основана на взаимодействии контролируемого объекта с радиосигналом частотой около 1010 Гц.
Использование микроволновых методов контроля за состоянием технологического оборудования позволяет полностью избавиться от недостатков датчиков традиционных типов. Более того, новые приборы успешно справляются с множеством нерешенных ранее проблем технологов, служб автоматизации и КИПиА.
Отличительными особенностями этих устройств являются:
• отсутствие механического и электрического контакта с объектом (средой), расстояние от датчика до объекта может составлять несколько метров;
• непосредственный контроль объекта (транспортерной ленты, цепи), а не их приводов, натяжных барабанов и т. д.;
• малое энергопотребление;
• нечувстствительность к налипанию продукта за счет больших рабочих расстояний;
• высокая помехоустойчивость и направленность действия;
• герметичное исполнение;
• разовая настройка на весь срок службы;
• высокая надежность, безопасность, отсутствие ионизирующих излучений.
На правой части схемы (рис. 1) приведен список микроволновых датчиков для промышленной автоматики, которые серийно производятся научно-производственной фирмой «ПромРадар», а слева – области применения этих приборов.
Устройство контроля скорости РДКС–01 (патент Российской Федерации №?2109305 от 20.04.98 г.) предназначено для слежения за скоростью движения или вращения различных промышленных установок – горизонтальных и наклонных ленточных транспортеров, норий, других механизмов. Задача прибора – сигнализировать об аварии или отключить механизм в случае выхода скорости его движения (вращения) за пределы установленного диапазона, предупреждая этим аварийную ситуацию.
Устройство состоит из первичного преобразователя РДКС-01ПП (рис.?2) и реле скорости РДКС-01РС (рис.?3), соединяемых между собой двухпроводной линией длиной до 300 метров.
Допплеровский приемо-передающий модуль первичного преобразователя через герметичный пластиковый корпус излучает радиосигнал на движущийся объект. В случае, показанном на рис.?2, таким объектом является лента вертикального ковшового транспортера (нории). Если лента движется, то на выходе модуля возникает переменное напряжение, частота которого прямо пропорциональна скорости движения. После предварительной обработки сигнал преобразуется в последовательность коротких токовых импульсов, не подверженных воздействию промышленных помех, и поступает в реле скорости. Оно обычно устанавливается в электрощитовом помещении вблизи пускателя и при выходе скорости механизма за пределы установленной зоны либо отключает его, либо сигнализирует об аварии.
В случае, показанном на рис.?2, таким объектом является лента вертикального ковшового транспортера (нории). Если лента движется, то на выходе модуля возникает переменное напряжение, частота которого прямо пропорциональна скорости движения. После предварительной обработки сигнал преобразуется в последовательность коротких токовых импульсов, не подверженных воздействию промышленных помех, и поступает в реле скорости. Оно обычно устанавливается в электрощитовом помещении вблизи пускателя и при выходе скорости механизма за пределы установленной зоны либо отключает его, либо сигнализирует об аварии.
Описанный выше принцип действия датчика РДКС-01 позволяет контролировать скорость любых объектов независимо от того, из какого материала они изготовлены. Поэтому прибор может применяться на таких машинах, как нории с закрытым башмаком, с пластиковыми ковшами, сдвоенные нории и т. п. Монтаж и подключение датчика не вызывают трудностей, так как, во-первых, связь между РДКС-01ПП и РДКС-01РС осуществляется по двум проводам, а во-вторых, первичный преобразователь может быть установлен в любом месте конвейера. Это позволяет использовать РДКС-01 вместо датчиков старых типов без прокладки дополнительных кабелей.
Это позволяет использовать РДКС-01 вместо датчиков старых типов без прокладки дополнительных кабелей.
Корпус первичного преобразователя имеет подтвержденную независимыми испытаниями степень защиты IP54, что позволяет использовать его во взрывоопасных помещениях категории ВIIА (разрешение Госгортехнадзора России № 02-35/470). Завершая обзор датчика РДКС-01, следует отметить, что при всех своих преимуществах он не дороже других отечественных промышленных устройств контроля скорости.
Датчики движения РДД-02 (рис. 4) и РДД-03 (рис. 5) позволяют системе управления «видеть» прохождение продукта через перерабатывающие машины, то есть контролировать весь ход технологического процесса от приема сырья до выпуска готовой продукции. Управляя отключением незагруженных механизмов, предотвращая попадание продукта в воздуховоды аспирационных сетей, датчики движения дают реальную экономию сырья и электроэнергии. Кроме этого, они могут быть использованы для контроля за движением шлюзовых затворов, цепных конвейеров, а также любых других электрических машин. Например, установка датчика движения на цепной конвейер позволит моментально остановить его при обрыве цепи, что избавит предприятие от затрат на ремонт и восстановление разрушенного механизма.
Например, установка датчика движения на цепной конвейер позволит моментально остановить его при обрыве цепи, что избавит предприятие от затрат на ремонт и восстановление разрушенного механизма.
Если «зависание» продукта внутри перерабатывающей машины способно привести к выходу ее из строя, то единственно возможная замена оператору у смотрового окна – установка датчика движения в ее выходящий продуктопровод.
Аналогично устройству контроля скорости РДКС-01, принцип действия датчиков движения основан на эффекте Допплера, то есть движущийся объект вызывает появление электрического сигнала на выходе микроволнового приемо-передающего модуля.
Сигнализатор движения РДД-02 подключается непосредственно к сети переменного тока напряжением 187–242?В, потребляя не более 2 ВА. Степень защиты корпуса РДД-02 – IP54.
Конструкция датчика РДД-03 позволяет устанавливать его на продуктопроводы диаметром от 50 мм. Выходным каскадом прибора является электронный ключ, защищенный от короткого замыкания в цепи нагрузки. Диапазон питающего напряжения (от 12 В постоянного до 220 В переменного тока) и нагрузочные характеристики ключа (от 50 до 500 мА, от 12 до 220 В переменного или постоянного тока) определяются требованиями заказчика. Внутреннее потребление самого датчика не превышает 5 мА, рабочее расстояние – до 30 см, степень защиты от воздействия пыли и воды – IP65.
Диапазон питающего напряжения (от 12 В постоянного до 220 В переменного тока) и нагрузочные характеристики ключа (от 50 до 500 мА, от 12 до 220 В переменного или постоянного тока) определяются требованиями заказчика. Внутреннее потребление самого датчика не превышает 5 мА, рабочее расстояние – до 30 см, степень защиты от воздействия пыли и воды – IP65.
В типовом исполнении приборы могут определять наличие движения в диапазоне скоростей от 0.1 до 25 м/с. Для очень быстрых объектов верхняя граница контролируемой скорости может быть расширена. Чувствительность датчиков регулируется в широких пределах, позволяя контролировать движение практически любых материалов – от металлических лопастей вентилятора до высушенных отходов деревообрабатывающего производства. В качестве примера на рис.?6 показан вариант установки сигнализатора РДД-02 на цепной транпортер.
Датчик монтируется на короб транспортера вблизи приводной станции. Рабочее расстояние сигнализатора ограничивается регулятором чувствительности так, чтобы датчик реагировал на движение ближней (верхней) ветки цепи. При обрыве цепи в любой точке она сразу провисает у приводной станции, выходя из зоны действия прибора.
При обрыве цепи в любой точке она сразу провисает у приводной станции, выходя из зоны действия прибора.
Аналогичным образом можно определять не только наличие или отсутствие механических перемещений, но и контролировать изменение расстояния от движущегося объекта до места установки датчика. Так как уровень сигнала зависит от свойств отражающего объекта, датчики движения могут использоваться для того, чтобы сигнализировать о наличии на конвейерной ленте каких-либо предметов или материалов. При необходимости заполнить какую-либо емкость (от бункера до шахты) можно точно определить момент окончания засыпки – опущенный на определенную глубину датчик будет показывать движение наполнителя до тех пор, пока не будет засыпан. Конкретные примеры использования микроволновых датчиков движения в различных отраслях промышленности определяются ее спецификой, но в целом они способны решать самые разнообразные задачи безаварийной эксплуатации оборудования и повысить информативность автоматизированных систем управления.
Принцип действия микроволновых сигнализаторов уровня заключается в ослаблении амплитуды радиосигнала при прохождении им слоя продукта (рис. 7).
На боковые стенки объекта по разным его сторонам устанавливаются генератор и детектор радиосигнала. Когда пространство между ними заполняется продуктом, амплитуда напряжения на выходе детектора резко падает, что приводит к срабатыванию датчика «на подпор». Налипание сырья на СВЧ-узлы не влияет на работу прибора – чувствительность датчика регулируется так, чтобы он срабатывал при полном перекрытии продуктом детекторного модуля.
Слой налипшего продукта в несколько сантиметров не является преградой для распространения радиолуча – прибор сработает, когда толщина слоя составит полную ширину бункера. По этой же причине датчик не реагирует на запыленность внутри объекта, нечувствителен к прикосновению продукта к рабочим поверхностям первичных преобразователей при заполнении и опорожнении бункера. Особенно ярко положительные свойства микроволновых сигнализаторов уровня проявляются в таких местах, где происходит обработка продуктов горячим воздухом или паром – именно там стенки бункера «зарастают» в первые минуты работы и любые другие приборы сразу становятся неработоспособными. Не влияют на датчик и перепады температуры – амплитуда сигнала генератора и чувствительность приемника практически постоянны в диапазоне от –40 до +40°С. Степень защиты выносных модулей от воздействия пыли и воды – не ниже IP65, а сигнализатора – IP54.
Не влияют на датчик и перепады температуры – амплитуда сигнала генератора и чувствительность приемника практически постоянны в диапазоне от –40 до +40°С. Степень защиты выносных модулей от воздействия пыли и воды – не ниже IP65, а сигнализатора – IP54.
В большинстве случаев микроволновые датчики способны заменить радиоактивные изотопные сигнализаторы уровня, эксплуатация которых требует немалых затрат из-за необходимости оплачивать периодические проверки контролирующим органам Атомнадзора. Такая замена не только избавляет предприятие от потенциально опасного оборудования, но и экономически выгодна – стоимость перехода на микроволновые датчики с учетом утилизации радиоизотопных, как правило, меньше, чем затраты на одну периодическую проверку. Микроволновые датчики уже несколько лет успешно работают на месте радиоизотопных с различными средами – от зерна до металлосодержащей руды.
Номенклатура сигнализаторов уровня позволяет использовать их для контроля подпора в различных объектах – самотеках и бункерах размером от 20 см до 8 м. Датчик РСУ-3, предназначенный для объектов небольшого размера, имеет только один выносной модуль – детектор, а генератор радиосигнала встроен в корпус сигнализатора. На рис. 8 показан вариант установки датчика на головку нории, а на рис. 9 – на бункер.
Датчик РСУ-3, предназначенный для объектов небольшого размера, имеет только один выносной модуль – детектор, а генератор радиосигнала встроен в корпус сигнализатора. На рис. 8 показан вариант установки датчика на головку нории, а на рис. 9 – на бункер.
Полностью проконтролировать процесс прохождения продуктом материалопровода позволяет датчик РДДП-01. Он независимо различает движение потока продукта и подпор. Таким образом, прибор индицирует все возможные процессы, происходящие внутри – нет продукта, продукт движется или уже заполнил объект. С помощью выходных сигналов датчика можно добиться, например, постоянного наличия в продуктопроводе потока сырья, включая разгрузку в случае подпора и подачу при отсутствии продукта. Сигнал о движении потока будет сигнализировать о нормальном ходе технологического процесса.
