
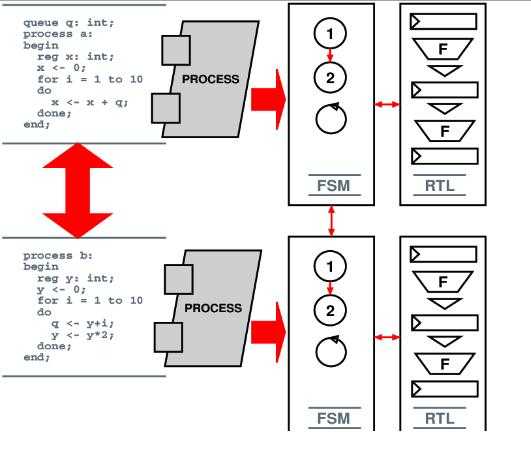
ПЛИС – это… Что такое ПЛИС?
CPLD ПЛИС Altera MAX 7128, эквивалентная 2500 вентилямПрограмми́руемая логи́ческая интегра́льная схе́ма (ПЛИС, англ. programmable logic device, PLD) — электронный компонент, используемый для создания цифровых интегральных схем. В отличие от обычных цифровых микросхем, логика работы ПЛИС не определяется при изготовлении, а задаётся посредством программирования (проектирования). Для программирования используются программаторы и отладочные среды, позволяющие задать желаемую структуру цифрового устройства в виде принципиальной электрической схемы или программы на специальных языках описания аппаратуры: Verilog, VHDL, AHDL и др. Альтернативой ПЛИС являются: программируемые логические контроллеры (ПЛК), базовые матричные кристаллы (БМК), требующие заводского производственного процесса для программирования; ASIC — специализированные заказные большие интегральные схемы(БИС), которые при мелкосерийном и единичном производстве существенно дороже; специализированные компьютеры, процессоры (например, цифровой сигнальный процессор) или микроконтроллеры, которые из-за программного способа реализации алгоритмов в работе медленнее ПЛИС.
Некоторые производители ПЛИС предлагают программные процессоры для своих ПЛИС, которые могут быть модифицированы под конкретную задачу, а затем встроены в ПЛИС. Тем самым обеспечивается уменьшение места на печатной плате и упрощение проектирования самой ПЛИС, за счёт быстродействия.
Некоторые сферы применения
ПЛИС широко используется для построения различных по сложности и по возможностям цифровых устройств.
Это приложения, где необходимо большое количество портов ввода-вывода (бывают ПЛИС с более чем 1000 выводов («пинов»)), цифровая обработка сигнала (ЦОС), цифровая видеоаудиоаппаратура, высокоскоростная передача данных, криптография, проектирование и прототипирование ASIC, в качестве мостов (коммутаторов) между системами с различной логикой и напряжением питания, реализация нейрочипов, моделирование квантовых вычислений.
В современных периферийных и основных компьютерных устройствах платы расширения в системе Plug and Play имеют специальную микросхему — ПЛИС, которая позволяет плате сообщать свой идентификатор и список требуемых и поддерживаемых ресурсов.
Типы ПЛИС
Ранние ПЛИС
В 1970 году компания Texas Instruments разработала маскируемые (программируемые с помощью маски, англ. mask-programmable) ИС основанные на ассоциативном ПЗУ (ROAM) фирмы IBM. Эта микросхема, TMS2000, программировалась чередованием металлических слоёв в процессе производства ИС. TMS2000 имела до 17 входов и 18 выходов с 8-ю JK-триггерами в качестве памяти. Для этих устройств компания TI ввела термин Programmable Logic Array(PLA) — программируемая логическая матрица.
PAL
Основная статья: PAL (ПЛИС)
PAL (англ. Programmable Array Logic) — программируемый массив (матрица) логики. В СССР PLA и PLM не различались и обозначились как ПЛМ. Разница между ними состоит в доступности программирования внутренней структуры (матриц) ПЛМ.
GAL
Основная статья: GAL
CPLD
Основная статья: CPLDCPLD (англ. complex programmable logic device — сложные программируемые логические устройства) содержат относительно крупные программируемые логические блоки — макроячейки, соединённые с внешними выводами и внутренними шинами. Функциональность CPLD кодируется в энергонезависимой памяти, поэтому нет необходимости их перепрограммировать при включении. Может применяться для расширения числа входов/выходов рядом с большими кристаллами, или для предобработки сигналов (например, контроллер COM-порта, USB, VGA).
FPGA
Основная статья: FPGAFPGA (англ. field-programmable gate array) содержат блоки умножения-суммирования, которые широко применяются при обработке сигналов (DSP), а также логические элементы (как правило, на базе таблиц перекодировки — таблиц истинности) и их блоки коммутации. FPGA обычно используются для обработки сигналов, имеют больше логических элементов и более гибкую архитектуру, чем CPLD. Программа для FPGA хранится в распределённой памяти, которая может быть выполнена как на основе энергозависимых ячеек статического ОЗУ (подобные микросхемы производят, например, фирмы Xilinx и Altera) — в этом случае программа не сохраняется при исчезновении электропитания микросхемы, так и на основе энергонезависимых ячеек Flash-памяти или перемычек antifuse (такие микросхемы производит фирма Actel и Lattice Semiconductor) — в этих случаях программа сохраняется при исчезновении электропитания. Если программа хранится в энергозависимой памяти, то при каждом включении питания микросхемы необходимо заново конфигурировать её при помощи начального загрузчика, который может быть встроен и в саму FPGA. Альтернативой ПЛИС FPGA являются более медленные цифровые процессоры обработки сигналов. FPGA применяются также, как ускорители универсальных процессоров в суперкомпьютерах (например: Cray — XD1, SGI — Проект RASC).
Прочие
Некоторые ведущие мировые производители ПЛИС
Основной производитель кристаллов для ПЛИС
См. также
Примечания
Ссылки
dic.academic.ru
Архитектура ПЛИС (FPGA)
Архитектура ПЛИС (FPGA)
- Подробности
- Категория: Разное
- Создано 20 Январь 2014
- Автор: Николай Ковач
- Просмотров: 147032

FPGA – это сокращение от английского словосочетания Field Programmable Gate Array.
ПЛИС – это сокращение от словосочетания «Программируемая Логическая Интегральная Схема». Слово ПЛИС встречается в русскоязычных документациях и описаниях вместо слова FPGA. Далее по тексту в основном будет использоваться этот термин – ПЛИС.
ПЛИС и FPGA – это аббревиатуры, обозначающие один и тот же класс электронных компонентов, микросхем. Это микросхемы, применяемые для создания собственной структуры цифровых интегральных схем.
Логика работы ПЛИС определяется не на фабрике изготовителем микросхемы, а путем дополнительного программирования (в полевых условиях, field-programmable) с помощью специальных средств: программаторов и программного обеспечения.
Микросхемы ПЛИС – это не микропроцессоры, в которых пользовательская программа выполняется последовательно, команда за командой. В ПЛИС реализуется именно электронная схема, состоящая из логики и триггеров.
Проект для ПЛИС может быть разработан, например, в виде принципиальной схемы. Еще существуют специальные языки описания аппаратуры типа Verilog или VHDL.
В любом случае, и графическое и текстовое описание проекта реализует цифровую электронную схему, которая в конечном счете будет «встроена» в ПЛИС.
Обычно, сама микросхема ПЛИС состоит из:
- конфигурируемых логических блоков, реализующих требуемую логическую функцию;
- программируемых электронных связей между конфигурируемыми логическими блоками;
- программируемых блоков ввода/вывода, обеспечивающих связь внешнего вывода микросхемы с внутренней логикой.
Строго говоря это не полный список. В современных ПЛИС часто бывают встроены дополнительно блоки памяти, блоки DSP или умножители, PLL и другие компоненты. Здесь, в этой статье я их рассматривать не буду.
Разработчик проекта для ПЛИС обычно абстрагируется от внутреннего устройства конкретной микросхемы. Он просто описывает желаемую логику работы «своей» будещей микросхемы в виде схемы или текста на Verilog/ VHDL. Компилятор, зная внутреннее устройство ПЛИС сам пытается разместить требуемую схему по имеющимся конфигурируемым логическим блокам и пытается соединить эти блоки с помощью имеющихся программируемых электронных связей. В общем случае размещение и трассировка связей между логическими блоками в ПЛИС остается за компилятором.
Классификация ПЛИС по типу хранения конфигурации.
SRAM-Based.
Это одна из самых распространенных разновидностей ПЛИС. Конфигурация ПЛИС хранится ячейках статической памяти, изготовленной по стандартной технологии CMOS.
Достоинство этой технологии – возможность многократного перепрограммирования ПЛИС. Недостатки – не самое высокое быстродействие, после включения питания прошивку нужно вновь загружать. Значит на плате должен еще стоять загрузчик, специальная микросхема FLASH или микроконтроллер – все это удорожает конечное изделие.
Flash-based.
В таких микросхемах хранение конфигурации происходит во внутренней FLASH памяти или памяти типа EEPROM. Такие ПЛИС лучше тем, что при выключении питания прошивка не пропадает. После подачи питания микросхема опять готова к работе. Однако, у этого типа ПЛИС есть и свои недостатки. Реализация FLASH памяти внутри CMOS микросхемы – это не очень просто. Требуется совместить два разных техпроцесса для производства таких микросхем. Значит они получаются дороже. Кроме того, такие микросхемы, как правило, имеют ограниченное количество циклов перезаписи конфигурации.
Antifuse.
Специальная технология по которой выполняются однократно программируемые ПЛИС. Программирование такой ПЛИС заключается в расплавлении в нужных местах чипа специальных перемычек для образования нужной схемы.
Недостаток – собственно программировать / прошивать чип можно только один раз. После этого исправить уже ничего нельзя. Сам процесс прошивки довольно не быстрый. Зато есть масса достоинств у таких ПЛИС: они довольно быстрые (могут работать на больших частотах), меньше подвержены сбоям при радиации – все из-за того, что конфигурация получается в виде перемычек, а не в виде дополнительной логики, как у SRAM-based.
Конфигурируемые логические блоки.
В документации компании Альтера встречается выражение Logic Array Block (LAB) – массив логики. У компании Xilinx в микросхемах ПЛИС есть примерно такие же блоки – Configurable Logic Block (CLB). Конфигурируемый логический блок – это базовый элемент в ПЛИС, в нем может быть выполнена какая-то простая логическая функция или реализовано хранение результата вычисления в регистрах (триггерах).
Сложность и структура конфигурируемого логического блока (CLB) определяется производителем.
Теоретически, конфигурируемый логический блок может быть, например, очень простым, просто как отдельный транзистор. Или он может быть очень сложным, как целый процессор. Это крайние точки реализации.
В первом случае потребуется огромное число программируемых связей, чтобы потом из отдельных транзисторов собрать требуемую схему. Во втором случае связей может нужно и не так много, но теряется гибкость проектирования пользовательской схемы.
Именно поэтому конфигурируемый блок обычно представляет из себя что-то среднее: он обычно достаточно сложен, чтобы можно было бы зашить туда некоторую функцию, но и довольно мал, чтобы разместить множество таких блоков внутри ПЛИС и чтобы была возможность связать их в единую схему.
Таким образом, выбор структуры конфигурируемого логического блока производителем ПЛИС – это всегда поиск компромиса по площади кристалла, по быстродействию, энергопотреблению и так далее.
Конфигурируемый логический блок может состоять из одного или нескольких базовых логических элементов. В англоязычной литературе это Basic Logic Element (BLE) или просто Logic Element (LE). В ПЛИС обычно используются так называемые LUT-based базовые логические элементы. Что-то вроде этого:
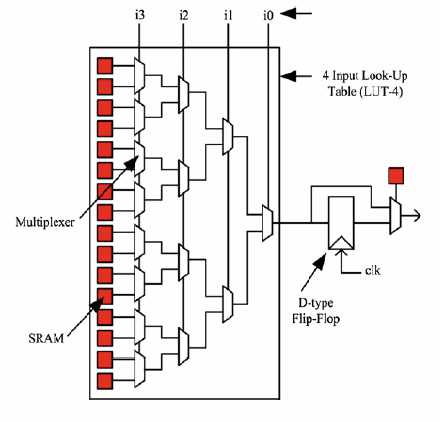
Рис. 1. Пример традиционного базового логического элемента.
