
Расчет доверительных интервалов
Доверительный интервал – термин, используемый в математической статистике при интервальной оценке статистических параметров, что предпочтительнее при небольшом объёме выборки.
Доверительный интервал для математического ожидания
Найдем доверительный интервал для математического ожидания при условии, что дисперсия генеральной величины неизвестна, а доверительная вероятность равна 1 – α.
Для расчета доверительного интервала применим формулу:
x – среднее значение величины
–квантиль распределения Стьюдента с степенью свободы
–несмещенное выборочное стандартное отклонение
–объем выборки
Определим квантиль распределения Стьюдента, для этого воспользуемся стандартной таблицей:
возьмем
равным 0,05.
Выберем значение = 2,571
Найдем S:
10.15
2.94
Подставим все известные значения в формулу из пункта 1):
Для M[X]:
Для M[Y]:
Доверительный интервал для дисперсии
Найдем доверительный интервал для дисперсии при условии, что среднее значение величины неизвестно, а доверительная вероятность равна 1 – α.
Для расчета доверительного интервала применим формулу:
–дисперсия
–несмещенное выборочная дисперсия
–квантиль распределения со степенями свободы.
Определим квантиль распределения , для этого воспользуемся специальной таблицей:
12,8325
0,8312
Подставим найденные значения в формулу из пункта 1):
Для Х:
Для У:
Доверительный интервал для корреляции
Найдем
доверительный интервал для корреляции
при условии, что выборка получена из
генеральной совокупности, r
– выборочный коэффициент корреляции.
Для расчета доверительного интервала применим формулу:
Рассчитаем :
возьмем из таблицы квантилей нормального распределения:
Подставим все в формулы:
Найдем с помощью таблицы гиперболических тангенсов:
Проверка гипотез
Таким
образом было установлено, что между
заработной платой сотрудников ДПС и
количеством оштрафованных существует
связь. Искомая
корреляция равна -0.7132. Это
высокая степень взаимосвязи – значения
коэффициента корреляции находится в
пределах от 0,7 до 0,99. Нам удалось выявить
зависимость, и результаты в данном
случае оказались вполне ожидаемы. Чем
выше средняя заработная плата по субъекту
РФ, тем меньше оштрафованных. Почему
получились такие результаты, нам остается
только гадать. Да и не было нашей целью
объяснять почему именно так. Мы должны
были, ради личного интереса, посмотреть
есть ли связь.
Мы должны
были, ради личного интереса, посмотреть
есть ли связь.
Регрессия
Любая нелинейная регрессия, в которой уравнение регрессии для изменений в одной переменной (у) как функции t изменений в другой (х) является квадратичным, кубическим или уравнение более высокого порядка. Хотя математически всегда возможно получить уравнение регрессии, которое будет соответствовать каждой “загогулине” кривой, большинство этих пертурбаций возникает в результате ошибок в составлении выборки или измерении, и такое “совершенное” соответствие ничего не дает. Не всегда легко определить, соответствует ли криволинейная регрессия набору данных, хотя существуют статистические тесты для определения того, значительно ли увеличивает каждая более высокая степень уравнения степ совпадения этого набора данных.
Теперь, будем считать, что выборочная криволинейная регрессия определяется уравнением:

Из ранее изученных пунктов, нам известны следующие параметры:
х = 20,35
у = 9,47
= 85,79
= 7,21
= -0.71
Теперь мы можем подставить все значения в уравнение:
CFA – Доверительные интервалы для среднего значения совокупности | программа CFA
Когда нам нужно получить одно число в качестве оценки параметра совокупности, мы используем точечную оценку. Тем не менее, из-за ошибки выборки, точечная оценка не будет в точности равняться параметру совокупности при любом размере данной выборки.
Часто, вместо точечной оценки, более полезным подходом будет найти диапазон значений, в рамках которого, как мы ожидаем, может находится значение искомого параметра с заданным уровнем вероятности.
Этот подход называется интервальной оценкой параметра (англ. ‘interval estimate of parameter’), а доверительный интервал выполняет роль этого диапазона значений.
Определение доверительного интервала.
Доверительный интервал (англ. ‘confidence interval’) представляет собой диапазон, для которого можно утверждать, с заданной вероятностью \(1 – \alpha \), называемой степенью доверия (или степенью уверенности, англ. ‘degree of confidence’), что он будет содержать оцениваемый параметр.
Этот интервал часто упоминается как \(100 (1 – \alpha)\% \) доверительный интервал для параметра.
Конечные значения доверительного интервала называются нижним и верхним доверительными пределами (или доверительными границами или предельной погрешностью, англ. ‘lower/upper confidence limits’).
В этом чтении, мы имеем дело только с двусторонними доверительными интервалами
Кроме того, можно определить два типа односторонних доверительных интервалов для параметра совокупности.
Нижний односторонний доверительный интервал устанавливает только нижний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности равен или превышает нижний предел.