Принцип действия микроволнового датчика движения и подпора иллюстрирует рис. 10. Внутри корпуса сигнализатора установлен допплеровский приемо-передающий модуль.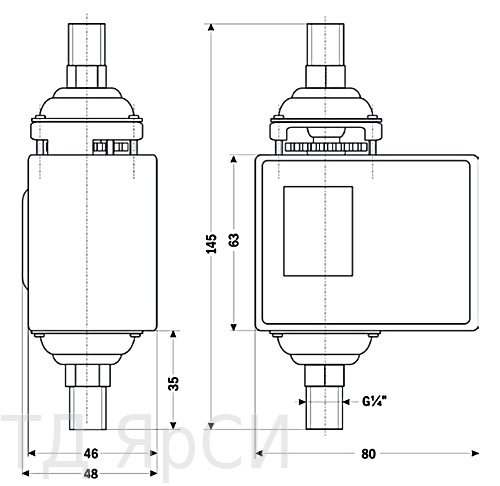 При движении продукта частота отраженного радиосигнала отличается от излученной. Разность частот приводит с срабатыванию канала контроля движения. Часть сигнала проходит сквозь поток и поступает в выносной детектор. Когда объект будет заполнен продуктом, амплитуда напряжения в приемнике упадет, вызывая срабатывание канала контроля подпора. С помощью датчика РДДП-01 возможен контроль объектов размером до 1.5 метров. На рис. 11 показан пример установки датчика на самотек.
При движении продукта частота отраженного радиосигнала отличается от излученной. Разность частот приводит с срабатыванию канала контроля движения. Часть сигнала проходит сквозь поток и поступает в выносной детектор. Когда объект будет заполнен продуктом, амплитуда напряжения в приемнике упадет, вызывая срабатывание канала контроля подпора. С помощью датчика РДДП-01 возможен контроль объектов размером до 1.5 метров. На рис. 11 показан пример установки датчика на самотек.
Микроволновые устройства контроля скорости, датчики движения и сигнализаторы уровня в течение нескольких лет успешно эксплуатируются на сотнях предприятиях различных отраслей. Они имеют несомненные преимущества над другими типами промышленных датчиков, что позволяет повысить безопасность технологических процессов, снизить износ оборудования, расширить функциональные возможности автоматизированных систем управления производством, существенно экономить материальные и энергетические ресурсы.
Производитель микроволновых датчиков промышленного применения научно-производственная фирма «ПромРадар».
Журнал “Горная Промышленность” №4 2001
Как преобразовать dataframe в RDD и сохранить его в cassandra с помощью spark scala
Как преобразовать dataframe в RDD и сохранить его в Cassandra в Spark Scala. Рассмотрим пример, как показано ниже,
emp_id| emp_city|emp_name
1|Hyderabad| ram
4| Banglore| deeksha
Здесь я использую только 3 столбца в качестве примера, но на самом деле мне нужно иметь дело с 18 столбцами.
scala apache-spark cassandraПоделиться Источник shantha ramadurga 20 августа 2018 в 01:36
1 ответ
- Как конвертировать RDD в DataFrame в потоковом режиме Spark, а не только Spark
Как я могу преобразовать RDD в DataFrame в Spark Streaming , а не только в Spark ? Я видел этот пример, но для него требуется SparkContext . val sqlContext = new SQLContext(sc) import sqlContext.
 implicits._ rdd.toDF() В моем случае у меня есть StreamingContext . Должен ли я тогда создать…
implicits._ rdd.toDF() В моем случае у меня есть StreamingContext . Должен ли я тогда создать… - Scala Spark фильтр RDD использование Cassandra
Я новичок в spark-Cassandra и Scala. У меня есть существующий RDD. Пусть говорят: ((url_hash, url, created_timestamp )). Я хочу отфильтровать этот RDD на основе url_hash. Если url_hash существует в таблице Cassandra, то я хочу отфильтровать его из таблицы RDD, чтобы я мог обрабатывать только новые…
1
Вы можете непосредственно сохранить DF без преобразования в RDD.
df.write.format("org.apache.spark.sql.cassandra").options(Map( "table" -> "employee", "keyspace" -> "emp_data")).save()
Спасибо.
Поделиться Learner 20 августа 2018 в 03:46
Похожие вопросы:
Сохранение данных с Spark по Cassandra приводит к java.
 lang.ClassCastException
lang.ClassCastExceptionЯ пытаюсь сохранить данные с Spark по Cassandra в Scala, используя saveToCassandra для RDD или сохранить с dataframe (оба результата приводят к одной и той же ошибке). Полное сообщение:…
Запись PairDStram в cassandra с помощью соединителя Datastax Spark Cassandra
Мне нужно записать данные моего отфильтрованного потока в cassandra, используя разъем Java и Datastax Spark Cassandra. Я следовал документации datastax java . Документация объясняет, как написать…
Как найти размер spark RDD/Dataframe?
Я знаю, как найти размер файла в scala. Но как найти размер RDD/dataframe в spark? Scala: object Main extends App { val file = new java.io.File(hdfs://localhost:9000/samplefile.txt).toString()…
Как конвертировать RDD в DataFrame в потоковом режиме Spark, а не только Spark
Как я могу преобразовать RDD в DataFrame в Spark Streaming , а не только в Spark ? Я видел этот пример, но для него требуется SparkContext . val sqlContext = new SQLContext(sc) import…
val sqlContext = new SQLContext(sc) import…
Scala Spark фильтр RDD использование Cassandra
Я новичок в spark-Cassandra и Scala. У меня есть существующий RDD. Пусть говорят: ((url_hash, url, created_timestamp )). Я хочу отфильтровать этот RDD на основе url_hash. Если url_hash существует в…
Как преобразовать RDD[CassandraRow] в DataFrame?
В настоящее время именно так я трансформирую Cassandrarow RDD в dataframe: val ssc = new StreamingContext(sc, Seconds(15)) val dstream = new ConstantInputDStream(ssc, ssc.cassandraTable(db,…
Как преобразовать RDD[GenericRecord] в dataframe в scala?
Я получаю твиты из темы Кафки с помощью Avro (сериализатор и десериализатор). Затем я создаю потребитель spark, который извлекает твиты в Dstream из RDD[GenericRecord]. Теперь я хочу преобразовать…
Как преобразовать rdd из pandas DataFrame в Spark DataFrame
Я создаю rdd pandas DataFrame в качестве промежуточного результата. Я хочу преобразовать Spark DataFrame, в конечном итоге сохранить его в файл parquet. Я хочу знать, каков самый эффективный способ….
Я хочу преобразовать Spark DataFrame, в конечном итоге сохранить его в файл parquet. Я хочу знать, каков самый эффективный способ….
Spark RDD присоединиться к таблице Cassandra
Я присоединяюсь к Spark RDD с Cassandra table (поиск), но не могу понять несколько вещей. Будет ли spark вытягивать все записи между range_start и range_end из Cassandra table , а затем соединять их…
Spark RDD напишите в Cassandra
У меня есть схема таблицы ниже Cassandra. ColumnA Primary Key ColumnB Clustering Key ColumnC ColumnD Теперь у меня есть Spark RDD со столбцами, упорядоченными как RDD[ColumnC, ColumnA, ColumnB,…
Нет Filesystem Для Схемы: Cos
Я пытаюсь подключиться к IBM Cloud Object Storage из IBM Data Science Experience:
access_key = 'XXX'
secret_key = 'XXX'
bucket = 'mybucket'
host = 'lon.ibmselect.objstor.com'
service = 'mycos'
sqlCxt = SQLContext(sc)
hconf = sc. _jsc.hadoopConfiguration()
_jsc.hadoopConfiguration()
hconf.set('fs.cos.myCos.access.key', access_key)
hconf.set('fs.cos.myCos.endpoint', 'http://' + host)
hconf.set('fs.cose.myCos.secret.key', secret_key)
hconf.set('fs.cos.service.v2.signer.type', 'false')
obj = 'mydata.tsv.gz'
rdd = sc.textFile('cos://{0}.{1}/{2}'.format(bucket, service, obj))
print(rdd.count())
Это возвращает:
Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: java.io.IOException: No FileSystem for scheme: cos
Я предполагаю, что мне нужно использовать схему “cos”, основанную на документах стокатора. Однако ошибка говорит о том, что стокатор недоступен или является старой версией?
Есть идеи?
Обновление 1:
Я также пробовал следующее:
sqlCxt = SQLContext(sc)
hconf = sc._jsc.hadoopConfiguration()
hconf.set('fs.cos.impl', 'com.ibm. stocator.fs.ObjectStoreFileSystem')
stocator.fs.ObjectStoreFileSystem')
hconf.set('fs.stocator.scheme.list', 'cos')
hconf.set('fs.stocator.cos.impl', 'com.ibm.stocator.fs.cos.COSAPIClient')
hconf.set('fs.stocator.cos.scheme', 'cos')
hconf.set('fs.cos.mycos.access.key', access_key)
hconf.set('fs.cos.mycos.endpoint', 'http://' + host)
hconf.set('fs.cos.mycos.secret.key', secret_key)
hconf.set('fs.cos.service.v2.signer.type', 'false')
service = 'mycos'
obj = 'mydata.tsv.gz'
rdd = sc.textFile('cos://{0}.{1}/{2}'.format(bucket, service, obj))
print(rdd.count())
Однако на этот раз ответ был:
Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: java.io.IOException: No object store for: cos
at com.ibm.stocator.fs.ObjectStoreVisitor.getStoreClient(ObjectStoreVisitor.java:121)
...
Caused by: java.lang.ClassNotFoundException: com.ibm.stocator.fs.cos.COSAPIClient
– Документация Spark 3.
 0.0-превью
0.0-превьюApache Spark предоставляет набор веб-интерфейсов пользователя (UI), которые вы можете использовать для отслеживания состояния и потребления ресурсов кластера Spark.
Содержание
Вкладка “Задания”
На вкладке «Задания» отображается сводная страница всех заданий в приложении Spark и страница сведений. для каждой работы. На сводной странице отображается высокоуровневая информация, такая как статус, продолжительность и ход выполнения всех работ и общий график событий.Когда вы нажимаете на вакансию в сводке , вы увидите страницу с подробными сведениями об этой вакансии. На странице сведений также отображается временная шкала события, Визуализация DAG и все этапы работы.
В этом разделе отображается информация
.- Пользователь: текущий пользователь Spark
- Общее время безотказной работы: время с момента запуска приложения Spark
- Режим планирования: см.
 Планирование заданий
Планирование заданий - Количество заданий в каждом статусе: Активно, Завершено, Неудачно
- Временная шкала событий: отображает в хронологическом порядке события, связанные с исполнителями (добавлены, удалены) и заданиями.
- Подробная информация о заданиях, сгруппированных по статусу: отображает подробную информацию о заданиях, включая идентификатор задания, описание (со ссылкой на страницу с подробными сведениями о задании), время отправки, длительность, сводку этапов и индикатор выполнения задания
Если щелкнуть конкретное задание, можно просмотреть подробную информацию об этом задании.
Сведения о вакансиях
На этой странице отображаются сведения о конкретном задании, идентифицированном по его идентификатору.
- Статус задания: (выполняется, успешно, не удалось)
- Количество этапов в статусе (активный, ожидающий, завершенный, пропущенный, неудачный)
- Связанный запрос SQL: ссылка на вкладку sql для этого задания
- Временная шкала событий: отображает в хронологическом порядке события, связанные с исполнителями (добавлены, удалены) и этапами задания.

- Визуализация DAG: Визуальное представление направленного ациклического графа этого задания, где вершины представляют RDD или DataFrames, а края представляют собой операцию, которая должна применяться к RDD.