LUT – это Look-Up Table, таблица преобразования. Например, на Рис.1 показан четырехбитный LUT в составе базового логического блока. Здесь четырехбитному числу на входе логической функции ставится в соответствие однобитный результат. Красные квадратики на Рис. 1 обозначают программируемый элемент, регистр – это та память, где хранится прошивка для ПЛИС. Видно, что для конфигурации 4-х битного LUT требуется 16 конфигурационных регистра. Содержимое этих регистров определяют логическую функцию, реализованную внутри базового логического элемента.
Еще один конфигурационный регистр (на Рис. 1 это одиночный красный квадратик справа) определяет нужно ли на выход базового логического элемента выдавать прямо значение с LUT или нужно выдать зафиксированное в D-триггере значение с LUT. Фиксация и хранение данных в цифровых схемах нужна практически в любом проекте.
Примерно такой логический элемент использовался в моем экспериментальном проекте «ПЛИС внутри ПЛИС».
Рассматривая Рис. 1 как пример традиционного базового логического элемента понимаешь какая избыточность заложена внутрь современного кристалла ПЛИС (SRAM-based). Ведь в самом деле, конфигурационные регистры (красные квадратики) прямо не доступны для использования в цифровом проекте. Они только служат для формирования пользовательской функции. Для одного D-триггера в пользовательском проекте требуется более 16 (иногда много больше) триггеров для хранения конфигурации ПЛИС.
На самом деле базовый логический элемент в разных ПЛИС оказывается гораздо сложнее, чем показано на Рис. 1. Ниже есть некоторые примеры из документации на разные типы ПЛИС.
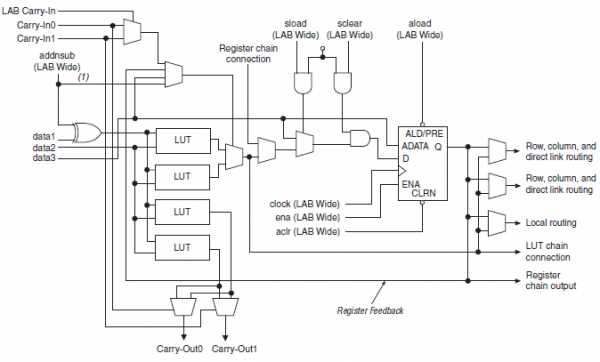
Рис. 2. Базовый логический элемент CPLD MAX II компании Альтера.
Здесь хорошо видны LUT и D-Триггер хранения результата. Ниже, на Рис. 3 представлен базовый элемент Cyclone III.
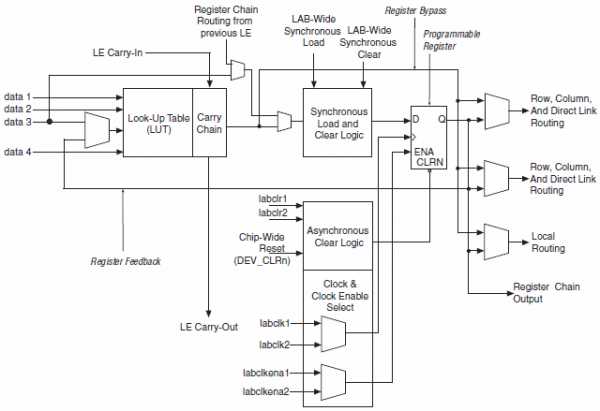
Рис. 3. Базовый логический элемент FPGA Cyclone III компании Альтера.
В микросхемах Альтеры в одном LAB может содержаться 10-16 LE.
В микросхемах компании Xilinx Virtex-6 базовый логический элемент – это так называемый Slice. В одном CLB всего два Slice. Зато один Slice – это довольно сложное устройство:
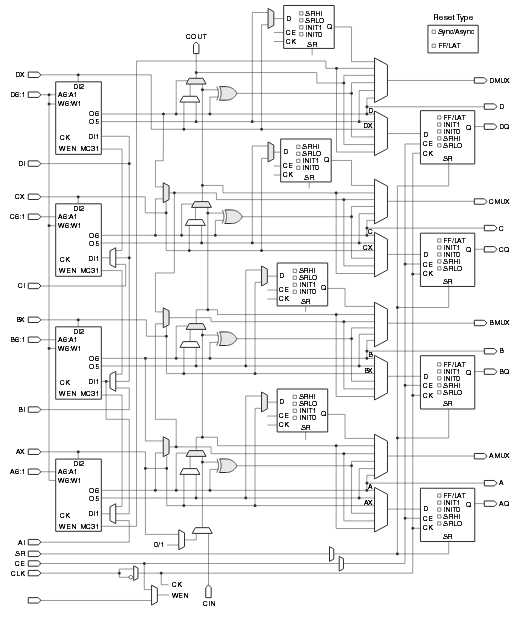
Рис. 4. Базовый элемент Xilinx Virtex-6 Slice.
В одном CLB Virtex-6 имеется 8 LUT и 16 D-Триггеров и еще кое-что плюс к этому. Вот так все сложно.
Другая крайность – микросхемы FPGA компании Microsemi (бывшая Actel).
Например, в микросхемах серии 40MX базовый логический элемент выглядит вот так:
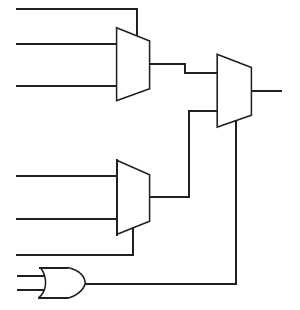
Рис. 5. Logic Module of Microsemi 40MX serie.
Восемь входов и один выход.
Здесь нет ни Look-Up Table, ни даже D-Триггера. Триггера, как и остальная логика, формируются где нужно из вот таких крошечных кирпичиков – Logic Module.
Почему у разных компаний получилась такая большая разница в реализации базового логического элемента? Видимо в микросхемах Microsemi связь между базовыми блоками обходится гораздо дешевле: серия 40MX является однократно программируемой. В ней межблочные связи «проплавляются» между соединяющими дорожками и позже не могут быть изменены. Нет никаких регистров для временного хранения прошивки. Здесь нет программируемых переключателей, мультиплексоров, как в FPGA других типов. Ну микросхемы компании Microsemi – это несколько особый случай. Это технология называется antifuse – для производства таких микросхем используется модифицированный техпроцесс CMOS с дополнительными слоями для организации межблочных связей.
Программируемые связи между логическими блоками.
Чтобы в ПЛИС заработала нужная нам цифровая схема мало того, что нужно сконфигурировать имеющиеся логические блоки особым образом, еще нужно создать, запрограммировать связи между логическими блоками.
Для этого в ПЛИС имеются специальные конфигурируемые коммутаторы.
В англоязычной документации встречаются следующие термины: FPGA Routing Architecture и Programmable Routing Interconnect. Это все об этом, о программируемых связях между логическими блоками.
Известно две основных методики построения ПЛИС по типу архитектуры связей: островная и иерархическая.
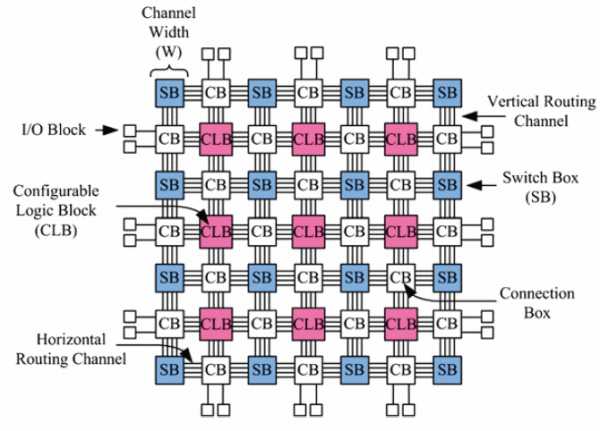
Рис. 6. Островная ПЛИС.
Островная ПЛИС называется так потому, что конфигурируемые блоки все равны между собой и находятся, как острова в океане, между узлами коммутации и линиями связи.
Здесь, на Рис. 6 обозначаются CB – Connection Box и SB – Switch Box. В сущности это программируемые мультиплексоры, подключающие тот или иной CLB к другому CLB через цепочки проводов в ПЛИС.
Это island-style FPGA или mesh-based FPGA. Типичный пример таких микросхем – это серии Altera Cyclone и Stratix.
Второй известный тип ПЛИС – это иерархические ПЛИС. Здесь идет расчет на то, что в схеме всегда есть участки которые взаимодействуют друг с другом более тесно, чем с отдаленными модулями проекта.
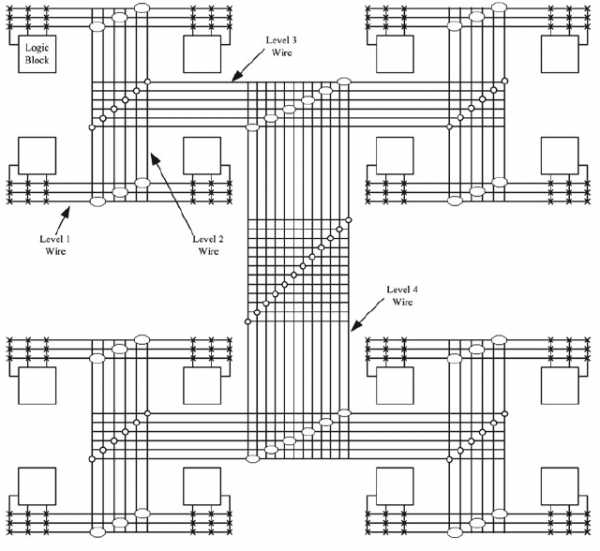
Рис. 7. Иерархическая ПЛИС.
Здесь близлежащие CLB соединить довольно просто, нужно не много коммутаторов и получающиеся связи работают быстро. Вот если нужен более крупный блок вычислителей, то сигнал должен выйти на более высокий уровень иерархии и потом зайти вглубь в соседнюю «комнату».
Нельзя сказать, что это существенно хуже, чем island-style. Просто каждый метод имеет свои плюсы и минусы.
Типичные представители иерархических ПЛИС – это микросхемы компании Альтера серии Flex10K, APEX.
Программное обеспечение для проектирования ПЛИС.
Программное обеспечение для проектирования ПЛИС, а именно компилятор (синтезатор логики и фиттер и ассемблер) – это, возможно, самая сложная часть всей ПЛИС технологии.
Компилятор должен проанализировать пользовательский проект (схемы и текстовые описания на Verilog HDL или VHDL ) и сгенерировать нетлист (netlist) – список всех элементов схемы и связи между ними. Netlist должен быть оптимизирован – логические функции нужно минимизировать, возможные дублированные регистры нужно удалить.
Затем компилятор должен вместить всю логику из netlist в имеющуюся архитектуру ПЛИС. Это делает фиттер (fitter). Он размещает логические элементы и выполняет трассировку связей между ними (процесс place and route). Сложность состоит в том, что один и тот же проект может быть размещен в ПЛИС разными способами и этих способов миллионы. Некоторое размещение и трассировка оказываются лучше, другие хуже. Главный критерий качества полученной системы – максимальная частота, на которой сможет работать проект при данном размещении элементов и при данной трассировке связей. Здесь оказывает влияние длина связей между логическими блоками и количество программируемых коммутаторов между ними.
Компилятор, зная архитектуру ПЛИС по результатам работы дополнительно выдает отчет о времени прохождении сигналов от регистра до регистра. Эта информация часто бывает полезной для разработчика высокопроизводительных систем. Разработчик для ПЛИС имеет возможность давать некоторые советы компилятору где, в каком месте кристалла лучше разместить тот или иной модуль проекта.
Выбирая для своего проекта, для своей платы конкретную микросхемы ПЛИС разработчик в некоторой мере попадает в зависимость от производителя этой ПЛИС, так как должен в работе пользоваться программным обеспечением от этого же производителя.
Программное обеспечение компании Альтера: Quartus II.
ПО Xilinx для проектирования для ПЛИС: ISE Suite, Vivaldo Design Suite.
ПО компании Microsemi: Libero IDE, Libero SoC.
Возможно, программное обеспечение, компиляторы для ПЛИС – это важнейшая составляющая интеллектуальной собственности компаний производителей ПЛИС.
На страницах нашего сайта https://marsohod.org мы уделяем внимание прежде всего проектированию систем на базе ПЛИС компании Альтера и пользуемся средой разработки Altera Quartus II.
marsohod.org
Архитектура ПЛИС (FPGA)
- Подробности
- Категория: Разное
- Создано 20 Январь 2014
- Автор: Николай Ковач
- Просмотров: 147030
FPGA – это сокращение от английского словосочетания Field Programmable Gate Array.
ПЛИС – это сокращение от словосочетания «Программируемая Логическая Интегральная Схема». Слово ПЛИС встречается в русскоязычных документациях и описаниях вместо слова FPGA. Далее по тексту в основном будет использоваться этот термин – ПЛИС.
ПЛИС и FPGA – это аббревиатуры, обозначающие один и тот же класс электронных компонентов, микросхем. Это микросхемы, применяемые для создания собственной структуры цифровых интегральных схем.
Логика работы ПЛИС определяется не на фабрике изготовителем микросхемы, а путем дополнительного программирования (в полевых условиях, field-programmable) с помощью специальных средств: программаторов и программного обеспечения.
Микросхемы ПЛИС – это не микропроцессоры, в которых пользовательская программа выполняется последовательно, команда за командой. В ПЛИС реализуется именно электронная схема, состоящая из логики и триггеров.
Проект для ПЛИС может быть разработан, например, в виде принципиальной схемы. Еще существуют специальные языки описания аппаратуры типа Verilog или VHDL.
В любом случае, и графическое и текстовое описание проекта реализует цифровую электронную схему, которая в конечном счете будет «встроена» в ПЛИС.
Обычно, сама микросхема ПЛИС состоит из:
- конфигурируемых логических блоков, реализующих требуемую логическую функцию;
- программируемых электронных связей между конфигурируемыми логическими блоками;
- программируемых блоков ввода/вывода, обеспечивающих связь внешнего вывода микросхемы с внутренней логикой.
Строго говоря это не полный список. В современных ПЛИС часто бывают встроены дополнительно блоки памяти, блоки DSP или умножители, PLL и другие компоненты. Здесь, в этой статье я их рассматривать не буду.
Разработчик проекта для ПЛИС обычно абстрагируется от внутреннего устройства конкретной микросхемы. Он просто описывает желаемую логику работы «своей» будещей микросхемы в виде схемы или текста на Verilog/ VHDL. Компилятор, зная внутреннее устройство ПЛИС сам пытается разместить требуемую схему по имеющимся конфигурируемым логическим блокам и пытается соединить эти блоки с помощью имеющихся программируемых электронных связей. В общем случае размещение и трассировка связей между логическими блоками в ПЛИС остается за компилятором.
Классификация ПЛИС по типу хранения конфигурации.
SRAM-Based.
Это одна из самых распространенных разновидностей ПЛИС. Конфигурация ПЛИС хранится ячейках статической памяти, изготовленной по стандартной технологии CMOS.
Достоинство этой технологии – возможность многократного перепрограммирования ПЛИС. Недостатки – не самое высокое быстродействие, после включения питания прошивку нужно вновь загружать. Значит на плате должен еще стоять загрузчик, специальная микросхема FLASH или микроконтроллер – все это удорожает конечное изделие.
Flash-based.
В таких микросхемах хранение конфигурации происходит во внутренней FLASH памяти или памяти типа EEPROM. Такие ПЛИС лучше тем, что при выключении питания прошивка не пропадает. После подачи питания микросхема опять готова к работе. Однако, у этого типа ПЛИС есть и свои недостатки. Реализация FLASH памяти внутри CMOS микросхемы – это не очень просто. Требуется совместить два разных техпроцесса для производства таких микросхем. Значит они получаются дороже. Кроме того, такие микросхемы, как правило, имеют ограниченное количество циклов перезаписи конфигурации.
Antifuse.
Специальная технология по которой выполняются однократно программируемые ПЛИС. Программирование такой ПЛИС заключается в расплавлении в нужных местах чипа специальных перемычек для образования нужной схемы.
Недостаток – собственно программировать / прошивать чип можно только один раз. После этого исправить уже ничего нельзя. Сам процесс прошивки довольно не быстрый. Зато есть масса достоинств у таких ПЛИС: они довольно быстрые (могут работать на больших частотах), меньше подвержены сбоям при радиации – все из-за того, что конфигурация получается в виде перемычек, а не в виде дополнительной логики, как у SRAM-based.
Конфигурируемые логические блоки.
В документации компании Альтера встречается выражение Logic Array Block (LAB) – массив логики. У компании Xilinx в микросхемах ПЛИС есть примерно такие же блоки – Configurable Logic Block (CLB). Конфигурируемый логический блок – это базовый элемент в ПЛИС, в нем может быть выполнена какая-то простая логическая функция или реализовано хранение результата вычисления в регистрах (триггерах).
Сложность и структура конфигурируемого логического блока (CLB) определяется производителем.
Теоретически, конфигурируемый логический блок может быть, например, очень простым, просто как отдельный транзистор. Или он может быть очень сложным, как целый процессор. Это крайние точки реализации.
В первом случае потребуется огромное число программируемых связей, чтобы потом из отдельных транзисторов собрать требуемую схему. Во втором случае связей может нужно и не так много, но теряется гибкость проектирования пользовательской схемы.
Именно поэтому конфигурируемый блок обычно представляет из себя что-то среднее: он обычно достаточно сложен, чтобы можно было бы зашить туда некоторую функцию, но и довольно мал, чтобы разместить множество таких блоков внутри ПЛИС и чтобы была возможность связать их в единую схему.
Таким образом, выбор структуры конфигурируемого логического блока производителем ПЛИС – это всегда поиск компромиса по площади кристалла, по быстродействию, энергопотреблению и так далее.
Конфигурируемый логический блок может состоять из одного или нескольких базовых логических элементов. В англоязычной литературе это Basic Logic Element (BLE) или просто Logic Element (LE). В ПЛИС обычно используются так называемые LUT-based базовые логические элементы. Что-то вроде этого:
Рис. 1. Пример традиционного базового логического элемента.
LUT – это Look-Up Table, таблица преобразования. Например, на Рис.1 показан четырехбитный LUT в составе базового логического блока. Здесь четырехбитному числу на входе логической функции ставится в соответствие однобитный результат. Красные квадратики на Рис. 1 обозначают программируемый элемент, регистр – это та память, где хранится прошивка для ПЛИС. Видно, что для конфигурации 4-х битного LUT требуется 16 конфигурационных регистра. Содержимое этих регистров определяют логическую функцию, реализованную внутри базового логического элемента.
Еще один конфигурационный регистр (на Рис. 1 это одиночный красный квадратик справа) определяет нужно ли на выход базового логического элемента выдавать прямо значение с LUT или нужно выдать зафиксированное в D-триггере значение с LUT. Фиксация и хранение данных в цифровых схемах нужна практически в любом проекте.
Примерно такой логический элемент использовался в моем экспериментальном проекте «ПЛИС внутри ПЛИС».
Рассматривая Рис. 1 как пример традиционного базового логического элемента понимаешь какая избыточность заложена внутрь современного кристалла ПЛИС (SRAM-based). Ведь в самом деле, конфигурационные регистры (красные квадратики) прямо не доступны для использования в цифровом проекте. Они только служат для формирования пользовательской функции. Для одного D-триггера в пользовательском проекте требуется более 16 (иногда много больше) триггеров для хранения конфигурации ПЛИС.
На самом деле базовый логический элемент в разных ПЛИС оказывается гораздо сложнее, чем показано на Рис. 1. Ниже есть некоторые примеры из документации на разные типы ПЛИС.
Рис. 2. Базовый логический элемент CPLD MAX II компании Альтера.
Здесь хорошо видны LUT и D-Триггер хранения результата. Ниже, на Рис. 3 представлен базовый элемент Cyclone III.
Рис. 3. Базовый логический элемент FPGA Cyclone III компании Альтера.
В микросхемах Альтеры в одном LAB может содержаться 10-16 LE.
В микросхемах компании Xilinx Virtex-6 базовый логический элемент – это так называемый Slice. В одном CLB всего два Slice. Зато один Slice – это довольно сложное устройство:
Рис. 4. Базовый элемент Xilinx Virtex-6 Slice.
В одном CLB Virtex-6 имеется 8 LUT и 16 D-Триггеров и еще кое-что плюс к этому. Вот так все сложно.
Другая крайность – микросхемы FPGA компании Microsemi (бывшая Actel).
Например, в микросхемах серии 40MX базовый логический элемент выглядит вот так:
Рис. 5. Logic Module of Microsemi 40MX serie.
Восемь входов и один выход.
Здесь нет ни Look-Up Table, ни даже D-Триггера. Триггера, как и остальная логика, формируются где нужно из вот таких крошечных кирпичиков – Logic Module.
Почему у разных компаний получилась такая большая разница в реализации базового логического элемента? Видимо в микросхемах Microsemi связь между базовыми блоками обходится гораздо дешевле: серия 40MX является однократно программируемой. В ней межблочные связи «проплавляются» между соединяющими дорожками и позже не могут быть изменены. Нет никаких регистров для временного хранения прошивки. Здесь нет программируемых переключателей, мультиплексоров, как в FPGA других типов. Ну микросхемы компании Microsemi – это несколько особый случай. Это технология называется antifuse – для производства таких микросхем используется модифицированный техпроцесс CMOS с дополнительными слоями для организации межблочных связей.
Программируемые связи между логическими блоками.
Чтобы в ПЛИС заработала нужная нам цифровая схема мало того, что нужно сконфигурировать имеющиеся логические блоки особым образом, еще нужно создать, запрограммировать связи между логическими блоками.
Для этого в ПЛИС имеются специальные конфигурируемые коммутаторы.
В англоязычной документации встречаются следующие термины: FPGA Routing Architecture и Programmable Routing Interconnect. Это все об этом, о программируемых связях между логическими блоками.
Известно две основных методики построения ПЛИС по типу архитектуры связей: островная и иерархическая.
Рис. 6. Островная ПЛИС.
Островная ПЛИС называется так потому, что конфигурируемые блоки все равны между собой и находятся, как острова в океане, между узлами коммутации и линиями связи.
Здесь, на Рис. 6 обозначаются CB – Connection Box и SB – Switch Box. В сущности это программируемые мультиплексоры, подключающие тот или иной CLB к другому CLB через цепочки проводов в ПЛИС.
Это island-style FPGA или mesh-based FPGA. Типичный пример таких микросхем – это серии Altera Cyclone и Stratix.
Второй известный тип ПЛИС – это иерархические ПЛИС. Здесь идет расчет на то, что в схеме всегда есть участки которые взаимодействуют друг с другом более тесно, чем с отдаленными модулями проекта.
Рис. 7. Иерархическая ПЛИС.
Здесь близлежащие CLB соединить довольно просто, нужно не много коммутаторов и получающиеся связи работают быстро. Вот если нужен более крупный блок вычислителей, то сигнал должен выйти на более высокий уровень иерархии и потом зайти вглубь в соседнюю «комнату».
Нельзя сказать, что это существенно хуже, чем island-style. Просто каждый метод имеет свои плюсы и минусы.
Типичные представители иерархических ПЛИС – это микросхемы компании Альтера серии Flex10K, APEX.
Программное обеспечение для проектирования ПЛИС.
Программное обеспечение для проектирования ПЛИС, а именно компилятор (синтезатор логики и фиттер и ассемблер) – это, возможно, самая сложная часть всей ПЛИС технологии.
Компилятор должен проанализировать пользовательский проект (схемы и текстовые описания на Verilog HDL или VHDL ) и сгенерировать нетлист (netlist) – список всех элементов схемы и связи между ними. Netlist должен быть оптимизирован – логические функции нужно минимизировать, возможные дублированные регистры нужно удалить.
Затем компилятор должен вместить всю логику из netlist в имеющуюся архитектуру ПЛИС. Это делает фиттер (fitter). Он размещает логические элементы и выполняет трассировку связей между ними (процесс place and route). Сложность состоит в том, что один и тот же проект может быть размещен в ПЛИС разными способами и этих способов миллионы. Некоторое размещение и трассировка оказываются лучше, другие хуже. Главный критерий качества полученной системы – максимальная частота, на которой сможет работать проект при данном размещении элементов и при данной трассировке связей. Здесь оказывает влияние длина связей между логическими блоками и количество программируемых коммутаторов между ними.