- Список этапов (сгруппированных по состоянию: активный, ожидающий, завершенный, пропущенный и неудачный)
- ID этапа
- Описание сцены
- Временная метка отправлена
- Продолжительность этапа
- Индикатор выполнения задач
- Ввод: байты прочитаны из хранилища на этом этапе
- Вывод: байты записаны в память на этом этапе
- Произвольное чтение: общее количество прочитанных байтов и записей в случайном порядке, включая данные, считанные локально, и данные, считанные от удаленных исполнителей
- Запись в случайном порядке: байты и записи, записываемые на диск, чтобы их можно было прочитать путем перемешивания на следующем этапе.
Вкладка этапов
На вкладке «Этапы» отображается сводная страница, на которой показано текущее состояние всех этапов всех заданий в приложение Spark.
В начале страницы находится сводка с подсчетом всех этапов по статусу (активный, ожидающий, завершенный, принятый и неудачный)
В режиме справедливого планирования есть таблица, в которой отображаются свойства пулов
После этого приводится подробная информация об этапах по статусу (активный, ожидающий, завершенный, пропущенный, неудачный). На активных этапах можно убить этап с помощью ссылки для уничтожения. Причина отказа отображается только на неудачных этапах.Подробную информацию о задаче можно получить, щелкнув описание.
Деталь сцены
Страница сведений об этапе начинается с такой информации, как общее время выполнения всех задач, сводка на уровне местоположения, размер чтения / записи в случайном порядке и идентификаторы связанных заданий.
Существует также визуальное представление направленного ациклического графа (DAG) этого этапа, где вершины представляют RDD или DataFrames, а края представляют операцию, которую нужно применить.
Сводные показатели для всех задач представлены в таблице и на временной шкале.
- Время десериализации задач
- Продолжительность задач .
- Время сборки мусора – это общее время сборки мусора JVM.
- Время сериализации результата – это время, потраченное на сериализацию результата задачи на исполнителе перед его отправкой обратно драйверу.
- Время получения результата – это время, которое драйвер тратит на получение результатов задачи от работников.
- Задержка планировщика – это время, в течение которого задача ожидает запланированного выполнения.
- Пиковая память выполнения – это максимальная память, используемая внутренними структурами данных, созданными во время тасования, агрегирования и объединения.
- Произвольный размер чтения / записей . Общее количество прочитанных байтов в случайном порядке включает как данные, считанные локально, так и данные, считанные удаленными исполнителями.
- Время блокировки чтения в случайном порядке – это время, в течение которого задачи были заблокированы в ожидании чтения данных в случайном порядке с удаленных компьютеров.
- Удаленное чтение в случайном порядке – это общее количество байтов в случайном порядке, прочитанное из удаленных исполнителей.
- Shuffle spill (memory) – это размер десериализованной формы перемешанных данных в памяти.
- Shuffle spill (disk) – это размер сериализованной формы данных на диске.
Агрегированные метрики по исполнителям показывают ту же информацию, агрегированную по исполнителям.
Аккумуляторы – это тип общих переменных. Он предоставляет изменяемую переменную, которую можно обновлять внутри множества преобразований.Можно создавать аккумуляторы с именем и без имени, но отображаются только аккумуляторы с именем.
Подробная информация о задачах в основном включает ту же информацию, что и в сводном разделе, но детализирована по задачам. Он также включает ссылки для просмотра журналов и номер попытки задачи, если она не удалась по какой-либо причине. Если есть именованные аккумуляторы, здесь можно увидеть значение аккумулятора в конце каждой задачи.
Вкладка для хранения
На вкладке «Хранилище» отображаются сохраненные RDD и DataFrames, если таковые имеются, в приложении.Резюме на странице показаны уровни хранения, размеры и разделы всех RDD, а на странице сведений показаны размеры и использование исполнителей для всех разделов в RDD или DataFrame.
scala> импорт org.apache.spark.storage.StorageLevel._
import org.apache.spark.storage.StorageLevel._
scala> val rdd = sc.range (0, 100, 1, 5) .setName ("rdd")
rdd: org.apache.spark.rdd.RDD [Long] = rdd MapPartitionsRDD [1] в диапазоне на <консоли>: 27
scala> rdd.persist (MEMORY_ONLY_SER)
res0: rdd.type = rdd MapPartitionsRDD [1] в диапазоне на : 27
scala> rdd.count
res1: Long = 100
scala> val df = Seq ((1, «Энди»), (2, «bob»), (2, «Энди»)). toDF («количество», «имя»)
df: org.apache.spark.sql.DataFrame = [количество: число, имя: строка]
scala> df.persist (DISK_ONLY)
res2: df.type = [количество: число, имя: строка]
scala> df.count
res3: Длинный = 3 После выполнения приведенного выше примера мы можем найти два RDD, перечисленных на вкладке Storage.Основная информация, такая как указаны уровень хранения, количество разделов и накладные расходы на память. Обратите внимание, что недавно сохраненные RDD или DataFrames не отображаются на вкладке до их материализации. Чтобы отслеживать конкретный RDD или DataFrame, убедитесь, что операция действия была запущена.
Вы можете щелкнуть имя RDD «rdd», чтобы получить подробную информацию о сохранении данных, например, данные распределение по кластеру.
Вкладка среды
На вкладке Environment отображаются значения различных переменных среды и конфигурации, включая JVM, Spark и системные свойства.
Эта страница среды состоит из пяти частей. Это полезное место, чтобы проверить, есть ли в вашей собственности был установлен правильно. Первая часть «Информация о времени выполнения» просто содержит свойства времени выполнения. как версии Java и Scala. Во второй части «Spark Properties» перечислены такие свойства приложения, как «Spark.app.name» и «spark.driver.memory».
При нажатии ссылки «Свойства Hadoop» отображаются свойства, относящиеся к Hadoop и YARN. Обратите внимание, что такие свойства, как ‘Искра.hadoop. * »показаны не в этой части, а в« Spark Properties ».
«Свойства системы» показывает более подробную информацию о JVM.
В последней части «Classpath Entries» перечислены классы, загруженные из разных источников, что очень полезно. для разрешения классовых конфликтов.
Вкладка “Исполнители”
На вкладке «Исполнители» отображается сводная информация об исполнителях, созданных для приложение, включая использование памяти и диска, а также информацию о задачах и перемешивании.Память для хранения В столбце отображается объем памяти, используемой и зарезервированной для кэширования данных.
Вкладка Executors предоставляет не только информацию о ресурсах (объем памяти, диска и ядер, используемых каждым исполнителем). но также информацию о производительности (время сборки мусора и информацию о перемешивании).
При нажатии на ссылку «stderr» исполнителя 0 отображается подробный стандартный журнал ошибок. в его консоли.
При нажатии на ссылку «Thread Dump» исполнителя 0 отображается дамп потока JVM для исполнителя 0, что очень полезно. для анализа производительности.
Вкладка SQL
Если приложение выполняет запросы Spark SQL, на вкладке SQL отображается такая информация, как продолжительность, рабочие места, а также физические и логические планы запросов. Здесь мы включаем базовый пример, чтобы проиллюстрировать эта вкладка:
scala> val df = Seq ((1, «энди»), (2, «боб»), (2, «энди»)). ToDF («количество», «имя»)
df: org.apache.spark.sql.DataFrame = [количество: число, имя: строка]
scala> df.count
res0: Long = 3
scala> df.createGlobalTempView ("df")
scala> spark.sql ("выберите имя, сумму (количество) из группы global_temp.df по имени"). show
+ ---- + ---------- +
| имя | сумма (количество) |
+ ---- + ---------- +
| Энди | 3 |
| боб | 2 |
+ ---- + ---------- + Теперь в списке показаны три вышеуказанных оператора dataframe / SQL. Если мы щелкнем по
‘Показать на
Мы видим подробную информацию о каждом этапе.Первый блок «WholeStageCodegen»
компилирует несколько операторов («LocalTableScan» и «HashAggregate») вместе в одну Java.
функция для повышения производительности, а такие показатели, как количество строк и размер разлива, перечислены в
блок. Второй блок «Обмен» показывает показатели по обмену в случайном порядке, в том числе
количество записанных записей в случайном порядке, общий размер данных и т. д.
При нажатии на ссылку «Подробности» внизу отображаются логические планы и физический план, которые проиллюстрировать, как Spark анализирует, анализирует, оптимизирует и выполняет запрос.
Метрики SQL
Метрики операторов SQL показаны в блоке физических операторов. Метрики SQL могут быть полезны когда мы хотим погрузиться в детали выполнения каждого оператора. Например, «количество строк вывода» может ответить, сколько строк выводится после оператора Filter, «перемешать количество записанных байтов» в Exchange показывает количество байтов, записанных в случайном порядке.
Вот список метрик SQL:
| Метрики SQL | Значение | Операторы | |
|---|---|---|---|
количество строк вывода | количество строк вывода оператора | Агрегатные операторы, операторы соединения, выборка, диапазон, операторы сканирования, фильтр и т. Д. | |
размер данных | размер широковещательных / перетасованных / собранных данных оператора | BroadcastExchange, ShuffleExchange, подзапрос | |
время для сбора | время, затраченное на сбор данных | Подзапрос | |
время сканирования | время, потраченное на сканирование данных | ColumnarBatchScan, FileSourceScan | |
время метаданных | время, потраченное на получение метаданных, таких как количество файлов 9027, 9027 файлов, 9027 разделов, 9027 файлов, 9027 разделов4 | ||
перемешать записанные байты | количество записанных байтов | CollectLimit, TakeOrderedAndProject, ShuffleExchange | |
перемешать записи в случайном порядке записано | |||
время записи в случайном порядке | время, затраченное на запись в случайном порядке | CollectLimit, TakeOrderedAndProject, ShuffleExchange | |
| чтение удаленных блоков, чтение удаленных блоков | ShuffleExchange|||
удаленных байтов, прочитанных | количество байтов, прочитанных удаленно | CollectLimit, TakeOrderedAndProject, ShuffleExchange | |
удаленных байтов, прочитанных удаленно с локального диска | CollectLimit, TakeOrderedAndProject, ShuffleExchange | ||
чтение локальных блоков | количество блоков, прочитанных локально | CollectLimit, TakeOrderedAndProject, ShuffleExchange | |
| локально | количество байтов, прочитанных локально | CollectLimit, TakeOrderedAndProject, ShuffleExchange | |
время ожидания выборки | время, потраченное на выборку данных (локальных и удаленных) | количество прочитанных записей | CollectLimit, TakeOrderedAndProject, ShuffleExchange |
время сортировки | время, затраченное на сортировку | Сортировка | |
пиковое использование памяти | |||
размер разлива | количество байтов, разлитых на диск из памяти в операторе | Sort, HashAggregate | |
время, затраченное на сборку агрегации | |||
Ср. количество итераций списка сегментов хеширования | среднее количество итераций в списке сегментов на поиск во время агрегации | HashAggregate | |
| Размер встроенных данных | |||
| размер встроенных данных | map | ShuffledHashJoin | |
время для построения хэш-карты | время, потраченное на построение хэш-карты | ShuffledHashJoin |
Streaming Tab
Веб-интерфейс включает вкладку «Потоковая передача», если приложение использует потоковую передачу Spark.На этой вкладке отображается планирование задержки и времени обработки для каждого микропакета в потоке данных, что может быть полезно для устранения неполадок в потоковом приложении.
Вкладка сервера JDBC / ODBC
Мы видим эту вкладку, когда Spark работает как распределенный механизм SQL. Он показывает информацию о сеансах и отправленных операциях SQL.
В первом разделе страницы отображается общая информация о сервере JDBC / ODBC: время запуска и время безотказной работы.