Компилятор, зная архитектуру ПЛИС по результатам работы дополнительно выдает отчет о времени прохождении сигналов от регистра до регистра. Эта информация часто бывает полезной для разработчика высокопроизводительных систем. Разработчик для ПЛИС имеет возможность давать некоторые советы компилятору где, в каком месте кристалла лучше разместить тот или иной модуль проекта.
Выбирая для своего проекта, для своей платы конкретную микросхемы ПЛИС разработчик в некоторой мере попадает в зависимость от производителя этой ПЛИС, так как должен в работе пользоваться программным обеспечением от этого же производителя.
Программное обеспечение компании Альтера: Quartus II.
ПО Xilinx для проектирования для ПЛИС: ISE Suite, Vivaldo Design Suite.
ПО компании Microsemi: Libero IDE, Libero SoC.
Возможно, программное обеспечение, компиляторы для ПЛИС – это важнейшая составляющая интеллектуальной собственности компаний производителей ПЛИС.
На страницах нашего сайта https://marsohod.org мы уделяем внимание прежде всего проектированию систем на базе ПЛИС компании Альтера и пользуемся средой разработки Altera Quartus II.
marsohod.org
ПЛИС (FPGA) и микроконтроллер. В чем разница? — МикроПрогер
Altera-Cyclone and Arduino
Каждый начинающий микропрогер на определенном этапе своего развития задается вопросом в чем же разница между ПЛИС (фирм Altera или Xilinx) и микроконтроллером (микропроцессором)?
Читаешь форумы — знатоки дела пишут, что это совершенно разные вещи, которые нельзя сравнить, аргументируя это тем, что у них разная архитектура. Читаешь мануал по Verilog или C++ — и тот и другой используют похожие операторы со схожим функционалом, даже синтаксис похож, а почему разные? Заходишь на марсоход — там светодиодами (или даже просто лампочками) с помощью FPGA моргают, смотришь проекты на Arduino — там роботами управляют. СтОп!
А вот теперь остановимся и спросим себя: почему с ПЛИС — тупо лампочка, а Ардуино — умно робот? Ведь и первый и второй вроде как программируемое устройство, неужели у ПЛИС возможностей для робота не хватает?
В какой-то степени суть вопроса «В чем разница между ПЛИС и микроконтроллером?» раскрывается именно на таком примере.
Отметим сразу. Функционал ПЛИС изначально не уступает микроконтроллеру (и микропроцессору, кстати, тоже), точнее — основные функции у одного и второго по сути идентичны — выдавать логические 0 или 1 при определенных условиях, а если говорить о быстродействии, количестве выводов(ножек) и возможностях конвейерной обработки, то микроконтроллеру до ПЛИСа вообще далеко. Но есть одно «но». Время на разработку одного и того же программного алгоритма на двух разных устройствах (ПЛИС и микроконтроллер) различается в разы, а то и в десятки раз. Именно ПЛИС здесь в 99% случаев сильно уступает МК. И дело вовсе не в замороченности языков Verilog, VHDL или AHDL, а в устройстве самой ПЛИС.
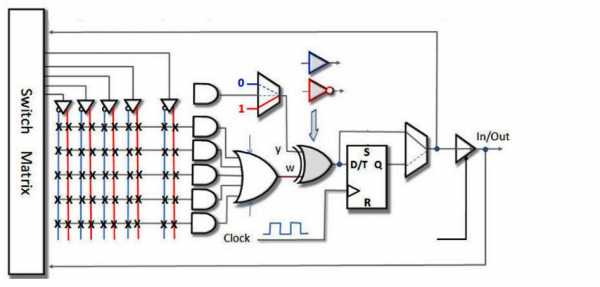
FPGA: в ПЛИС и нет сложных автоматизированных цепочек(делающих часть работы за вас). Есть только железные проводные трассы и магистрали, входы, выходы, логические блоки и блоки памяти. Среди трасс есть особый класс — трасса для тактирования(привязанная к определенным ножкам, через которые рекомендуется проводить тактовую частоту).
Основной состав:
Трасса — металл, напаянный на слои микросхемы, является проводником электричества между блоками.
Блоки — отдельные места в плате, состоящие из ячеек. Блоки служат для запоминания информации, умножения, сложения и логических операций над сигналами вообще.
Ячейки — группы от нескольких единиц до нескольких десятков транзисторов.
Транзистор — основной элемент ТТЛ логики.
Выводы (ножки микросхемы) — через них происходит обмен ПЛИС с окружающим миром. Есть ножки специального назначения, предназначенные для прошивки, приема тактовой частоты, питания, а так же ножки, назначение которых устанавливаются пользователем в программе. И их, как правило, гораздо больше, чем у микроконтроллера.
Тактовый генератор — внешняя микросхема, вырабатывающая тактовые импульсы, на которых основывается большая часть работы ПЛИС.
Трассы подключаются к блокам с помощью специальных КМОП-транзисторов. Эти транзисторы способны сохранять свое состояние(открытое или закрытое) на протяжении длительного периода времени. Изменяется состояние транзистора при подаче сигнала по определенной трассе, которая используется только при программировании ПЛИС. Т.е., в момент прошивки осуществляется именно подача напряжения на некоторый набор КМОП-транзисторов. Этот набор определяется прошивочной программой. Таким образом происходит сложное построение огромной сети трасс и магистралей внутри ПЛИС, связывающей сложным образом между собой огромное количество логических блоков. В программе вы описываете какой именно алгоритм нужно выполнять, а прошивка соединяет между собой элементы, выполняющие функции, которые вы описываете в программе. Сигналы бегают по трассе от блока к блоку. А сложный маршрут задается программой.
Архитектура ПЛИС (FPGA)
В этом элементе ТТЛ логики все операции по обработкам отдельных сигнальчиков проводятся независимо от вас. Вы лишь указываете что делать с тем или иным набором принятых сигналов и куда выдавать те сигналы, которые нужно передать. Архитектура микроконтроллера состоит совсем из других блоков, нежели ПЛИС. И связи между блоками осуществляются по постоянным магистралям(а не перепрошиваемым). Среди блоков МК можно выделить основные:
Постоянная память (ПЗУ) — память, в которой хранится ваша программа. В нее входят алгоритмы действий и константы. А так же библиотеки(наборы) команд и алгоритмов.
Оперативная память (ОЗУ) — память, используемая микроконтроллером для временного хранения данных(как триггеры в ПЛИС). Например, при вычислении в несколько действий. Допустим, нужно умножить первое пришедшее число на второе(1-е действие), затем третье на четвертое(2 действие) и сложить результат(3 действие). В оперативную память при этом занесется результат 1 действия на время выполнения второго, затем внесется результат 2 действия. А затем оба этих результата пойдут из оперативной памяти на вычисление 3 действия.
Процессор — это калькулятор микроконтроллера. Он общается с оперативной памятью, а так же с постоянной. С оперативной происходит обмен вычислениями. Из постоянной процессор получает команды, которые заставляют процессор выполнять определенные алгоритмы и действия с сигналами на входах.
Средства (порты) ввода-вывода и последовательные порты ввода-вывода — ножки микроконтроллера, предназначенные для взаимодействия с внешним миром.
Таймеры — блоки, предназначенные для подсчета количества циклов при выполнении алгоритмов.
Контроллер шины — блок, контролирующий обмен между всем блоками в микроконтроллере. Он обрабатывает запросы, посылает управляющие команды, организовывает и упорядочивает общение внутри кристалла.
Контроллер прерываний — блок, принимающий запросы на прерывание от внешних устройств. Запрос на прерывание — сигнал от внешнего устройства, информирующий о том, что ему необходимо совершить обмен какой-либо информацией с микроконтроллером.
Внутренние магистрали — трассы, проложенные внутри микроконтроллера для информационного обмена между блоками.
Тактовый генератор — внешняя микросхема, вырабатывающая тактовые импульсы, на которых основывается вся работа микроконтроллера.
В микроконтроллере, в отличии от ПЛИС, работа происходит между вышеперечисленными блоками, имеющими сложную архитектуру, облегчающую процесс разработки программ. При прошивке вы изменяете только постоянную память, на которую опирается вся работа МК.
Архитектура микроконтроллера
ПЛИС прошивается на уровне железа, практически по всей площади кристалла. Сигналы проходят через сложные цепочки транзисторов. Микропроцессор же прошивается на уровне программы для железа, сигналы проходят группами, от блока к блоку — от памяти к процессору, к оперативной памяти, от оперативной к процессору, от процессору к портам ввода-вывода, от портов ввода-вывода к оперативной памяти, от оперативной памяти… и так далее. Вывод: за счет архитектуры ПЛИС выигрывает в быстродействии и более широких возможностях конвеерной обработки, МК выигрывает в простоте написания алгоритмов. За счет более простого способа описания программ, фантазия разработчика Микроконтроллера менее скованна временем на отладку и разработку, и, таким образом, время на программирование того же робота на МК и ПЛИС будет отличаться во многие и многие разы. Однако робот, работающий на ПЛИС будет гораздо шустрее, точнее и проворнее.
В ПЛИС всю работу нужно делать самому, вручную: для того, чтобы реализовать какую-либо программу на ПЛИС, нужно отследить каждый сигнальчик по каждому проводку, приходящему в ПЛИС, расположить какие-то сигнальчики в ячейки памяти, позаботиться о том, чтобы в нужный момент именно к этим ячейкам памяти обратился другой сигнальчик, который вы так же отслеживаете или даже генерируете, и в итоге набор сигнальчиков, задержанный в памяти задействовал нужный вам сигнальчик, который, например, пойдет на определенную выходную ножку и включит светодиодик, который к ней подключен. Часть сигнальчиков идет не в память, а например на запуск определенной части алгоритма(программы). То есть, говоря языком микропрогера, эти ножки являются адресными. Например, имеем на нашей плате в нашей программе три адресные ножки для включения неких не связанных(или связанных) друг с другом алгоритмов, которые мы реализовали на языке Verilog в ПЛИС. Также в программе, кроме трех адресных ножек, у нас есть еще например 20 информационных ножек, по которым приходит набор входных сигнальчиков(например с разных датчиков) с какой-либо информацией (например температура воды в аквариуме с датчика температуры воды в аквариуме). 20 ножек = 20 бит. 3 ножки -3 бита. Когда приходит адресный сигнал 001(с трех ножек адреса) — запускаем первый алгоритм, который записывает 20 информационных сигнальчиков в 20 ячеек памяти(20 триггеров), затем следующие 20 сигнальчиков умножаем на полученные ранее 20, а результат умножения записываем в память, а потом отсылаем по другим ножкам например в терморегулятор воды в аквариуме. Но Отошлем мы этот результат только тогда, когда на наши адресные ножки придет код например 011 и запустит алгоритм считывания и передачи. Ну, естественно «отсылаем», «считываем» и еще что-то прописываем в ручную. Ведем каждый сигнальчик в каждый такт работы ПЛИС по определенному пути, не теряем. Обрабатываем или записываем. Складываем или умножаем. Не забываем записать. Не забываем принять следующий сигнал и записать в другие триггеры. Еще добавьте сюда работу, привязанную к тактовой частоте, синхронизацию (которая так же реализуется вручную), неизбежные ошибки на этапах разработки и отладки и кучу других проблем, которые в данной статье рассматривать просто бессмысленно. Трудно. Долго. Но зато на выходе работает супер оперативно, без глюков и тормозов. Железно!
Теперь микроконтроллер. 20 ножек на прием информации — для большинства микроконтроллеров физически невозможная задача. А вот 8 или 16 — да пожалуйста! 3 информационных — в легкую! Программа? По адресу 001 умножить первое пришедшее число на второе, по адресу 011 отсылай результат в терморегулятор. Все! Быстро. Легко. Не супер, но оперативно. Если очень грамотно написать программу- без глюков и тормозов. Программно!
Железо и Программа! Вот главное отличие между ПЛИС и Микроконтроллером.
В микроконтроллере большинство замороченных, но часто используемых алгоритмов уже вшиты железо(в кристалл). Нужно лишь вызвать программным способом нужную библиотеку, в которой этот алгоритм хранится, назвать его по имени и он будет делать всю грязную работу за вас. С одной стороны это удобно, требует меньшего количества знаний о внутреннем устройстве микросхемы. Микрик берет на себя заботу об отслеживании принятых, генерируемых и результирующих сигналов, об их складировании, обработке, задержке. Все делает сам. В большинстве микропрогерских задач это то, что нужно. Но если безграмотно использовать все эти удобства, то возникает вероятность некорректной работы. Железо и Программа!
Заключение
Современные разработчики процессоров и микропроцессоров изначально разрабатывают свои устройства на ПЛИС. Да-да, вы правильно догадываетесь: сначала они имитируют создаваемую архитектуру микроконтроллера с помощью разработки и прошивки программы на ПЛИС, а затем измеряют скорость выполнения алгоритмов при том или ином расположении имитируемых блоков МК и том или ином наборе функционала каждого блока отдельно.
По характеристикам выдаваемого сигнала, ПЛИС чаще всего рассчитана на 3,3В, 20мА, Микроконтроллер на 5В, 20мА.
Под микроконтроллер AVR, успешно внедренный в платформу Arduino, написано множество открытых программ, разработано великое множество примочек в виде датчиков, двигателей, мониторчиков, да всего, чего только душе угодно! Arduino в настоящее время больше похож на игровой конструктор для детей и взрослых. Однако не стоит забывать, что ядро этого конструктора управляет «умными домами», современной бытовой электроникой, техникой, автомобилями, самолетами, оружием и даже космическими аппаратами. Несомненно, такой конструктор будет являться одним из лучших подарков для любого представителя сильной половины человечества.
В принципе, все просто!
Остались вопросы? Напишите комментарий. Мы ответим и поможем разобраться =)
Автор публикации
не в сети 4 месяца
wandrys
877 Комментарии: 0Публикации: 31Регистрация: 17-03-2016micro-proger.ru
понятие, определение, правила программирования и основы для начинающих
ПЛИС (FPGA) расшифровывается как “Field Programmable Gate Array” и представляет собой огромный массив вентилей, которые могут быть запрограммированы и перестроены в любое время и в любом месте. Многие пользователи до сих пор не понимают, что такое ПЛИС. «Огромный набор ворот» — упрощенное описание модели. Некоторые FPGA имеют встроенные жесткие блоки: контроллеры памяти, высокоскоростные коммуникационные интерфейсы и конечные точки PCIe. Внутри FPGA много вентилей, которые можно свободно соединить вместе. Принцип работы более или менее похож на подключение отдельных микросхем логических элементов. FPGA выпускаются ведущими компаниями мира Xilinx, Altera, и Microsemi.
История развития FPGA
Индустрия ПЛИС выросла из программируемой постоянной памяти PROM и логических устройств PLD. В 1970 г. Philips изобрел программируемую в полевых условиях матрицу. В конструкции такой ПЛИС, что состояла из двух планов, достигалась специфическая реализация логических схем: программируемая проводная “И” либо “ИЛИ”. Это давало ей возможность реализации функции в виде Sum of Products.
Altera была создана в 1983 году, а уже в 1984 году выпустила первое в отрасли перепрограммируемое логическое устройство — EP300 с кварцевым окном в упаковке, что позволило использовать ультрафиолетовую лампу на матрице для удаления EPROM метки.
Чтобы преодолеть трудности стоимости и скорости, была разработана программируемая логика массива, в которую входил только один программируемый «И», вводимый в фиксированные «ИЛИ» ворота. PAL и PLA вместе с другими вариантами группируются как простые программируемые логические устройства SPLD. Такие ПЛИС, что интегрированы в один чип с предоставленными межсоединениями для программного соединения блоков, использовались для удовлетворения растущих технологических требований. Они названы комплексными PLD и разработаны Altera.
Транзисторы — другой класс электронных устройств, программируемых на основе масок массивов затворов. Они состоят из транзисторных массивов, которые могут быть подключены с помощью пользовательских проводов. Они уступили место логическим блокам, и теперь пользователь может выполнять настройку на месте, а не в производственной лаборатории.
Идея разработки первой коммерчески жизнеспособной ПЛИС принадлежит соучредителям Xilinx Россу Фримену и Бернарду Вондершмитту. XC2064 был изобретен в 1985 году и состоял из 64 настраиваемых логических блоков с 3-мя справочными таблицами. Он дает современное понимание, что такое ПЛИС. Это было в конце 1980 года, когда предложенный Стивом Кассельман эксперимент по созданию компьютера с 6000000 перепрограммированных ворот нашел спонсоров в отделе надводных боевых действий ВМС США, а затем получил патент в 1992 году.

К концу 1990 года появилась большая конкуренция в производстве ПЛИС, тогда доля рынка Xilinx начала снижаться. Такие игроки, как Actel, Altera, Lattice, QuickLogic, Cypress, Lucent и SiliconBlue, заняли свою нишу на мировом рынке FPGA наряду с Xilinx. В 1997 году Адриану Томпсону удалось объединить программирование ПЛИСов и технологию генетического алгоритма с FPGA, начав новую эпоху Evolvable.
Сегодня ПЛИС стали достаточно доступными, в связи с чем продолжают завоевывать популярность на потребительских рынках. Они состоят из набора логических ячеек, называемых таблицами поиска LUT, окруженных межкомпонентной сетью, обеспечивающей гибкую систему, которая может реализовать практически любой цифровой алгоритм.
Принципы программирования
Программирование ПЛИС для начинающих — это процесс изучения, планирования, проектирования и реализации решения на FPGA. Количество и тип планировки варьируются от программы к программе. Создание документа с требованиями и создание документа с дизайном, с объяснением, как будет реализовано предлагаемое решение, может быть очень полезным для решения потенциальных проблем.
Время, затраченное на создание качественного проектного документа, сэкономит его в будущем на рефакторинге, отладке и исправлении ошибок. Реализация решения с помощью программирования ПЛИС включает в себя создание проекта с использованием одного из методов введения проекта. Среди них схемы или код HDL, например, Verilog или VHDL. FPGA могут запрограммировать выходной файл на физическое устройство FPGA с использованием инструментов программирования ПЛИС Altera. Введение дизайна с применением схем больше не используется в промышленности. Синтез и программирования почти полностью позаботились об инструментах вендора, таких как инструменты конфигурации ISE и Vivado и Numato Lab.
Уровень передачи регистра RTL
RTL обозначает уровень передачи регистра. Разработчик также может столкнуться с терминами Register Transfer Logic или Register Transfer Language, все они означают одно и то же в контексте проектирования оборудования. RTL — это абстракция более высокого уровня для цифрового аппаратного дизайна, которая находится где-то между строго поведенческим моделированием на одном конце и чисто структурным на уровне шлюза — на другом.
Моделирование гейтов означает описание аппаратных средств с использованием базовых вентилей, что является достаточно утомительным. RTL можно рассматривать как аналог термина «псевдокод», используемого в основах программирования ПЛИС. Можно описать аппаратный дизайн как последовательность шагов или потока данных от одного набора регистров к следующему в каждом тактовом цикле.
RTL также называют дизайном «потока данных». Как только проект RTL готов, его легче превратить в реальный код HDL, используя такие языки, как Verilog, VHDL, SystemVerilog или любой другой язык описания оборудования.
ПЛИС — это гораздо больше, чем просто множество ворот. Хотя можно строить логические схемы любой сложности, организуя и соединяя логические элементы. Это способ выразить логику в простом формате, который в конечном итоге можно превратить в массив элементов. Два популярных метода сделать это: введение схемы и языка описания оборудования HDL. До того, как он стал широко используемым, инженеры проектировали все с помощью схем. Они были очень простыми для небольших проектов, но болезненно неуправляемыми — для крупных. Стоит только представить себе, как инженеры Intel рисуют схемы для Pentium, у которого миллионы шлюзов! Это неприемлемо сложно.
Verilog — это язык описания аппаратных средств HDL, который можно использовать для цифровых схем в текстовом виде. Изучение Verilog не так сложно, если у пользователя есть опыт программирования. VHDL является еще одним популярным HDL, широко используемым в отрасли. Verilog и VHDL имеют более или менее одинаковое признание на рынке, но пользователи обычно выбирают Verilog, поскольку он прост в изучении и имеет синтаксическое сходство с языком Си.
Технологии программирования
ПЛИС можно считать строительными блоками, которые позволяют осуществить нужную настройку оборудования. Это особая форма PLD с более высокой плотностью и расширенными возможностями функционала за более короткий промежуток времени с использованием CAD. ПЛИС доступны в различных вариантах на основе используемой технологии программирования.
Они могут быть запрограммированы с использованием:
- Antifuse Technology.
- Программирование на основе технологии Flash как устройства от Actel.
- FPGA может быть перепрограммирован несколько тысяч раз, что занимает несколько минут в самом поле для перепрограммирования и имеет энергонезависимую память.
ПЛИС на основе технологии SRAM, которая предлагает неограниченное перепрограммирование и очень быструю реконфигурацию или частичную реконфигурацию во время самой работы с небольшим количеством дополнительных схем. Большинство таких компаний, как Altera, Actel, Atmel и Xilinx, производят эти устройства.
Конфигурируемые логические блоки
Независимо от различных производителей и несколько разных архитектур и наборов функций, большинство FPGA имеет общий подход. Основными компонентными блоками любой FPGA являются гибкий программируемый «логический блок» (CLB), окруженный программируемыми «блоками ввода / вывода» с иерархией каналов маршрутизации, соединяющих различные блоки на плате.
Кроме того, они могут состоять из DLL-библиотек для распределения и управления часами и памяти RAM выделенного блока с основным строительным блоком логической ячейкой. Последняя состоит из генератора входных функций, логики переноса и элементов хранения. Генераторы реализуются в виде справочных таблиц и зависят от введения. Например, Xilinx Spartan II имеет 4 входных LUT с обеспечением каждого 16X1 битным синхронным ОЗУ с использованием мультиплексоров как регистров сдвига для захвата данных в пакетном режиме. Элементы хранения являются чувствительными к краям триггеров или к уровню задвижек.
Фрагмент программирования ПЛИСов:
- Арифметическая логика включает в себя вентиль XOR для работы с полным сумматором и выделением логических линий переноски.
- Блок ввода / вывода и матрица маршрутизации. Этот блок имеет входы и выходы, поддерживающих широкий спектр стандартов и интерфейсов сигнализации.
Базовый блок ввода / вывода показан ниже.
Буфера во входных и выходных путях направляют сигналы во внутреннюю логику и итоговые площадки непосредственно или через триггер. Они настраиваются на соответствие различным поддерживаемым стандартам сигнализации, которые могут быть определены пользователем и установлены извне.
Матрица маршрутизации
На любой сборочной линии медленный сегмент определяет общую производительность. Алгоритмы маршрутизации используются для разработки наиболее эффективных путей обеспечения оптимальной производительности. Маршрутизация осуществляется на разных уровнях, таких, как локальный, маршрутизация общего назначения между различными CLB, маршрутизация ввода-вывода между блоками и CLB, выделенная маршрутизация для определенных сигнальных классов с целью максимизации производительности и Global Routing для распределения тактовых и других сигналов с очень большим разветвлением. Семейства FPGA также имеют большие блочные структуры RAM для дополнения распределенных LUT RAM, размер которых варьируется для различных устройств FPGA.
Проектирование FPGA предполагает в основном тот же подход, что и любая система VLSI, основными этапами которой является проектирование, моделирование поведение, синтез, моделирование после синтеза, трансляция, отображение и маршрутизация, а также последующий анализ, такой как моделирование синхронизации и статический анализ синхронизации. На компьютере дизайн выглядит упорядоченным и уложенным плиткой, однако фактически имеется несовершенное размещение и маршрутизация, что приводит к снижению производительности.
Чтобы повысить производительность FPGA, всегда можно использовать больше транзисторов. Служебная площадь высокая. Установка большего количества транзисторов означает, что возможны масштабные конструкции. Утечка является серьезной проблемой для ПЛИС и в то же время представляет интерес. Использование асинхронной архитектуры FPGA показывает лучшие результаты в сочетании с технологией конвейерной обработки, которая уменьшает глобальные входы и улучшает пропускную способность.