Второй раздел содержит информацию об активных и завершенных сессиях.
- Пользователь и IP подключения.
- Идентификатор сеанса ссылка для доступа к информации о сеансе.
- Время начала , время окончания и продолжительность сеанса.
- Всего выполнения - это количество операций, отправленных в этом сеансе.
В третьем разделе находится SQL-статистика отправленных операций.
- Пользователь , выполняющий операцию.
- Job id ссылка на вкладку вакансий.
- Идентификатор группы запроса, объединяющего все задания. Приложение может отменить все запущенные задания, используя этот идентификатор группы.
- Время начала операции.
- Время окончания выполнения до получения результатов.
- Время закрытия операции после получения результатов.
- Время выполнения - это разница между временем окончания и временем начала.
- Продолжительность - это разница между временем закрытия и временем начала.
- Оператор - это выполняемая операция.
- Состояние процесса.
- Запущено , первое состояние, когда начинается процесс.
- Составлено , план выполнения сформирован.
- Failed , конечное состояние, когда выполнение не удалось или завершилось с ошибкой.
- Отменено , конечное состояние при отмене выполнения.
- Обработка завершена и ожидает получения результатов.
- Closed , конечное состояние, когда клиент закрыл оператор.
- Деталь плана выполнения с проанализированным логическим планом, проанализированным логическим планом, оптимизированным логическим планом и физическим планом или ошибками в операторе SQL.
внутренних электрических схем - помощь в установке.
Схемы внутренней проводки
В этом разделе собраны схемы внутренней проводки, которые помогут при установке или устранении неисправностей вашего обогревателя.
Как пользоваться этим руководством
Для просмотра схемы внутренней проводки для вашей модели обогревателя выберите суффикс управления, соответствующий вашему обогревателю, щелкнув ссылку в столбце Модель в таблице ниже.
| НАГРЕВАТЕЛИ ВЫСОКОЙ ИНТЕНСИВНОСТИ RE-VERBER-RAY | ||||
|---|---|---|---|---|
| Модель (управляющий суффикс) | Напряжение | Система зажигания | Период производства | |
| 1 | НФС-2 / ПФС-2 | 25 В | Прямая искра | 01/05 - Настоящее время |
| 2 | НФС-2 / ПФС-2 | 25 В | Прямая искра | 1984 - 01/05 |
| 3 | НФС-2 / ПФС-2 | 120 В | Прямая искра | 03/97 - Настоящее время |
| 4 | НФС-2 / ПФС-2 | 120 В | Прямая искра | 1985 - 05/97 |
| 5 | НМВ-2 / ПМВ-2 | МВ | Милливольт | 1978 - настоящее время |
| 6 | НСПИ-8 | 25 В | Пилот искры | 1979-1999 |
| 7 | НСПИ-8 | 120 В | Пилот искры | 1979-1999 |
| 8 | НТ-2 / ПТ-2 | 25 В | Ручное зажигание | 1978-1998 |
| 9 | НТ-2 / ПТ-2 | 120 В | Ручное зажигание | 1978-1998 |
| 10 | NE-2 | 25 В | Катушка накаливания | 1976-1997 |
| 11 | NE-2 | 120 В | Катушка накаливания | 1976-1997 |
| 12 | NGCI-3 | 25 В | Катушка накаливания | 1988-1996 |
| 13 | NGCI-3 | 120 В | Катушка накаливания | 1988-1996 |
| 14 | НСП-4 | 25 В | Пилот искры | 1976-1993 |
| 15 | НСП-4 | 120 В | Пилот искры | 1976-1993 |
| 16 | NFS / PFS | 120 В | Прямая искра | 1976-1983 |
| 17 | Все прочие | 25 В | любой | |
| 18 | Все прочие | 120 В | любой | |
| НАГРЕВАТЕЛИ НИЗКОЙ ИНТЕНСИВНОСТИ RE-VERBER-RAY (в разработке) | ||||
|---|---|---|---|---|
| Серия | МБХ | Версия | Период производства | |
| 1 | DTH | 40-100 | НЕТ | 11/86 и приор |
| 2 | DTHS | 40-100 | НЕТ | 1984 и Prior |
| 3 | DTHS | 40-100 | НЕТ | 1985 по 11/86 |
| 4 | DTH (S) -2 | 40-100 | НЕТ | с 11/86 по 01/87 |
| 5 | DTH (S) -2 | 40-100 | НЕТ | 01/87 по 04/92 |
| 6 | DTH (S) -2 | 40-100 | НЕТ | с 04/92 по 01.01 |
| 7 | DTH (S) -2 | 125, 150 | НЕТ | с 1988 по 1989 год |
| 8 | DTH (S) -3 | 125 | НЕТ | с 1989 по 1994 год |
| 9 | DTH (S) -3 | 150 | НЕТ | 1990 по 1994 |
| 10 | DBS | Все | НЕТ | с 01/94 по 09/01 |
| 11 | ДРВ | Все | НЕТ | 01/91 - 12/01 |
| 12 | HL | Все | Нет стержня пламени | 01/94 - 05/04/95 |
| 13 | HL | Все | Пламенный стержень с прямым датчиком | 05.04.95 - 09.95 |
| 14 | HL | Все | Датчик пламени с дистанционным датчиком | 09/95 по 09/00 |
| 15 | HL-2 | Все | 09-00 | 09/00 - 08/02 |
| 16 | HL-2 | Все | 08-02 | с 08/02 по 06/03 |
| 17 | HL2 | Все | 06-03 | с 06.03 по 05.05 |
| 18 | HL2 | Все | 05-05 | 05/05 по настоящее время |
| 19 | HL3 | Все | 07-08 | 08.07 - 12.09 |
| 20 | HL3 | Все | 10–12 | 12.10 по настоящее время |
| 21 | DX | Все | Нет стержня пламени | 01/93 по 05/04/95 |
| 22 | DX | Все | Стержень пламени с прямым датчиком | 05.04.95 - 09.95 |
| 23 | DX | Все | Датчик пламени с дистанционным датчиком | с 09/95 по 08/00 |
| 24 | DX-2 | Все | 09-00 | 09/00 - 05/03 |
| 25 | DX2 | Все | 06-03 | с 06.03 по 14.08 |
| 26 | DX2 | Все | 05-05 | 14.09 по настоящее время |
| 27 | DX3 | Все | 07-08 | с 07.08 по 09.12 |
| 28 | DX3 | Все | 10–12 | 12.10 по настоящее время |
| 29 | XTS | Все | 05-00 | с 08/99 по 05/03 |
| 30 | XTS | Все | 06-03 | с 06.03 по 04.05 |
| 31 | XTS | Все | 05-05 | 05.05 - 04.08 |
| 32 | XTS3 | Все | 07-07 | с 07.07 по 07.12 |
| 33 | DET | Все | 06-03 | с 06.03 по 04.05 |
| 34 | DET | Все | 05-05 | 05.05 - 07.06 |
| 35 | DET3 | Все | 08-06 | с 08.06 по 06.09 |
| 36 | DET3 | Все | 07-09 | с 07.09 по 09.12 |
| 37 | DET3 | Все | 10–12 | 12.10 по настоящее время |
| 38 | DES | Все | 05-00 | 05/00 по 06/03 |
| 39 | DES | Все | 06-03 | с 06.03 по 04.05 |
| 40 | DES | Все | 05-05 | 05.05 - 07.06 |
| 41 | DES3 | Все | 05-06 | с 05.06 по 06.09 |
| 42 | DES3 | Все | 07-09 | с 07.09 по 9.12 |
| 43 | DES3 | Все | 10–12 | 12.10 по настоящее время |
| 44 | LS | Все | 06-00 | 06/00 к 2012 |
| 45 | LS | Все | 12-14 | с 2012 по 2014 год |
| 46 | LS3 | Все | 12-16 | с 2013 по 2016 год |
| 47 | LS3 | Все | 16-17 | 2016 г. по настоящее время |
| 48 | LD | Все | 06-00 | 06/00 к 2012 |
| 49 | LD | Все | 12-14 | с 2012 по 2014 год |
| 50 | LD3 | Все | 13-16 | с 2016 по 2016 год |
| 51 | LD3 | Все | 11-16 | 2016 г. по настоящее время |
| 52 | SV | Все | 06-00 | 06/00 по 04/05 |
| 53 | SV | Все | 05-05 | 05/05 по настоящее время |
| 54 | HLV | Все | 11-01 | 01.11–05 |
| 55 | HLV | Все | 05-05 | 05/05 по настоящее время |
| 56 | QTD | Все | 03-10 | с 10 марта по 16 августа |
| 57 | QTD2 | Все | 09-16 | 16.09 по настоящее время |
| 58 | QTS | Все | 03-10 | с 10 марта по 16 августа |
| 59 | QTS2 | Все | 09-16 | 16.09 по настоящее время |
| 60 | класс | Все | 09-04 | с 09.04 по 07.06 |
| 61 | класс | Все | 08-06 | с 08.06 по 15.06 |
| 62 | CX | Все | 09-04 | с 09.04 по 06.07 |
| 63 | CX | Все | 07-07 | 07.07 - 15.06 |
| 64 | RVA | Все | 01-94 | с 01/94 по 10/00 |
| 65 | РВА-2 | Все | 10-00 | с 10/00 по 06/03 |
| 66 | RVA2 | Все | 06-03 | с 06.03 по 04.05 |
| 67 | RVA2 | Все | 05-05 | 05.05 по 2014 |
| 68 | RVA2 | Все | 09-14 | 14.09 по настоящее время |
| 69 | AG-1 | Все | 01-01 | 01.01 - 03.06 |
| 70 | AG1 | Все | 06-03 | с 06.03 по 04.05 |
| 71 | AG1 | Все | 05-05 | 05/05 по настоящее время |
| 72 | AG-2 | Все | 01-01 | 01.01 - 05.03 |
| 73 | AG2 | Все | 06-03 | с 06.03 по 04.05 |
| 74 | AG2 | Все | 05-05 | 05.05 - 07.06 |
| 75 | AG2 | Все | 08-06 | с 08.06 по 09.08 |
| 76 | AG2 | Все | 10-08 | 10/08 по настоящее время |
| 77 | AVD | Все | 03-10 | с 10 марта по 16 августа |
| 78 | AVD2 | Все | 09-16 | 16.09 по настоящее время |
| 79 | AVS | Все | 03-10 | с 10 марта по 16 августа |
| 80 | AVS2 | Все | 09-16 | 16.09 по настоящее время |
| 81 | RH | Все | 07-01 | с 01.07 по 04.05 |
| 82 | RH | Все | 05-05 | 05/05 по настоящее время |
| 83 | MP | Все | 10-11 | 10/11 по настоящее время |
Искра 3.0 - Адаптивное выполнение запроса с примером - SparkByExamples
Adaptive Query Execution (AQE) - одна из важнейших функций Spark 3.0, которая повторно оптимизирует и корректирует планы запросов на основе статистики времени выполнения, собранной во время выполнения запроса.
В этой статье я объясню, что такое адаптивное выполнение запросов, почему оно стало таким популярным, и посмотрю, как оно улучшает производительность на примерах Scala и PySpark.
Как выполняется запрос до Spark 3.0
До версии 3.0, Spark выполняет однопроходную оптимизацию , создавая план выполнения (набор правил) до начала выполнения запроса, после запуска выполнения он придерживается плана и начинает выполнять правила, созданные в плане, и не выполняет не проводите никакой дальнейшей оптимизации, основанной на метриках, которые он собирает на каждом этапе.
Когда мы отправляем запрос, DataFrame или операции с набором данных, Spark выполняет следующие действия по порядку.