Качество и проблемы ворот
Безопасность системы всегда была главной проблемой, так как код должен раскрываться каждый раз, когда загружался в ПЛИС. Такая гибкость делает FPGA потенциальной угрозой вредоносных модификаций при изготовлении, поэтому шифровании битовых потоков вовремя пришло ему на помощь.
Часто неопытные дизайнеры и пользователи сталкиваются с дилеммой, насколько мощная ПЛИС подходит для их разработок. Производители часто указывают метрики, например, «количество ворот». Например, программирование ПЛИС Xilinx использует 3 метрики для измерения объема FPGA, максимальных логических элементов, максимальных битов памяти и типового диапазона шлюзов. Пока они являются согласованными, миграция между моделями несколько упрощается, но она редко предлагает точное сравнение у различных поставщиков через разнообразие в архитектурах и из-за различий в производительности.
Наилучшим показателем является сравнение типа и количества предоставленных логических ресурсов. В дополнение к этому, разработчик должен полностью осознать, что именно нужно от устройства, поскольку производители могут похвастаться возможностями, которые будут иметь наименьшее значение для работы. Например, Stratix II EP2S180 от Altera имеет около 1,86,576 LUT с 4 входами, а Xilinx Virtex-4 XC4VLX200 содержит соответственно 1,78,176. Однако, если для проектирования нужна только 177 тыс. LUT, это будет достаточно.
Если ОЗУ – это желательная метрика для дизайнера, то ни 6 Мбит Xilinx XC4VLX200, ни 9 Мбит Altera EP2S180 не будут предпочтительнее по сравнению с менее рекламируемой, более старой моделью XC4VFX140 с 9,9 Мбит.
Языки программирования и ПО
Программирование ПЛИС Altera для начинающих стартует с выбора языка. Опция C, C ++ или System C позволяет использовать возможности крупнейших устройств и, в то же время, достижения сходства реалистической графики разработки. Возможность использования на базе C для проектирования FPGA обеспечивается HLS (синтез высокого уровня), который уже много лет находится на грани прорыва с таким инструментом, как Handle-C. В последнее время это стало реальностью благодаря тому, что крупные поставщики Altera и Xilinx предлагают HLS в своих наборах инструментов Spectra-Q и Vivado HLx соответственно.
Доступен ряд других реализаций программирования ПЛИС Altera для начинающих на основе C, таких как OpenCL, который предназначен для разработчиков программного обеспечения, желающих повышения производительности с помощью FPGA без глубокой понимание дизайна FPGA.
Как и в случае с HDL, HLS имеет ограничения при использовании подходов программирования ПЛИС на C также, как и с традиционными HDL, разработчикам приходится работать с подмножеством языка. Например, сложно синтезировать и реализовать системные вызовы, так как нужно убедиться, что все ограничено и имеет фиксированный размер. В HLS приятно то, что можно разрабатывать свои алгоритмы с плавающей запятой и имеется инструмент HLS преобразования плавающей запятой в фиксированную.
Программировать ПЛИС с ПО Xilinx совсем не сложно. Получить его можно, покупая продукты Xilinx, бесплатно или по цене, ориентированной на конкретные модели. Можно получить доступ к видео на профильном сайте, который наглядно показывает процедуру использования. Из всех компаний, которые можно выбрать при поиске программируемых вентильных массивов, Xilinx безусловно лучший из всех. Они являются создателями этого продукта, и в течение многих лет вносили в него улучшения. Фирменное ПО стало более мощным, чем когда-либо прежде.
Этапы проектирования
Обучение программированию ПЛИС можно проводить онлайн, поскольку платформа хорошо представлена в интернете. При настройке ПЛИС первым шагом является проектирование схемы, для которой необходимо знание цифровой электроники. В отличие от программирования, гораздо сложнее начать нарезку кода, если архитектура программы не ясна. Как только станет ясно, что нужно реализовать, приступают к описанию схемы, используя один из языков: Verilog или VHDL.
Факт, который свидетельствует об изменении парадигмы, состоит в том, что они не называются языками программирования ПЛИС, а являются языками описания. Из-за сложности тестирования цифровых схем обычно на этом этапе используются банки тестов, моделирующих поведение оборудования. Этот тип инструментов позволяет видеть состояние сигнала в любой момент и проверять, есть ли переходы с желаемыми результатами.

Третий этап известен как синтез схемы является одним из ключевым. Он выбирает используемые элементы и их взаимосвязь в соответствии с файлами описания. Для этого этапа требуются инструменты, которые в большинстве ситуаций облегчают и автоматизируют задачи.
Аппаратные средства и наладка
Intel Quartus Prime Software Suite Lite Edition — программное обеспечение для проектирования ПЛИС. Оно идеально подходит для начинающих, так как его можно скачать бесплатно, а файл лицензии не требуется. Можно загрузить программное обеспечение на сайте производителя. Файлы имеют большой размер (несколько гигабайт), их загрузка и установка может занять много времени. Чтобы минимизировать время и необходимое дисковое пространство, рекомендуется загружать только те элементы, которые необходимы для пользовательских задач. При запросе, файлах для загрузки, снимают флажок «Select All» и выбирают только Quartus Prime и поддержку Cyclone V устройства.
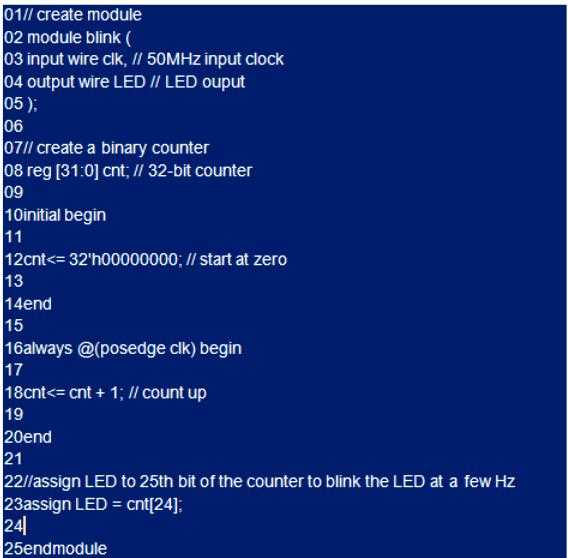
Алгоритм создания проекта:
- Открывают Мастер нового проекта.
- Выбирают Next > Каталог > Имя > объект верхнего уровня.
- Выбирают каталог для размещения проекта, например, «Blink» и помещают его в папку intelFPGA_lite, но можно разместить его где угодно и нажимают «Далее».
- Когда будет предложено создать каталог, выбирают «Да».
- Выбирают «Пустой проект» и нажимают «Далее».
- Добавляют файлы и «Далее».
- Настраивают семейства, устройства и платы, выбирая следующее: семья – Циклон V, устройство – Циклон V SE, база, название устройства: 5CSEBA6U2317.
- Чтобы выбрать конкретное устройство, нужно нажимать стрелки вверх / вниз, чтобы увидеть список поддерживаемых устройств, пока не появится 5CSEBA6U2317.
- Пользователю может понадобиться расширить поле «Имя», чтобы увидеть полное имя устройства, нажать «Далее».
- При настройке инструмент EDA, используют стандартные инструменты, поэтому никаких изменений не будет, нажимают «Далее» и «Готово». Появится экран резюме.
- Создают файл HDL с внедрением Verilog в качестве HDL.
- Переходят на вкладку File (главное окно) и выбирают New.
- Выбирают Verilog HDL File и нажимают кнопку ОК.
- Выбирают «Файл»> «Сохранить как».
- Выбирают имя файла. Это имя файла верхнего уровня, и оно должно совпадать с именем проекта.
- Нажимают «Сохранить».
- Создают модуль Verilog.
- Копируют и вставляют ниже размещенный код Verilog в окно blink.v, а затем сохраняют файл кода.
- Нажимают правой кнопкой мыши «Анализ и синтез», а затем нажимают «Пуск», чтобы выполнить проверку синтаксиса и синтеза кода Verilog.
Если процесс завершается успешно, рядом с анализом и синтезом отображается зеленая галочка. Если ошибка, проверяют синтаксис и убеждаются, что он точно соответствует блоку кода, указанному выше.
Все опытные программисты знают, что сложные программы, даже подпрограммы, не работают правильно с первого раза. Способности к абстракции у человека, основанные на опыте, позволяют ему находить решения, не беспокоясь о мельчайших деталях. Но суровая правда заключается в том, что физическая система, в которую встраиваются программы, требует, чтобы каждая мелочь была учтена, прежде чем все заработает.
С улучшением программных инструментов для разработки ПЛИС в основном от традиционных поставщиков, а также независимых поставщиков инструментов: Synplicity, FPGA — становится день ото дня все более популярной. Теперь ПЛИС начали включать специализированное аппаратное обеспечение необходимых клиенту функций, снижая издержки производителей. Таким образом, в будущем может появиться конкуренция между жесткими и дешевыми системами с гибкими ядрами. Ожидается, что в ближайшей будущем расходы будут снижаться еще больше, поскольку популярность FPGA вырастет в разы.
Производители начали экспериментировать с таким понятием, как встраивание ПЛИС в интегральные микросхемы для создания гибридного устройства. Основное внимание по-прежнему уделяется маршрутизации межсоединений, а в архитектурах CLB наблюдаются меньшие изменения. Поскольку ПЛИС продолжают включать процессоры, новое поколение потребует не только знаний аппаратного обеспечения цифрового дизайна, но и опыта разработчиков в процессе однократного программирования ПЛИС. В целом, ожидается, что FPGA отнимет долю рынка в устройствах ASIC и станет доминирующей технологией, охватывающей множество приложений из различных областей.
fb.ru
Сумбурные размышления о будущем технологии FPGA / Habr
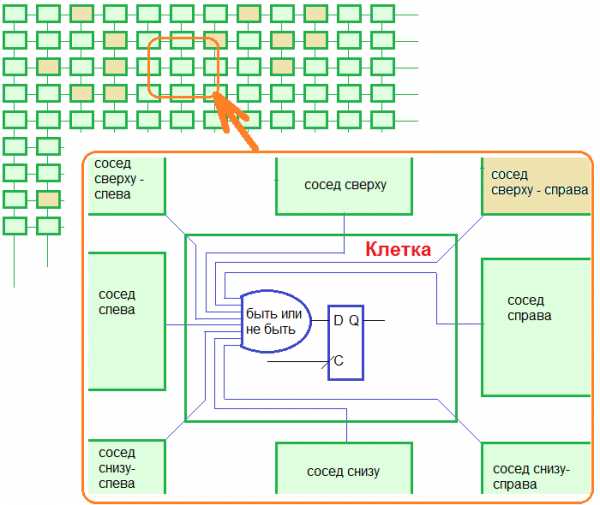
Работая над очередным игровым (обучающим) проектом ПЛИС для платы Марсоход2 я столкнулся с тем, что мне явно не хватает места в кристалле. Кажется и проект не очень сложный, но моя реализация такова, что требует много логики. В принципе, это ерунда, дело-то житейское. Ну, если очень будет нужно, то можно выбрать ПЛИС с большей емкостью. Собственно мой проект — это игра «Жизнь», но реализованная в ПЛИС на языке Verilog HDL.
Про логику игры, рассказывать не буду, про нее и так написано уже достаточно.
Идея проекта вот такая: каждая клетка в игровом поле представляет собой самостоятельный вычислитель. В каждом вычислителе есть своя логическая функция и свой регистр, который хранит текущее состояние клетки (живая/не живая). Все пространство для жизни клеток — это двумерный массив вычислителей, вычислители образуют целую сеть. Все вычислители работают синхронно, так как на все регистры подается единая тактовая частота. Рисунок вверху должен прояснить схему проекта.
Так вот. На моей плате стоит ПЛИС Cyclone III EP3C10E144C8 компании Альтера. 10тыс логических элементов. Сперва я думал, что смогу сделать двумерный массив клеток 128×64=8192 клетки. Не помещается. 64×64=4096 — то же не помещается в кристалл. Как же так. Я сумел вместить в ПЛИС только 32×16=512 клеток. Пичалька…
Размышления приводят меня к мысли, что возможно, в будущем, технология ПЛИС перерастет в нечто большее, чем программируемая логика. Вот об этом своем видении я хотел бы рассказать. Искушенному читателю сразу скажу, что многое далее написанное есть просто плод воображения и может быть даже бред.