Источник: Databricks- Сначала Spark анализирует запрос и создает неразрешенный логический план
- Проверяет синтаксис запроса.
- Не проверяет семантику, означающую наличие имени столбца, типов данных.
- Analysis: Используя Catalyst, он преобразует неразрешенный логический план в разрешенный логический план , также известный как логический план.
- Каталог содержит имена столбцов и типы данных, на этом этапе он проверяет столбцы, упомянутые в запросе с каталогом.
- Оптимизация: преобразует логический план в оптимизированный логический план .
- Планировщик: Теперь он создает Один или несколько физических планов из оптимизированного логического плана.
- Модель затрат: На этом этапе рассчитывается стоимость для каждого физического плана и выбирается Лучший физический план .
- Создание RDD: генерируется RDD, это заключительный этап оптимизации запросов, который генерирует RDD в байт-коде Java.
После генерации RDD в байтовом коде механизм выполнения Spark выполняет преобразования и действия.
Что такое адаптивное выполнение запросов
Adaptive Query Optimization в Spark 3.0, повторно оптимизирует и корректирует планы запросов на основе метрик времени выполнения, собранных во время выполнения запроса, эта повторная оптимизация плана выполнения происходит после каждого этапа запроса, поскольку этап дает правильное место для повторного выполнения. оптимизация.
Примечание: В задании Spark этап создается с каждым более широким преобразованием, в котором происходит перетасовка данных.
Как это развивалось?
С каждым основным выпуском Spark добавлялись новые функции оптимизации, чтобы лучше выполнять запросы и достигать большей производительности.
- Spark 1.x - Добавлен оптимизатор Catalyst и вольфрамовый механизм выполнения
- Spark 2.x - Добавлен оптимизатор на основе затрат
- Spark 3.0 - теперь добавлено адаптивное выполнение запросов
Включение адаптивного выполнения запросов
Адаптивное выполнение запросов по умолчанию отключено. Чтобы включить, установите для свойства конфигурации spark.sql.adaptive.enabled значение true . Помимо этого свойства, вам также необходимо включить функцию AQE, которую вы собираетесь использовать, которая будет объяснена позже в этом разделе.
spark.conf.set ("spark.sql.adaptive.enabled", истина)
После включения адаптивного выполнения запросов Spark выполняет логическую оптимизацию, физическое планирование и модель затрат, чтобы выбрать лучшее физическое. Выполняя перепланирование для каждого этапа, Spark 3.0 обеспечивает двукратное улучшение TPC-DS по сравнению со Spark 2.4.
Сравнение производительности ADQ (Источник: Databricks)Spark SQL UI
Поскольку план выполнения может измениться во время выполнения после завершения этапа и перед выполнением нового этапа, пользовательский интерфейс SQL также должен отражать изменения.
После того, как вы включили режим AQE, и если у операций есть агрегация, объединения, подзапросы (более широкие преобразования), пользовательский интерфейс Spark Web показывает исходный план выполнения в начале. Когда начинается адаптивное выполнение, каждый этап запроса отправляет дочерние этапы и, вероятно, изменяет в нем план выполнения.
Функции выполнения адаптивных запросов
Spark 3.0 включает в себя три основных функции AQE.
- Уменьшение разделов после перемешивания.
- Коммутационные стратегии объединения для широковещательного присоединения
- Оптимизация перекосного соединения
Уменьшение количества разделов после перемешивания.
До версии 3.0 разработчику необходимо знать данные, поскольку Spark не предоставляет оптимальные разделы после каждой операции перемешивания, и разработчику необходимо повторно разбивать разделы для увеличения или объединения для уменьшения разделов в зависимости от общего количества записей.
В Spark 3.0 после каждого этапа задания Spark динамически определяет оптимальное количество разделов, просматривая метрики завершенного этапа. Чтобы использовать это, вам необходимо включить приведенную ниже конфигурацию.
spark.conf.set ("spark.sql.adaptive.enabled", истина)
spark.conf.set ("spark.sql.adaptive.coalescePartitions.enabled", истина)
Теперь давайте посмотрим, как это работает, сначала без включения AQE.
импортировать spark.implicits._
val simpleData = Seq (("Джеймс", "Продажи", "Нью-Йорк", ,34,10000),
(«Майкл», «Сейлз», «Нью-Йорк», 86000,56,20000),
(«Роберт», «Продажи», «Калифорния», 81000,30,23000),
(«Мария», «Финанс», «CA»,
,24,23000),
(«Раман», «Финансы», «CA», 99000,40,24000),
(«Скотт», «Финансы», «Нью-Йорк», 83000,36,19000),
(«Джен», «Финансы», «Нью-Йорк», 79000,53,15000),
(«Джефф», «Маркетинг», «Калифорния», 80000,25,18000),
(«Кумар», «Маркетинг», «Нью-Йорк», ,50,21000)
)
val df = simpleData.toDF ("имя сотрудника", "отдел", "штат", "зарплата", "возраст", "премия")
val df1 = df.groupBy ("отдел"). count ()
println (df1.rdd.getNumPartitions)
Поскольку groupBy () запускает более широкое преобразование или перемешивание, оператор df1.rdd.getNumPartitions приводит к созданию 200 разделов; Это связано с тем, что Spark по умолчанию создает 200 разделов для операций перемешивания.
Теперь давайте запустим тот же пример после включения AQE
.
Искра.conf.set ("spark.sql.adaptive.enabled", истина)
val df2 = df.groupBy ("отдел"). count ()
println (df2.rdd.getNumPartitions)
Это приводит к 7 разделам в моей системе, вы можете увидеть это число по-другому из-за разницы в ресурсах между моей и вашей системой.
Благодаря этой функции разработчикам не нужно знать размер данных и выполнять операции повторного разделения после перемешивания на основе данных. В дальнейшем об этом позаботится Spark.
Переключение стратегий присоединения для широковещательного присоединения
Среди всех различных стратегий соединения, доступных в Spark, широковещательное хеш-соединение обеспечивает более высокую производительность.Эта стратегия может использоваться только тогда, когда одна из таблиц соединений достаточно мала, чтобы поместиться в памяти в пределах порогового значения широковещательной рассылки.
Когда одна из таблиц соединения может уместиться в памяти до или после фильтрации данных, AQE перепланировывает стратегию соединения во время выполнения и использует широковещательное хеш-соединение.
Оптимизация стыковки с перекосом
Иногда мы можем встретить данные в разделах, которые распределены неравномерно, это называется перекосом данных. Такие операции, как соединение, выполняются на этих разделах очень медленно.Включив AQE, Spark проверяет статистику этапа и определяет, есть ли какие-либо соединения с перекосом, и оптимизирует его, разделяя большие разделы на меньшие (соответствующий размеру раздела в другой таблице / фрейме данных).
spark.conf.set ("spark.sql.adaptive.enabled", истина)
spark.conf.set ("spark.sql.adaptive.skewJoin.enabled", истина)
Убедитесь, что вы установили для обоих свойств конфигурации значение true.
Номер ссылки
Понимание RDD Spark - Часть 3 | пользователя Anveshrithaa S | Аналитика Vidhya
Источник изображения: Java Developer ZoneДобро пожаловать! В предыдущем блоге был представлен краткий обзор RDD в Spark.В этой статье мы обсудим две важные операции с RDD Spark - преобразования и действия вместе с примерами. К концу этого блога у вас будет четкое представление о RDD и о том, как писать программы PySpark с использованием RDD.
Создание RDD в PySpark
Прежде чем мы рассмотрим операции, которые могут выполняться с RDD, давайте узнаем, как создавать RDD в PySpark. Надеюсь, вы уже установили и настроили PySpark на своем компьютере. Если нет, обратитесь к предыдущему блогу за руководством по быстрой установке.
Существует несколько способов создания RDD. Один из простых способов - распараллелить существующую коллекцию в программе драйвера, передав ее методу SparkContext parallelize () . Здесь элементы коллекции копируются в RDD и могут обрабатываться параллельно.
data = [«Scala», «Python», «Java», «R»] myRDD = sc.parallelize (data)
Примечание: Не забудьте создать SparkContext sc (если вы не используя оболочку PySpark, которая автоматически создает sc).Это первое, что вы должны сделать при написании любой программы на Spark.
Здесь данные в параллельной коллекции разделяются на разделы, и на каждом разделе кластера будет выполняться одна задача. По умолчанию Spark устанавливает количество разделов в зависимости от кластера. Его также можно установить вручную, передав количество разделов в качестве второго параметра методу parallelize () .
data = [«Scala», «Python», «Java», «R»] # данные разделены на два раздела
myRDD = sc.parallelize (data, 2)
Другой способ создания Spark RDD - из других источников данных, таких как локальная файловая система, Cassandra, HDFS и т. д. Здесь данные загружаются из внешних наборов данных. Для этого мы используем метод SparkContext textFile , который принимает URL-адрес файла в качестве параметра.
# текстовый файл в RDD
myRDD = sc.textFile («/ path_to_file / textdata.txt») # CSV-файл в RDD
myRDD = sc.textFile («/ path_to_file / csvdata.csv»)
Примечание. Убедитесь, что если вы используете файл из локальной файловой системы, файл также доступен по тому же пути на рабочих узлах.
СДР Spark поддерживают два типа операций, а именно преобразования и действия. После создания RDD мы можем выполнять преобразования и действия с ними.
Преобразования - это операции над RDD, которые создают новый RDD путем внесения изменений в исходный RDD. Вкратце, это функции, которые принимают существующий RDD в качестве входных данных для предоставления новых RDD в качестве выходных данных без внесения изменений в исходный RDD (обратите внимание, что RDD неизменяемы!) Этот процесс преобразования RDD в новый выполняется с помощью таких операций, как фильтр, карта, reduceByKey, sortBy и т. д.Как видно из предыдущего блога, RDD следуют ленивой оценке. То есть преобразования RDD не будут выполняться до тех пор, пока они не будут запущены при необходимости. Таким образом, эти операции можно выполнить в любое время, просто вызвав действие над данными. Преобразования в RDD можно разделить на две категории: узкие и широкие.
- В узких преобразованиях результат преобразования таков, что в выходном RDD каждый из разделов имеет записи из одного и того же раздела в родительском RDD.Такие операции, как Map, FlatMap, Filter, Sample, подвергаются узким преобразованиям.
- Тогда как в широких преобразованиях данные в каждом из разделов результирующего RDD поступают из нескольких разных разделов в родительском RDD. Функции преобразования, такие как groupByKey (), reduceByKey (), подпадают под категорию широких преобразований.
Давайте посмотрим на некоторые преобразования в RDD.
map ()
map () возвращает новый СДР, применяя функцию к каждому из элементов в исходном СДР.
data = [1, 2, 3, 4, 5] myRDD = sc.parallelize (data) # Возвращает новый RDD, умножая все элементы родительского RDD на 2
newRDD = myRDD.map (lambda x: x * 2 ) print (newRDD.collect ())
Вывод:
[2, 4, 6, 8, 10]
flatMap ()
flatMap () возвращает новый RDD, применяя функцию к каждому элементу родительского RDD, а затем сглаживает результат. Давайте посмотрим на примере, чтобы понять разницу между map () и flatMap () .
data = [1, 2, 3]
myRDD = sc.parallelize (data) #map () возвращает [[1], [1, 2], [1, 2, 3]]
mapRDD = myRDD .map (lambda x: range (1, x)) #flatmap () возвращает [1, 1, 2, 1, 2, 3]
flatMapRDD = myRDD.flatMap (lambda x: range (1, x))
filter ()
filter () возвращает новый RDD, содержащий только элементы в родительском RDD, которые удовлетворяют функции внутри filter.
data = [1, 2, 3, 4, 5, 6] myRDD = sc.parallelize (data) # возвращает RDD только с элементами, которые делятся на 2
newRDD = myRDD.filter (lambda x: x% 2 == 0) print (newRDD.collect ())
Вывод:
[2, 4, 6]
отдельный ()
отдельный () возвращает новый RDD, содержащий только отдельные элементы в родительском RDD
data = [1, 2, 2, 3, 3, 3] myRDD = sc.parallelize (data) newRDD = myRDD.distinct () print (newRDD.collect ())
Выход:
[1, 2, 3]
groupByKey ()
groupByKey () группирует значения для каждого ключа в парах (ключ, значение) RDD в одиночная последовательность.Мы получаем объект, который позволяет нам перебирать результаты.
myRDD = sc.parallelize ([(«a», 1), («a», 2), («a», 3), («b», 1)]) # распечатать результат в виде списка
resultList = myRDD.groupByKey (). mapValues (список) reultList.collect ()
Вывод:
[('a', [1, 2, 3]), ('b', [1])] reduceByKey ()
reduceByKey () при вызове набора данных из пар (ключ, значение) возвращает новый набор данных, в котором агрегированы значения для каждого из его ключей.
from operator import addmyRDD = sc.parallelize ([(«a», 1), («a», 2), («a», 3), («b», 1)]) # добавляет значения на keys
newRDD = myRDD.reduceByKey (add) newRDD.collect ()
Вывод:
[('a', 6), ('b', 1)] Примечание: groupByKey () и reduceByKey () могут показаться похожими. Разница между ними в том, что при вызове groupByKey в RDD данные в разделах перетасовываются по сети и только после этого группируются.Это приводит к ненужной передаче большого количества данных по сети. Принимая во внимание, что reduceByKey () объединяет пары на основе ключа на их соответствующих разделах локально, прежде чем перетасовать данные, что делает его более эффективным. Таким образом, reduceByKey () используется для больших наборов данных для повышения производительности.
sortByKey ()
sortByKey () возвращает новый RDD с парами (ключ, значение) родительского RDD в отсортированном порядке в соответствии с ключом.
myRDD = sc.parallelize ([(«c», 1), («d», 2), («a», 3), («b», 4)]) # сортировать по ключу
newRDD = myRDD .sortByKey () newRDD.collect ()
Вывод:
[('a', 3), ('b', 4), ('c', 1), ('d', 2) ] union ()
union () возвращает новый RDD, который является объединением родительских RDD.
myRDD1 = sc.parallelize ([1, 2, 3, 4]) myRDD2 = sc.parallelize ([3, 4, 5, 6, 7]) # объединение myRDD1 и myRDD2
newRDD = myRDD1.union (myRDD2 ) newRDD.collect ()
Вывод:
[1, 2, 3, 4, 3, 4, 5, 6, 7]
Точно так же у нас есть crossction (), который возвращает пересечение двух RDD.
Действия - это операции с RDD для выполнения вычислений и возврата окончательного результата обратно драйверу. Он запускает выполнение для выполнения промежуточных преобразований после загрузки данных в RDD и, наконец, передачи результата обратно. Эти действия представляют собой операции, которые приводят к значениям, не относящимся к RDD. Как мы уже видели, преобразования выполняются только тогда, когда действие требует возврата результата. Сбор, сокращение, countByKey, count - вот некоторые из действий.
Давайте рассмотрим некоторые действия с RDD на примерах.
collect ()
Глядя на приведенные выше примеры, вы теперь знаете, что делает collect () . Он возвращает список, содержащий все элементы СДР.
count ()
count () возвращает количество элементов в RDD
data = [«Scala», «Python», «Java», «R»] myRDD = sc.parallelize (data) # Возвращает 4 в качестве вывода.
myRDD.count ()
reduce ()
reduce () агрегирует элементы RDD, используя функцию, которая принимает два элемента RDD в качестве входных данных и выдает результат.
data = [1, 2, 3, 4, 5] myRDD = sc.parallelize (data) # возвращает произведение всех элементов
myRDD.reduce (lambda x, y: x * y)
Вывод:
120
Может также использоваться для струнных. В этом случае результатом также будет строка.
data = [«Scala», «Python», «Java», «R»] myRDD = sc.parallelize (data) # Объединить строковые элементы
myRDD.reduce (lambda x, y: x + y)
Вывод:
'ScalaPythonJavaR'
foreach ()
Применяет функцию к самому элементу в RDD
def fun (x):
print (x) data = [«Scala», «Python», « Java »,« R »] myRDD = sc.parallelize (data) # функция, применяемая ко всем элементам
myRDD.foreach (fun)
Вывод:
Scala
Python
Java
R
countByValue ()
Возвращает количество каждого уникального значения в RDD как словарь с парами (значение, количество).
data = [«Python», «Scala», «Python», «R», «Python», «Java», «R»,] myRDD = sc.parallelize (data) #items () возвращает список с все ключи и значения словаря, возвращаемые функцией countByValue () myRDD.countByValue (). items ()
Вывод:
[('Python', 3), ('R', 2), ('Java', 1), ('Scala', 1)] countByKey ()
Он подсчитывает количество значений для каждого уникального ключа в RDD и возвращает его в виде словаря.
data = [(«a», 1), («b», 1), («c», 1), («a», 1)] myRDD = sc.parallelize (data) myRDD.countByKey () .items ()
Вывод:
[('a', 2), ('b', 1), ('c', 1)] take (n)
take (n) возвращает первые n элементов RDD в том же порядке.
data = [2, 5, 3, 8, 4] myRDD = sc.parallelize (data) #return the first 2 element
myRDD.take (3)
Вывод:
[2, 5, 3]
top (n)
Возвращает первые n элементов из всех RDD элементы расположены в порядке убывания.
data = [2, 5, 3, 8, 4] myRDD = sc.parallelize (data) # вернуть первые 2 элемента
myRDD.take (3)
Вывод:
[8, 5, 4 ]
Подробнее о внутреннем устройстве и архитектуре Spark
, автор - Джайвардхан Редди
Кредиты изображений: искра.apache.orgApache Spark - это распределенная универсальная среда кластерных вычислений с открытым исходным кодом. Приложение Spark - это процесс JVM, в котором выполняется пользовательский код с использованием Spark в качестве сторонней библиотеки.
В рамках этого блога я покажу, как Spark работает с архитектурой Yarn, на примере и различных задействованных фоновых процессах, таких как:
- Контекст Spark
- Менеджер ресурсов пряжи, Мастер приложений и запуск исполнители (контейнеры).
- Настройка переменных среды, ресурсов задания.
- CoarseGrainedExecutor Backend и RPC на основе Netty.
- SparkListeners.
- Выполнение задания (Логический план, Физический план).
- Spark-WebUI.
Контекст Spark - это точка входа первого уровня и сердце любого приложения Spark. Spark-shell - это не что иное, как REPL на основе Scala с двоичными файлами искры, который создаст объект sc, называемый контекстом искры.
Мы можем запустить искровую оболочку, как показано ниже:
spark-shell --master yarn \ --conf spark.ui.port = 12345 \ --num-executors 3 \ --executor-cores 2 \ - execor-memory 500M В составе spark-shell мы упомянули число исполнителей. Они указывают количество используемых рабочих узлов и количество ядер для каждого из этих рабочих узлов для параллельного выполнения задач.
Или вы можете запустить Spark Shell, используя конфигурацию по умолчанию.
Spark-Shell --master Yarn Конфигурации присутствуют как часть Spark-env.sh
Наша программа Driver выполняется на узле Gateway, который представляет собой не что иное, как искровую оболочку. Он создаст контекст искры и запустит приложение.
Доступ к объекту контекста искры можно получить с помощью sc.
После создания контекста Spark он ожидает ресурсов. Когда ресурсы становятся доступными, контекст Spark настраивает внутренние службы и устанавливает соединение со средой выполнения Spark.
Yarn Resource Manager, Application Master и запуск исполнителей (контейнеров).После создания контекста Spark он сверится с Cluster Manager и запустит Application Master , то есть запускает контейнер и регистрирует обработчики сигналов .
После запуска мастера приложений он устанавливает соединение с драйвером.
Затем ApplicationMasterEndPoint запускает прокси-приложение для подключения к диспетчеру ресурсов.
Теперь Контейнер пряжи выполнит следующие операции, как показано на схеме.
Кредиты изображений: jaceklaskowski.gitbooks.ioii) YarnRMClient зарегистрируется в Мастере приложений.
iii) YarnAllocator: запросит 3 контейнера исполнителей, каждый с 2 ядрами и 884 МБ памяти, включая 384 МБ служебных данных
iv) AM запускает поток репортера
Теперь средство распределения пряжи получает токены от драйвера для запуска узлов Executor и запуска контейнеры.
Настройка переменных среды, ресурсов заданий и запуска контейнеров.Каждый раз, когда контейнер запускается, он выполняет следующие три действия в каждом из них.
Среда выполнения Spark (SparkEnv) - это среда выполнения со службами Spark, которые используются для взаимодействия друг с другом с целью создания распределенной вычислительной платформы для приложения Spark.
Контекст запуска исполнителя YARN назначает каждому исполнителю идентификатор исполнителя для идентификации соответствующего исполнителя (через Spark WebUI) и запускает CoarseGrainedExecutorBackend.
CoarseGrainedExecutor Backend и RPC на основе Netty.После получения ресурсов из Resource Manager мы увидим запуск исполнителя
CoarseGrainedExecutorBackend - ExecutorBackend, который управляет жизненным циклом отдельного исполнителя. Он отправляет водителю статус исполнителя.
При запуске ExecutorRunnable CoarseGrainedExecutorBackend регистрирует конечную точку RPC Executor и обработчики сигналов для связи с драйвером (т.е.е. с конечной точкой RPC CoarseGrainedScheduler) и сообщить, что он готов к запуску задач.
Netty-based RPC - Он используется для связи между рабочими узлами, контекстом искры, исполнителями.
NettyRPCEndPoint используется для отслеживания статуса результата рабочего узла.
RpcEndpointAddress - это логический адрес конечной точки, зарегистрированной в среде RPC, с RpcAddress и именем.
Он имеет формат, показанный ниже:
Это первый момент, когда CoarseGrainedExecutorBackend инициирует обмен данными с драйвером, доступным по адресу driverUrl, через RpcEnv.
SparkListeners Кредиты изображений: jaceklaskowski.gitbooks.ioSparkListener (прослушиватель планировщика) - это класс, который прослушивает события выполнения от Spark DAGScheduler и регистрирует всю информацию о событиях приложения, такую как исполнитель, сведения о выделении драйверов, а также задания, этапы, задачи и другие изменения свойств среды.
SparkContext запускает LiveListenerBus, который находится внутри драйвера. Он регистрирует JobProgressListener в LiveListenerBus, который собирает все данные для отображения статистики в пользовательском интерфейсе искры.
По умолчанию будет включен только слушатель для WebUI, но если мы хотим добавить какие-либо другие слушатели, мы можем использовать spark.extraListeners.
Spark поставляется с двумя слушателями, которые демонстрируют большинство действий
i) StatsReportListener
ii) EventLoggingListener
EventLoggingListener: часть сервера истории Spark, вы можете обрабатывать данные журнала событий.Журнал событий Spark записывает информацию об обработанных заданиях / этапах / задачах. Его можно включить, как показано ниже ...
Файл журнала событий можно прочитать, как показано ниже.
- Драйвер Spark регистрируется в показателях рабочей нагрузки / производительности задания в каталоге spark.evenLog.dir в виде файлов JSON.