Однако..
В настоящее время технология ПЛИС используется довольно узким кругом специалистов. В основном FPGA используются для прототипирования микросхем и для мелкосерийных изделий, когда изготовление микросхем ASIC экономически нецелесообразно. Специалистов по FPGA, я думаю, не очень много. Технология довольно сложная и требует многих специфических знаний. С другой стороны, для организации высокоскоростных и параллельных вычислений ПЛИС — это пожалуй самая подходящая технология.
Мы знаем, например, что компания Альтера предлагает и продвигает технологию OpenCL
Просто говоря — это такой C-подобный язык для описания параллельных вычислений в FPGA акселераторе. Кстати, Nvidia и ее видеокарты так же поддерживают параллельные вычисления c OpenCL.
Таким образом, видно, что Альтера явно задумываются о том, как донести «обычные» C-подобные параллельные вычисления FPGA в народ. Посмотрим, что там с ценами на платы для параллельных вычислений с FPGA? Плата Terasic DE5-Net.
25 пользователям нравится цена 8 тыс баксов (шучу).
Есть и другие попытки привезти FPGA в народ — Altera выпустила совместно с Intel микросхему серии E6x5C, где в едином корпусе соединен процессор Atom и ПЛИС Arria II. Хорошая попытка, но технология так кажется и не смогла найти массового потребителя.
Видимо существующие кристаллы ПЛИС плохо вписываются в современную парадигму программирования.
А какая у нас сейчас современная парадигма «нормального» программирования?
Мне кажется, что как-то так:
- на компьютере всегда одновременно исполняется несколько вычислительных процессов и потоков
- состояние процессов и потоков хранится в памяти, процесс может запросить у ОС столько памяти, сколько нужно; можно даже попросить больше, чем есть физической памяти — и процесс может реально получить эту виртуальную память.
- вычисления производятся процессором, иногда он имеет много ядер. Обычно процесс или поток не знают (или не хотят знать) в каком ядре процессора сейчас исполняется задача.
- более приоритетная задача может вытеснить менее приоритетную задачу. Вытеснить — это значит сохранить состояние страниц памяти вялого процесса на диск и переключиться на более приоритетный процесс. Выделить ему больший слайс времени.
Понятно, что чем больше памяти и чем больше ядер процессора, тем быстрее работают все процессы в системе.
Память и ядра процессора — это ресурсы компьютера, вычислителя, которые операционная система распределяет между процессами.
Теперь представим себе, что в будущем мы получим компьютеры, где на ряду с памятью и ядрами процессора будут иметься в наличии еще блоки логики «как-бы-плис». Этот ресурс «как-бы-плис» по своим свойствам находится где-то между процессором и памятью. С одной стороны «как-бы-плис» = это вычислитель, то есть ближе к процессору, но с другой стороны это и память, ибо в регистрах плис хранится довольно много информации. Состояние вычислителя «как-бы-плис» уже довольно трудно будет сохранить в структуре task_struct при переключении контекста задачи. Но, наверное, можно попытаться вытеснить состояние блоков логики в swap файл, как виртуальную память. И временно ОС может подгрузить другие блоки логики для активного потока…
Кстати, и Altera и Xilinx уже довольно давно имеют FPGA с возможностью частичной перезагрузки отдельных участков, блоков логики (Partial Reconfiguration) — то есть в принципе они как-то идут в эту сторону…
Программист может выделить для процесса столько «как-бы-плис», сколько нужно. Буквально функцией lalloc (logic alloc) по аналогии с malloc (memory alloc). Потом из файла считать туда «прошивку ПЛИС» и она будет жить и работать. Мы, программисты, по большому счету не должны думать есть эта память/логика «как-бы-плис» у системы или ее нет. А не наше это дело. Да, иногда может быть очень медленно при ограниченных ресурсах, но разве мы не знаем как «лагают» видеоигры на слабых видеокартах? Пользователи знают, что за сильное железо придется платить, но хорошо бы, чтоб даже минимальная система уже имела в базовом варианте логические блоки «как-бы-плис» для использования в программах.
На самом деле, конечно, я представляю себе, что такая технология вряд ли скоро появится, слишком все это сложно и не реализуемо. По крайней мере существующие микросхемы ПЛИС мало подходят для этих целей хотя бы потому, что для конфигурирования ПЛИС используются медленные последовательные интерфейсы типа JTAG. Но может быть, когда-то кто-то из нас сделает это?
ЗЫ: кстати, а вот и моя игра жизнь в ПЛИС, такая маленькая, 32×16… ну нет у меня виртуальной памяти «как-бы-плис», чтобы сделать поле игры шире и выше…
ЗЫ2: все исходники и подробное описание проекта игры Жизнь можно взять здесь.
habr.com
Первое знакомство с ПЛИС Xilinx.
РадиоКот >Обучалка >Микроконтроллеры и ПЛИС >Осваиваем ПЛИС Xilinx >Первое знакомство с ПЛИС Xilinx.
Итак, начну свое повествование о программируемой логике фирмы Xilinx, в котором постараюсь помочь начинающим с освоением этих замечательных микросхем. Начнем с самого главного – что эти микросхемы из себя представляют, и с чем их едят. Ну-с, приступим! Эта контора (Xilinx, разумеется) выпускает несколько семейств микросхем программируемой логики, предназначенных для различных целей и отличающихся между собой ценой и объемом (эквивалентным количеством логических вентилей). Микросхемы разделяются между собой на три основных группы: CPLD (CMOS Programmed Logic Device), FPGA (Field Programmed Gate Array) и конфигурационные ПЗУ для FPGA, разделенные между собой на три семейства – XC17xx, XC18xx и Platform Flash. Рассмотрим подробней что из себя представляют все эти группы и какие микросхемы в них входят.
Начнем с CPLD. Эти микросхемы отличаются наиболее простой структурой и значительными ограничениями при проектировании устройств на них, но у них есть и одно достоинство – им не нужно конфигурационное ПЗУ (что это такое – будет рассказано чуть позже). К ограничением относятся “жадность” на триггеры и недостаточная гибкость. Однако CPLD легки в освоении и, поэтому, идеально подходят для начала работы с ПЛИС вообще.
С FPGA дело обстоит несколько иначе – эти микросхемы гораздо сложнее устроены (некоторые даже содержат в себе по несколько процессорных ядер PowerPC), требуют наличия конфигурационного ПЗУ (это объясняется тем, что сами микросхемы построены по технологии Static RAM, то есть при каждом включении их нужно “загружать”), однако они способны вместить в себя гораздо более сложные и большие проекты, нежели CPLD и достаточно гибки для проектировщика (в частности снимается ограничение по количеству триггеров).
Конфигурационные ПЗУ предназначены для загрузки статической памяти FPGA. Семейство XC17xx – самое старое, представляет собой однократно программируемые микросхемы. XC18xx – EEPROM, а значит, их можно перепрограммировать многократно. Platform Flash – новое семейство конфигурационных микросхем, выполненных по технологии Flash ROM.
Архитектуру упомянутых выше микросхем мы не будем рассматривать в этой статье, потому что каждое семейство ПЛИС отличается собственной архитектурой и на это тему написано достаточно много книг, да и в даташите на любое семейство микросхем эта архитектура хорошо “разжевана”. А говорить мы здесь будем непосредственно о том, как начать работать с этими замечательными микросхемами.
Итак, начнем! Для начала нам понадобится собрать программатор и установить необходимое ПО на свой компьютер. Вот схема программатора:
Как видите – все просто и никаких мудреностей ненужно. Такой программатор позволяет работать с многими типам ПЛИС и конфигурационных ПЗУ Xilinx. Теперь о софте – основной продукт для разработке устройств на ПЛИС Xilinx – это Xilinx ISE. ISE существует в нескольких вариантах, однако доступней всех – дистрибутив ISE Webpack, который можно скачать отсюда, правда для этого придется зарегистрироваться. Денег никто просить не будет, поэтому все останутся довольны и никто не будет обманут. Итак, программатор собран, ISE установлен – можно начинать!
С чего же мы начнем? Чтобы начать проектировать на ПЛИС нам нужно определиться с микросхемой, на которой мы будем проектировать. Возьмем XC95144 – это КМОП ПЛИС, с архитектурой CPLD, с 5-и вольтовым вводом-выводом, содержащая 144 макроячейки. Макроячейка – это основной кирпичик CPLD. Каждая макроячейка содержит запоминающий элемент, который может быть запрограммирован как D-триггер или как тактируемый триггер-защелка, а может быть и не использован вовсе. Отсюда и такое ограничение по триггерам (144 макроячейки=144 триггера). Микросхема XC95144 поддерживает внутрисистемное программирование – то есть ее можно перепрограммировать сколько угодно (в пределах ее ресурса, конечно!) раз, прямо на плате, на которой она используется. Еще одно важное замечание – XC95144 производится в нескольких корпусах – TQFP-100, PQFP-100 и PQFP-160, которые отличаются распиновкой и количеством выводов, доступных для программирования пользователем. Мы будем рассматривать вариант микросхемы в корпусе PQFP-160. Вот так она выглядит:
Ну что, страшно? Да ничего страшного – бывают корпуса и пострашнее!
Ну а теперь, непосредственно приступим к делу! Запускаем ISE с помощью ярлыка на рабочем столе, который был создан инсталлятором. Открывается пустое окно с двумя боковыми панелями, рядом кнопок наверху и менюшкой. Зачем это все нужно – разберемся позже – сейчас нам нужно создать проект.
Выбираем в меню File->New Project, вводим имя проекта, путь, где наш проект будет располагаться и выбираем Top->Level Source Type->Schematic. Это означает, что основной модуль нашего проекта (в иерархической системе) будет введен в виде схемы.
Щелкаем Next – перед нами появляется окно с кучей параметров нашего проекта. Поле Product Category нас сейчас мало волнует (честно говоря, вообще не пойму, как оно отражается на проекте). Family – это семейство ПЛИС, с которым мы будем работать – выбираем 9500 CPLDs. Device – непосредственно микросхема, под которую будет создаваться проект – тут выбираем угадайте что? Правильно – XC95144! Package – тип корпуса у нашей микросхемы – выбираем PQ160. Speed – скоростной параметр микросхемы (на фотке микросхемы выше обозначен как 15С в самом низу. А вообще этот параметр обозначает минимальную задержку распространения сигнала в ПЛИС “контакт-контакт” в наносекундах. То есть в указанной микросхеме такая задержка равна 15нс – таким образом можно рассчитать максимальную тактовую частоту – около 66МГц. Остальные параметры касаются синтеза (процесса перегонки нашего проекта в вид, в котором он будет расположен на кристалле) и симуляции проекта. Выбираем XST в качестве Synthesis Tool, симулятор ISE Simulator (что характерно) и Preferred Language – VHDL. VHDL – потому что этот язык гораздо “ближе” к Xilinx, нежели Verilog.
Когда мы все заполнили – самое время нажать Next и добавить “головной” файл проекта в появившемся диалоге выбираем тип Schematic и вводим имя файла, пускай это будет main.sch. Далее нажимаем еще несколько раз Next, Finish и проект создан.
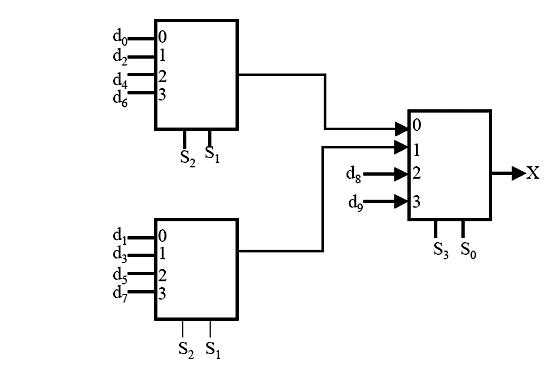
Что мы видим: пустое поле, где мы будем вводить схему, две панели с вкладками и окошко с консолью снизу. Сейчас нас интересует панель, на которой присутствуют четыре вкладки – Sources, Shapshots, Libraries и Symbols. Зайдем на вкладку Symbols – остальные нас пока не интересуют. Перед нами два списка – Categories и Symbols. Догадаться не сложно – в первой у нас находится список категорий символов (арифметика, буферы и т.п.) а во второй – сами символы. При выбранной категории All Symbols – в нижнем списке отображаются все символы, которые мы можем использовать в нашем проекте. Для разных семейств ПЛИС эти списки могут отличаться.