- Существует один файл для каждого приложения, имена файлов содержат идентификатор приложения (следовательно, включая временную метку) application_1540458187951_38909.
Показывает тип событий и количество записей для каждого.
Теперь давайте добавим StatsReportListener к spark.extraListeners и проверим статус задания.
Включите уровень ведения журнала INFO для регистратора org.apache.spark.scheduler.StatsReportListener, чтобы просматривать события Spark.
Чтобы включить прослушиватель, вы регистрируете его в SparkContext. Это можно сделать двумя способами.
i) Использование метода SparkContext.addSparkListener (слушатель: SparkListener) внутри вашего приложения Spark.
Щелкните ссылку для реализации настраиваемых прослушивателей - CustomListener
ii) Использование параметра командной строки conf
Давайте прочитаем образец файла и выполним операцию подсчета, чтобы увидеть StatsReportListener.
Выполнение задания (логический план, физический план).В Spark RDD ( устойчивый распределенный набор данных ) является первым уровнем уровня абстракции. Это набор элементов, разделенных по узлам кластера, с которыми можно работать параллельно. RDD можно создать двумя способами.
i) P Распараллеливание существующей коллекции в вашей программе драйвера
ii) Ссылка на набор данных во внешней системе хранения
RDD создаются либо с использованием файла в файловой системе Hadoop, либо с помощью существующего Коллекция Scala в программе драйвера и ее преобразование.
Давайте возьмем образец фрагмента, как показано ниже.
Выполнение указанного выше фрагмента происходит в 2 этапа.
6.1 Логический план: На этом этапе RDD создается с использованием набора преобразований. Он отслеживает эти преобразования в программе драйвера, создавая вычислительную цепочку (серию RDD) в виде графика преобразований. для создания одного RDD под названием Lineage Graph .
Преобразования можно разделить на 2 типа
- Узкое преобразование: Конвейер операций, которые могут выполняться как один этап и не требуют перетасовки данных по разделам - например, карта, фильтр и т. Д. ..
Теперь данные будут считаны в драйвер с помощью широковещательной переменной.
- Широкое преобразование: Здесь каждая операция требует перетасовки данных, отныне для каждого широкого преобразования будет создаваться новый этап - например, reduceByKey и т. Д.
Мы можем просмотреть граф происхождения, используя toDebugString
6.2 Физический план: На этом этапе, как только мы запускаем действие в RDD, DAG Scheduler смотрит на происхождение RDD и предлагает лучший план выполнения с этапами и задачи вместе с TaskSchedulerImpl и параллельно выполнять задание в виде набора задач.
После выполнения операции действия SparkContext запускает задание и регистрирует RDD до первого этапа (то есть до любых широких преобразований) как часть DAGScheduler.
Теперь, прежде чем перейти к следующему этапу (широкие преобразования), он проверит, есть ли какие-либо данные раздела, которые необходимо перетасовать, и есть ли у него какие-либо отсутствующие результаты родительской операции, от которых это зависит, если какой-либо такой этап отсутствует, то он повторно выполняет эту часть операции, используя DAG (направленный ациклический график), что делает его отказоустойчивым.
В случае отсутствия задач назначает задачи исполнителям.
Каждая задача назначается CoarseGrainedExecutorBackend исполнителя.
Получает информацию о блоке из Namenode.
, он выполняет вычисление и возвращает результат.
Затем DAGScheduler ищет новые запускаемые этапы и запускает операцию следующего этапа (reduceByKey).
ShuffleBlockFetcherIterator получает блоки для перемешивания.
Теперь операция сокращения разделена на 2 задачи и выполняется.
По завершении каждой задачи исполнитель возвращает результат драйверу.
После завершения задания отображается результат.
Spark-WebUISpark-UI помогает понять поток выполнения кода и время, необходимое для выполнения определенного задания. Визуализация помогает обнаружить любые основные проблемы, возникающие во время выполнения, и дополнительно оптимизировать приложение Spark.
Мы увидим визуализацию Spark-UI как часть предыдущего шага 6 .
После завершения задания вы можете увидеть подробную информацию о задании, такую как количество этапов, количество задач, которые были запланированы во время выполнения задания.
Нажав на завершенные задания, мы можем просмотреть визуализацию DAG, то есть различные широкие и узкие преобразования как ее часть.
Вы можете увидеть время выполнения каждого этапа.
При щелчке по конкретному этапу в рамках задания отобразятся полные сведения о том, где находятся блоки данных, размер данных, используемый исполнитель, используемая память и время, затраченное на выполнение конкретной задачи.Он также показывает количество происходящих перемешиваний.
Далее, мы можем щелкнуть вкладку «Executors», чтобы просмотреть используемые Executor и драйвер.
Теперь, когда мы увидели, как Spark работает внутри, вы можете определить поток выполнения, используя Spark UI, журналы и настраивая Spark EventListeners для определения оптимального решения при отправке задания Spark.
Примечание : Команды, которые были выполнены в связи с этим сообщением, добавлены как часть моей учетной записи GIT.
Точно так же вы также можете прочитать больше здесь:
Если вы тоже хотите, вы можете связаться со мной в LinkedIn - Jayvardhan Reddy.
Если вам понравилось это читать, вы можете нажать на хлопок и сообщить об этом другим. Если вы хотите, чтобы я добавил что-нибудь еще, не стесняйтесь оставлять ответ?
История трех API-интерфейсов Apache Spark
Из всех радостей разработчиков нет ничего более привлекательного, чем набор API-интерфейсов, которые делают разработчиков продуктивными, простыми в использовании, интуитивно понятными и выразительными.Apache Spark привлекает разработчиков простыми в использовании API-интерфейсами для работы с большими наборами данных на разных языках: Scala, Java, Python и R.
.В этом блоге я исследую три набора API - RDD, DataFrames и Datasets - доступных в Apache Spark 2.2 и последующих версиях; почему и когда следует использовать каждый набор; описать их эффективность и преимущества оптимизации; и перечислить сценарии использования DataFrames и Datasets вместо RDD. В основном я сосредоточусь на DataFrames и Datasets, потому что в Apache Spark 2.0 эти два API объединены.
Наша основная мотивация, стоящая за этой унификацией, - это стремление упростить Spark за счет ограничения количества концепций, которые вам нужно изучить, и предложения способов обработки структурированных данных. А благодаря структуре Spark может предлагать абстракцию более высокого уровня и API в качестве языковых конструкций, зависящих от предметной области.
Устойчивый распределенный набор данных (RDD)
RDD был основным пользовательским API в Spark с момента его создания. По сути, RDD - это неизменяемая распределенная коллекция элементов ваших данных, распределенная по узлам в вашем кластере, которые могут работать параллельно с низкоуровневым API, который предлагает преобразований и действий .
Когда использовать RDD?
Рассмотрите эти сценарии или распространенные варианты использования RDD, когда:
- вы хотите низкоуровневое преобразование, действия и контроль над вашим набором данных;
- ваши данные неструктурированы, например медиапотоки или потоки текста;
- вы хотите манипулировать своими данными с помощью конструкций функционального программирования, а не выражений, специфичных для предметной области;
- вы не заботитесь о наложении схемы, такой как столбчатый формат, при обработке или доступе к атрибутам данных по имени или столбцу; и
- , вы можете отказаться от некоторых преимуществ оптимизации и производительности, доступных с DataFrames и Datasets для структурированных и полуструктурированных данных.
Что происходит с RDD в Apache Spark 2.0?
Вы можете спросить: Выносятся ли RDD в категорию граждан второго сорта? Они устарели?
Ответ: НЕТ!
Более того, как вы заметите ниже, вы можете легко перемещаться между DataFrame или Dataset и RDD по своему желанию - с помощью простых вызовов методов API, а DataFrames и Datasets построены на основе RDD.
DataFrames
Подобно RDD, DataFrame представляет собой неизменяемую распределенную коллекцию данных.В отличие от RDD, данные организованы в именованные столбцы, как таблица в реляционной базе данных. DataFrame, разработанный для того, чтобы еще больше упростить обработку больших наборов данных, позволяет разработчикам накладывать структуру на распределенный набор данных, обеспечивая абстракцию на более высоком уровне; он предоставляет специфичный для предметной области языковой API для управления распределенными данными; и делает Spark доступным для более широкой аудитории, помимо специализированных инженеров по данным.
В нашем предварительном просмотре вебинара Apache Spark 2.0 и в последующем блоге мы упоминали об этом в Spark 2.0, API-интерфейсы DataFrame будут объединены с API-интерфейсами наборов данных, объединяя возможности обработки данных в библиотеках. Благодаря этой унификации у разработчиков теперь меньше концепций, которые нужно изучать или запоминать, и они работают с одним высокоуровневым и типобезопасным API под названием Dataset.
Наборы данных
Начиная с Spark 2.0, набор данных имеет две различные характеристики API: строго типизированный API и нетипизированный API , как показано в таблице ниже.По идее, DataFrame можно рассматривать как псевдоним для коллекции универсальных объектов Dataset [Row] , где Row - это общий нетипизированный JVM-объект. Набор данных, напротив, представляет собой набор из строго типизированных объектов JVM, продиктованных классом case, который вы определяете в Scala, или классом в Java.
Типизированные и нетипизированные API
| Язык | Основная абстракция |
|---|---|
| Скала | Набор данных [T] и DataFrame (псевдоним для набора данных [Row]) |
| Ява | Набор данных [T] |
| Python * | DataFrame |
| R * | DataFrame |
Примечание: Поскольку Python и R не имеют безопасности типов во время компиляции, у нас есть только нетипизированные API, а именно DataFrames.
Преимущества API наборов данных
Как разработчик Spark, вы получаете выгоду от унифицированных API DataFrame и Dataset в Spark 2.0 несколькими способами.
1. Статическая типизация и безопасность типов во время выполнения
Рассматривайте статическую типизацию и безопасность во время выполнения как спектр, при этом SQL наименее ограничивает набор данных, наиболее ограничивая его. Например, в строковых запросах Spark SQL вы не узнаете синтаксическую ошибку до момента выполнения (что может быть дорогостоящим), тогда как в DataFrames и Datasets вы можете обнаруживать ошибки во время компиляции (что экономит время разработчика и затраты).То есть, если вы вызываете функцию в DataFrame, которая не является частью API, компилятор ее поймает. Однако он не обнаружит несуществующее имя столбца до выполнения.
На дальнем конце спектра находится набор данных, наиболее ограничительный. Поскольку все API набора данных выражаются как лямбда-функции и типизированные объекты JVM, любое несоответствие типизированных параметров будет обнаружено во время компиляции. Кроме того, ошибка анализа может быть обнаружена во время компиляции при использовании наборов данных, что позволяет сэкономить время и затраты разработчика.
Все это означает спектр безопасности типов наряду с синтаксисом и ошибками анализа в вашем коде Spark, при этом наборы данных являются наиболее ограничивающими, но продуктивными для разработчика.
2. Абстракция высокого уровня и настраиваемое представление структурированных и полуструктурированных данных
DataFrames как набор наборов данных [строка] отображает структурированное настраиваемое представление в ваши полуструктурированные данные. Например, допустим, у вас есть огромный набор данных событий устройства Интернета вещей, представленный в формате JSON.Поскольку JSON является частично структурированным форматом, он хорошо подходит для использования набора данных как коллекции строго типизированного набора данных [DeviceIoTData] .
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": «Польша», «широта»: 53.080000, «долгота»: 18.620000, «масштаб»: «Цельсий», «темп»: 21, «влажность»: 65, «уровень батареи»: 8, «c02_level»: 1408, «ЖКД». ":" красный "," отметка времени ": 1458081226051} Каждую запись JSON можно выразить как DeviceIoTData , настраиваемый объект, с классом сценария Scala.
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, влажность: Long, ip: String, latitude: Double, lcd: String, longitude : Double, масштаб: String, temp: Long, отметка времени: Long)
Затем мы можем прочитать данные из файла JSON.
// читаем файл json и создаем набор данных из // класс случая DeviceIoTData // ds теперь представляет собой набор объектов JVM Scala DeviceIoTData val ds = искра.read.json («/ databricks-public-datasets / data / iot / iot_devices.json»). как [DeviceIoTData]
В приведенном выше коде под капотом происходят три вещи:
- Spark считывает JSON, определяет схему и создает коллекцию DataFrames.
- На этом этапе Spark преобразует ваши данные в DataFrame = Dataset [Row] , коллекцию универсального объекта Row, поскольку ему неизвестен точный тип.
- Теперь Spark преобразует набор данных [строка] -> набор данных [DeviceIoTData] зависящий от типа объект Scala JVM в соответствии с классом DeviceIoTData .
Большинство из нас, кто работает со структурированными данными, привыкли просматривать и обрабатывать данные в виде столбцов или доступа к определенным атрибутам внутри объекта. Используя Dataset как коллекцию из типизированных объектов Dataset [ElementType] , вы легко получаете как безопасность во время компиляции, так и настраиваемое представление для строго типизированных объектов JVM. И полученный в результате строго типизированный Dataset [T] из приведенного выше кода можно легко отобразить или обработать с помощью высокоуровневых методов.
3. Простота использования API со структурой
Хотя структура может ограничивать контроль над тем, что ваша программа Spark может делать с данными, она вводит богатую семантику и простой набор операций, специфичных для предметной области, которые могут быть выражены в виде высокоуровневых конструкций. Однако большинство вычислений можно выполнить с помощью высокоуровневых API Dataset. Например, гораздо проще выполнить операции agg , select , sum , avg , map , filter или groupBy путем доступа к строкам DeviceIoTData типизированного объекта Dataset, чем использование RDD поля данных.
Выражение ваших вычислений в API, зависящем от предметной области, намного проще и легче, чем с выражениями типа алгебры отношений (в RDD). Например, приведенный ниже код filter () и map () создаст еще один неизменяемый набор данных.
// Используем filter (), map (), groupBy () country и вычисляем avg ()
// для температуры и влажности. Эта операция приводит к
// еще один неизменяемый набор данных. Запрос проще читать,
// и выразительный
val dsAvgTmp = ds.filter (d => {d.temp> 25}). map (d => (d.temp, d.humidity, d.cca3)). groupBy ($ "_ 3"). avg ()
// отображаем результирующий набор данных
дисплей (dsAvgTmp)
4. Производительность и оптимизация
Наряду со всеми вышеперечисленными преимуществами нельзя упускать из виду повышение эффективности использования пространства и повышения производительности при использовании DataFrames и API-интерфейсов Dataset по двум причинам.
Во-первых, поскольку API-интерфейсы DataFrame и Dataset построены на основе механизма Spark SQL, он использует Catalyst для создания оптимизированного логического и физического плана запроса.В API-интерфейсах R, Java, Scala или Python DataFrame / Dataset для всех запросов типа отношения применяется один и тот же оптимизатор кода, что обеспечивает эффективное пространство и скорость. В то время как типизированный API Dataset [T] оптимизирован для задач инженерии данных, нетипизированный Dataset [Row] (псевдоним DataFrame) работает еще быстрее и подходит для интерактивного анализа.
Во-вторых, поскольку Spark как компилятор понимает ваш объект JVM типа Dataset, он сопоставляет ваш объект JVM конкретного типа с представлением внутренней памяти Tungsten с помощью кодировщиков.В результате Tungsten Encoders могут эффективно сериализовать / десериализовать объекты JVM, а также генерировать компактный байт-код, который может выполняться с превосходной скоростью.
Когда мне следует использовать DataFrames или Datasets?
- Если вам нужна расширенная семантика, высокоуровневые абстракции и специфичные для домена API, используйте DataFrame или Dataset.
- Если ваша обработка требует выражений высокого уровня, фильтров, карт, агрегации, средних значений, суммы, SQL-запросов, столбцового доступа и использования лямбда-функций для полуструктурированных данных, используйте DataFrame или Dataset.
- Если вы хотите более высокий уровень безопасности типов во время компиляции, хотите типизированные объекты JVM, воспользоваться преимуществами оптимизации Catalyst и эффективно генерировать код Tungsten, используйте Dataset.
- Если вам нужна унификация и упрощение API-интерфейсов в библиотеках Spark, используйте DataFrame или Dataset.
- Если вы являетесь пользователем R, используйте DataFrames.
- Если вы пользователь Python, используйте DataFrames и вернитесь к RDD, если вам нужно больше контроля.
Обратите внимание, что вы всегда можете легко взаимодействовать или конвертировать из DataFrame и / или Dataset в RDD простым вызовом метода .rdd . Например,
// выбираем определенные поля из набора данных, применяем предикат // используя метод where (), конвертируем в RDD и показываем первые 10 // RDD строки val deviceEventsDS = ds.select ($ "имя_устройства", $ "cca3", $ "c02_level"). где ($ "c02_level"> 1300) // конвертируем в RDD и берем первые 10 строк val eventsRDD = deviceEventsDS.rdd.take (10)
Собираем все вместе
В итоге выбор, когда использовать RDD или DataFrame и / или Dataset, кажется очевидным.В то время как первый предлагает вам низкоуровневую функциональность и контроль, последний позволяет настраивать представление и структуру, предлагает высокоуровневые и специфичные для домена операции, экономит место и выполняется с превосходной скоростью.
Изучив уроки, которые мы извлекли из ранних выпусков Spark - как упростить Spark для разработчиков, как оптимизировать и сделать его производительным - мы решили поднять низкоуровневые API RDD до высокоуровневой абстракции как DataFrame и Dataset и для построения этой унифицированной абстракции данных между библиотеками поверх оптимизатора Catalyst и Tungsten.
Выберите один - DataFrames и / или Dataset или RDD API - который соответствует вашим потребностям и сценарию использования, но я не удивлюсь, если вы попадете в лагерь большинства разработчиков, которые работают со структурными и полуструктурированными данными.
Что дальше?
Вы можете попробовать Apache Spark 2.2 на Databricks.
Вы также можете посмотреть презентацию Spark Summit «История трех API-интерфейсов Apache Spark: RDD против DataFrames и наборов данных»
Если вы еще не зарегистрировались, попробуйте Databricks прямо сейчас.
В ближайшие недели у нас будет серия блогов о структурированной потоковой передаче. Следите за обновлениями.
Spark и Spark Streaming Unit Testing
При разработке распределенной системы очень важно упростить ее тестирование. Выполняйте тесты в контролируемой среде, в идеале из вашей IDE. Длительный цикл разработки-тестирования-разработки сложных систем может убить вашу производительность. Ниже вы найдете мою стратегию тестирования приложений Spark и Spark Streaming.
Модульные или интеграционные тесты, вот в чем вопрос
Наше гипотетическое приложение Spark извлекает данные из Apache Kafka, применяет преобразования, используя RDD а также DStreams и сохранять результаты в базе данных Cassandra или Elastic Search.На производстве приложение Spark разворачивается в кластере YARN или Mesos, и все склеивается с помощью ZooKeeper. Общая картина архитектуры потоковой обработки представлена ниже:
Множество движущихся частей, не так-то просто настроить и протестировать. Даже с автоматической подготовкой, реализованной с помощью Vagrant, Docker и Ansible. Если вы не можете протестировать все, протестируйте хотя бы самую важную часть вашего приложения - преобразования, - реализованные с помощью Spark.
Spark утверждает, что он удобен для модульного тестирования с любой популярной средой модульного тестирования.Строго говоря, Spark поддерживает довольно легкое интеграционное тестирование, а не модульное тестирование, IMHO. Но все же гораздо удобнее тестировать логику трансформации локально, чем развертывать все части на YARN.
Существует запрос на вытягивание SPARK-1751, который добавляет поддержку «модульных тестов» для потоков Apache Kafka. Стоит ли нам идти по этому пути? Требуются встроенный ZooKeeper и встроенный Apache Kafka, тестовое устройство сложное и громоздкое. Возможно, тесты будут хрупкими и трудными в обслуживании. Такой подход имеет смысл для основной команды Spark, они хотят протестировать интеграцию Spark и Kafka.
Что нужно тестировать?
Наша логика преобразования реализована с помощью Spark, не более того. Но как проверить логику, так тесно связанную с Spark API (RDD, DStream)? Давайте определим, как организовано типичное приложение Spark. Наша гипотетическая структура приложения выглядит так:
- Инициализировать
SparkContextилиStreamingContext. - Создать RDD или DStream для данного источника (например, Apache Kafka)
- Оценить преобразования в RDD или DStream API.
- Поместите результаты преобразования (например, агрегаты) во внешнюю базу данных.
Контекст
SparkContext и StreamingContext можно легко инициализировать для целей тестирования.
Установите главный URL-адрес на , локальный , запустите операции, а затем корректно остановите контекст.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 год | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 год 22 23 24 25 26 год 27 28 год | |
RDD и DStream
Проблема в том, как создать RDD или DStream.В целях тестирования его необходимо упростить, чтобы избежать использования встроенных Kafka и ZooKeeper. Ниже вы можете найти примеры создания RDD и DStream в памяти.
В памяти RDD1 2 | |
1 2 3 4 5 | |
Логика преобразования
Самая важная часть нашего приложения - логика преобразований - должна быть инкапсулирована в отдельный класс или объект. Объект предпочтительнее, чтобы избежать накладных расходов на сериализацию класса. Точно такой же код используется приложением и тестом.
WordCount.scala1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Искровой тест
Пришло время реализовать наш первый тест на преобразование WordCount.Код теста очень прост и удобен для чтения. Единая точка зрения, лучшая документация по вашей системе, всегда актуальная.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Тест Spark Streaming
Преобразования Spark Streaming намного сложнее тестировать.
Полный контроль над часами необходим для ручного управления пакетами, слайдами и окнами.Без контролируемых часов вы бы закончили сложные тесты с множеством вызовов Thread.sleeep .
И выполнение теста займет много времени.
Единственный минус - у вас не будет лишнего времени на кофе во время выполнения тестов.
Spark Streaming обеспечивает необходимую абстракцию от системных часов, класс ManualClock .
К сожалению, ManualClock класс объявлен как закрытый пакет. Нужен какой-то взлом.
Оболочка, представленная ниже, представляет собой адаптер для исходного класса ManualClock , но без ограничения доступа.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Теперь тест Spark Streaming можно эффективно реализовать. Тест не должен ждать системных часов, и тест выполняется с точностью до миллисекунды. Вы можете легко протестировать свой оконный сценарий от самого начала до самого конца. С данной структурой \ when \ then вы сможете понять протестированную логику без дополнительных объяснений.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 год 22 23 24 25 26 год 27 28 год 29 30 31 год 32 33 34 35 год 36 37 38 39 40 41 год 42 43 год 44 год 45 46 47 48 49 50 51 52 53 54 55 56 57 | |
Один комментарий к В конечном итоге использование признака .
Эта черта необходима, потому что Spark Streaming является многопоточным приложением, и результаты не вычисляются немедленно.
Я обнаружил, что для Spark Streaming достаточно тайм-аута в 1 секунду для расчета результатов.
Тайм-аут не связан с длительностью пакета, слайда или окна.
Сводка
Полный рабочий проект опубликован на GitHub.