Попробуем построить какую-нибудь схему, например счетчик, считающий до 10. Для этого выберем категорию Counter, а в ней элемент – cb4ce. Выделив этот компонент мы можем “бросить” на схему сколь угодно таких счетчиков – прекратить это можно нажатием на правую кнопку мыши (появится контекстное меню) или выбором инструмента “стрелочка” на панели вверху. Итак, кидаем на схему один такой счетчик.
Для начала разберемся с назначением его выводов:
CE – вход разрешения счета, можно повесить на него какую-нибудь логику, а можно просто подтянуть на “плюс питания” с помощью компонента Vcc из категории General, что мы и сделаем.
С – собственно счетный вход нашего счетчика, сюда будем подавать тактовый сигнал.
CLR – асинхронный сброс счетчика, счетчик находится в состоянии сброса всегда, когда на этом входе присутствует логическая “1”.
Q0..Q3 – выходы счетчика, как несложно догадаться.
CEO – выход разрешения счета, его значение соответствует значению, поданному на вход CE – предназначен для каскадирования счетчиков
TC – окончание счета – при переполнении счетчика на этом выходе появляется лог. “1”.
Отлично, счетчик у нас есть, но он будет считать не до 10, как нам нужно а от 0 до 15 – значит нам понадобится цепь сброса. Спроектировать ее можно так: поставить логику на выход счетчика, которая будет отлавливать число “11” на его выходе и сразу при его появлении сбрасывать счетчик. Для этих целей нам хорошо подойдет компонент and4b3 – (b3 здесь означает, что 2 входа вентиля “И” в данном случае инверсные). Но мы пойдем иным путем, и вот почему. Допустим, счетчик у нас должен считать не до 10, а, скажем до 1234, а это 11 разрядов – придется городить логику, что не есть хорошо, когда все можно сделать просто и красиво. Воспользуемся компаратором. Выбираем категорию Comparator и компонент comp4. Компаратор работает просто – при равенстве чисел, поданных на входы A[1..4] и B[1..4] он выдает логическую единицу на своем единственном выходе EQ. Подсоединим входы “А” нашего компаратора к выходам счетчика, а выход компаратора соединим с входом асинхронного сброса счетчика. Для этого на панели сверху выберем инструмент Add Wire, нажав на кнопку, на которой нарисован карандаш рисующий провод. Итак, счетчик с компаратором у нас соединены, осталось подать число “11” на вход компаратора обозначенный как “В”. Можно просто подтянуть на питание и землю (c помощью компонентов vcc и gnd) входы компаратора, а можно сделать тоже самое с помощью компонента Constant из категории General. Бросим этот компонент на нашу схему. По умолчанию в него записана константа FFFF, но нам нужно записать туда число “В” в шестнадцатеричной системе счисления равное 11. Для этого два раза щелкнем мышкой на этом компоненте, чтобы отредактировать его свойства. В открывшемся окне нас интересует свойство Cvalue – туда запишем “В”, причем безо всяких нулей и нажмем “ОК”. После нажатия “ОК” мы видим на схеме, что значение константы равно “В”, то есть 11 в десятеричной системе. И тут мы сталкиваемся с одной трудностью: входов у компаратора четыре, а выход у константы всего один! Как быть? Дело в том, что выход компонента Constant представляет собой шину, этим-то мы и воспользуемся! Выберем уже знакомый инструмент Add Wire с помощью кнопки с карандашом и “соединим” нашу константу с пустым местом на схеме – просто немного “протянем от нее провод” и закрепим его двойным щелчком рядом с компонентом. Это и будет наша шина. Чтобы можно было работать с этой шиной – ей нужно присвоить имя. Выбираем инструмент Add Net Name, кнопкой, на которой нарисован провод с буквами “ABC” и на панели, на которой всего две вкладки (на скриншотах – слева) выбираем вкладку Options, где в поле Name вводим: “count_max(3:0)”
После ввода имени шины курсор стал выглядеть как крестик с надписью “count_max(3:0)” – подведем курсор к красному квадратику с края “провода” у компонента с константой и щелкнем. Таким образом мы только что присвоили имя шине, которая подключена у нас к компоненту constant. Теперь можно с помощью этой шины подключить константу ко входу “В” компаратора. Для этого уже знакомым образом соединим входы “В” компаратора с пустым местом на схеме. И с помощью инструмента присвоения имени цепи подключим компаратор к константе таким образом:
Итак, перед нами почти завершенная схема – теперь осталось создать порты для связи с внешним миром. В этом нам поможет инструмент Add I/O Marker. Выглядит он вот так: . Просто выбираем этот инструмент, щелкаем по квадратику радом с выводом “С” нашего счетчика и тут же вход счетчика становится портом. Осталось его только переименовать в нечто удобочитаемое, скажем в “CLK”. Для этого два раза щелкнем мышкой на маркер и в окне свойств введем имя “CLK”. Теперь осталось сделать тоже самое с выходами счетчика. Так как они уже заняты компаратором – придется их “вытягивать” наружу, чтобы можно было подключить к ним маркеры. Протянем четыре “провода” от выходов счетчика в свободное место на схеме, прямо из середины, вот так:
Теперь можно подключить к ним маркеры и присвоить им имена, допустим такие Q0, Q1, Q2 и Q3. Когда все сделано правильно – схема должна выглядеть вот так:
Теперь проект можно сохранять и компилировать. Сохраним проект тривиальным образом, нажав кнопку с дискеткой на панели. Теперь его надо откомпилировать. Для этого на панели с четырьмя вкладками выберем Sources, а на той панели, которая с двумя вкладками выберем Processes. Под “процессами” тут подразумевается набор действий, который мы можем сделать с выбранным исходником. Для этого выбираем наш “головной” файл main.sch. Смотрим, что мы можем с ним сделать. На этом этапе нас интересует процесс Implement Design – это собственно компиляция проекта. Раскроем дерево.
Перед нами четыре этапа компиляции проекта – Synthesize – это собственно синтез проекта, разложение того, что мы только что нарисовали на элементарные части, входящие в макроячейку. Translate – перевод всего этого на язык описания аппаратуры (кстати, на нем тоже можно прекрасно проектировать, но это я оставлю для самостоятельного изучения, ибо VHDL не уместить даже в десятке подобных статей). Fit – это оптимизация нашего проекта под выбранную ПЛИСину и, наконец, Generate Programming File – это и есть генерация кода, который будет записан в ПЛИС. Щелкнем два раза по “корню” дерева – Implement Design. Начался процесс компиляции проекта – спокойно дождемся когда он закончится. Зайдем на вкладку Warnings на панели с логом компиляции внизу. Там нам сообщают, что мы не подключили выходы счетчика CEO и TC, которые нам собственно не нужны, и что также, не подключен вход счетчика CE (разрешение счета) и поэтому он установлен в “0”. Это говорит о том, что счетчик работать не будет – исправим эту ошибку, подтянув этот вход к питанию, с помощью компонента Vcc.
Сохраним и заново перекомпилируем проект. Как мы видим предупреждение о неподключенном входе разрешения счета исчезло – можно продолжать. Чтобы проверить работоспособность нашего проекта – его нужно просимулировать, чем мы сейчас и займемся. В левой панели сверху мы видим список, в котором сейчас выбрано Synthesis/Implementation. Для симуляции проекта нам нужно выбрать пункт Behavioral Simulation в котором щелкнув правой кнопкой мыши по списку исходников создать новый файл в проекте. Для симуляции нам нужно задать входные параметры – это мы и сделаем с помощью добавления в проект файла типа Test Bench Waveform, который назовем counter_test.tbw.
Нам предложат выбрать элемент проекта, который мы хотим просимулировать – так как у нас в проекте всего один файл – выбираем его. Появляется окно, в котором надо указать параметры симуляции проекта.
Оставим там все как есть и нажмем Finish. Файл с данными для симуляции создан, однако на экране мы видим всего четыре тактовых импульса, чего явно недостаточно для полноценной проверки работоспособности нашего счетчика. Увеличим виртуальное время симуляции проекта щелкнув правой кнопкой на нашей свежесозданной временной диаграмме и выбрав пункт Set end of test bench. Пускай это будет 10000 nS – этого времени нам будет достаточно, чтобы увидеть как наш счетчик досчитает до 10 и сбросится. Сохраним наш файл с временной диаграммой и посмотрим, что можно с ним сделать во вкладке Processes (как это сделать, надеюсь, запомнили?) Помимо предложений создать новый исходник и просмотреть то, что мы только что натворили в виде VHDL нам предлагают просимулировать наш проект, что мы сейчас и сделаем. Раскрываем “дерево” Xilinx ISE Simulator и запускаем процесс Simulate Behavioral Model. Итак, в панели с логом побежали сообщения, комп задумался и выдал нам временную диаграмму симуляции нашего проекта. И о чудо! Счетчик действительно считает до 10-и!
Ну что же, проект создан, проверен на работоспособность – неплохо бы его и в ПЛИСину зашить? Ну тогда приступим к подготовительным мероприятиям. Задумайся, читатель – у нашей микросхемы XC95144 аж целых 160 ног, а в нашем проекте использованы только 5, к каким же ногам подключать осциллограф и куда подавать тактовые импульсы? В этом нам поможет утилита PACE, которую можно найти в меню Пуск->Программы->Xilinx ISE 9.2i->Accessories. Запустим эту программу. Перед нами открылось пустое окно – нужно создать новый файл распиновки. Выбираем в меню пункт File->New и перед нами появляется окно для создания нового файла. В поле New Constrains (UCF) file укажем путь, где будет располагаться наш файл с распиновкой. Самым правильным будет создать его в директории проекта и назвать так же, как головной модуль проекта. В поле Input Design File необходимо указать файл с данными о компиляции проекта (с расширением .ngd) и в третьем поле, с помощью кнопки Select Part выбрать семейство (9500 CPLDs), микросхему (XC95144), корпус (PQ160) и скоростную способность (-15) микросхемы. Завершающим этапом создания нового файла будет нажатие кнопки ОК. Итак, перед нами окно в котором мы видим схематическое изображение корпуса ПЛИСины, и список сигналов нашего проекта (на нижней панели слева). Как мы видим, на схематичном изображении корпуса микросхемы выводы помечены разными цветами. Выводы помеченные красным, светло-зеленым и фиолетовым это питание ядра, земля и питание выходных буферов соответственно. Желтые выводы – это выводы JTAG, предназначенные для программирования микросхемы – именно их нужно подключать к программатору. Еще видны выводы, обведенные красным, черным и синим цветами – это GSR (Global Set/Reset), который можно использовать для установки или сброса всех триггеров в проекте (для этого достаточно их назначить), GTS (Global Tri-State) – для перевода всех буферов ПЛИС в “третье” состояние и GCK (Global Clock) – для подачи тактового сигнала. Пусть наш тактовый сигнал будет подключен к GCK1 (33-я нога ПЛИС), остальные сигналы нашего проекта можно расположить произвольно. Однако для определенности пусть они будут подключены к выводам 11,12,13 и 14 по возрастанию. Если все сделано правильно – должно получиться вот так:
Теперь нужно сохранить наш файл и вернуться в ISE, чтобы добавить его в проект. Только чтобы его добавить нужно вернуться в список исходников Synthesis/Implementation. После добавления файла с распиновкой можно закрыть PACE и перекомпилировать проект. Для верности – можно заглянуть в раздел Pin List отчета, который создается после каждой перекомпиляции проекта.
На этом этапе проект готов – можно делать макетную плату с ПЛИСиной и тактовым генератором и проверять проект на “живом железе”, но это я, пожалуй, оставлю для самостоятельной работы. Скажу лишь то, что для программирования ПЛИС предназначена утилита iMPACT, запустить которую можно прямо из ISE. Много материалов по программированию доступно на сайте Xilinx, поэтому повторяться не буду.
Вопросы, как обычно, складываем тут.
Как вам эта статья? | Заработало ли это устройство у вас? |
Эти статьи вам тоже могут пригодиться:
www.radiokot.ru