Верхний односторонний доверительный интервал устанавливает только верхний предел. Это означает допущение, что с определенной степенью доверия параметр совокупности меньше или равен верхнему пределу.
Инвестиционные аналитики редко используют односторонние доверительные интервалы.
Доверительные интервалы часто дают либо вероятностную интерпретацию, либо практическую интерпретацию.
При вероятностной интерпретации
, мы интерпретируем 95%-ный доверительный интервал для среднего значения совокупности следующим образом.При повторяющейся выборке, 95% таких доверительных интервалов будут, в конечном счете, включать в себя среднее значение совокупности.
Например, предположим, что мы делаем выборку из совокупности 1000 раз, и на основании каждой выборки мы построим 95%-ный доверительный интервал, используя вычисленное выборочное среднее.
Из-за случайного характера выборок, эти доверительные интервалы отличаются друг от друга, но мы ожидаем, что 95% (или 950) этих интервалов включают неизвестное значение среднего по совокупности.
На практике мы обычно не делаем такие повторяющиеся выборки. Поэтому в практической интерпретации, мы утверждаем, что мы 95% уверены в том, что один 95%-ный доверительный интервал содержит среднее по совокупности.
Мы вправе сделать это заявление, потому что мы знаем, что 95% всех возможных доверительных интервалов, построенных аналогичным образом, будут содержать среднее по совокупности.
Доверительные интервалы, которые мы обсудим в этом чтении, имеют структуры, подобные описанной ниже базовой структуре.
Построение доверительных интервалов.
Доверительный интервал \(100 (1 – \alpha)\% \) для параметра имеет следующую структуру.
Точечная оценка \(\pm\) Фактор надежности \(\times\) Стандартная ошибка
где
- Точечная оценка = точечная оценка параметра (значение выборочной статистики).

- Фактор надежности (англ. ‘reliability factor’) = коэффициент, основанный на предполагаемом распределении точечной оценки и степени доверия \((1 – \alpha)\) для доверительного интервала.
- Стандартная ошибка = стандартная ошибка выборочной статистики, значение которой получено с помощью точечной оценки.
Величину (Фактор надежности) \(\times\) (Cтандартная ошибка) иногда называют точностью оценки (англ. ‘precision of estimator’). Большие значения этой величины подразумевают более низкую точность оценки параметра совокупности.
Самый базовый доверительный интервал для среднего значения по совокупности появляется тогда, когда мы делаем выборку из нормального распределения с известной дисперсией. Фактор надежности в данном случае на основан стандартном нормальном распределении, которое имеет среднее значение, равное 0 и дисперсию 1.
Стандартная нормальная случайная величина обычно обозначается как \(Z\). 2\) = 400 (значит, \(\sigma\) = 20).
2\) = 400 (значит, \(\sigma\) = 20).
Мы рассчитываем выборочное среднее как \( \overline X = 25 \). Наша точечная оценка среднего по совокупности, таким образом, 25.
Если мы перемещаем 1.96 стандартных отклонений выше среднего значения нормального распределения, то 0.025 или 2.5% вероятности остается в правом хвосте. В силу симметрии нормального распределения, если мы перемещаем 1.96 стандартных отклонений ниже среднего, то 0.025 или 2.5% вероятности остается в левом хвосте.
В общей сложности, 0.05 или 5% вероятности лежит в двух хвостах и 0.95 или 95% вероятности лежит между ними.
Таким образом, \( z_{0.025} = 1.96\) является фактором надежности для этого 95%-ного доверительного интервала. Обратите внимание на связь \(100 (1 – \alpha)\% \) для доверительного интервала и \(z_{\alpha/2}\) для фактора надежности.
Стандартная ошибка среднего значения выборки, заданная Формулой 1, равна \( \sigma_{\overline X} = 20 \Big / \sqrt{100} = 2 \).
Доверительный интервал, таким образом, имеет нижний предел \( \overline X – 1. 2 \) задается формулой:
2 \) задается формулой:
\( \Large { \overline X \pm z_{\alpha /2}{\sigma \over \sqrt n} } \) (Формула 4)
Факторы надежности для наиболее часто используемых доверительных интервалов приведены ниже.
Факторы надежности для доверительных интервалов на основе стандартного нормального распределения.
Мы используем следующие факторы надежности при построении доверительных интервалов на основе стандартного нормального распределения:
- 90%-ные доверительные интервалы: используется \(z_{0.05}\) = 1.65
- 95%-ные доверительные интервалы: используется \(z_{0.025}\) = 1.96
- 99%-ные доверительные интервалы: используется \(z_{0.005}\) = 2.58
На практике, большинство финансовых аналитиков используют значения для \(z_{0.05}\) и \(z_{0.005}\), округленные до двух знаков после запятой.
Для справки, более точными значениями для \(z_{0.05}\) и \(z_{0.005}\) являются 1.645 и 2.575, соответственно.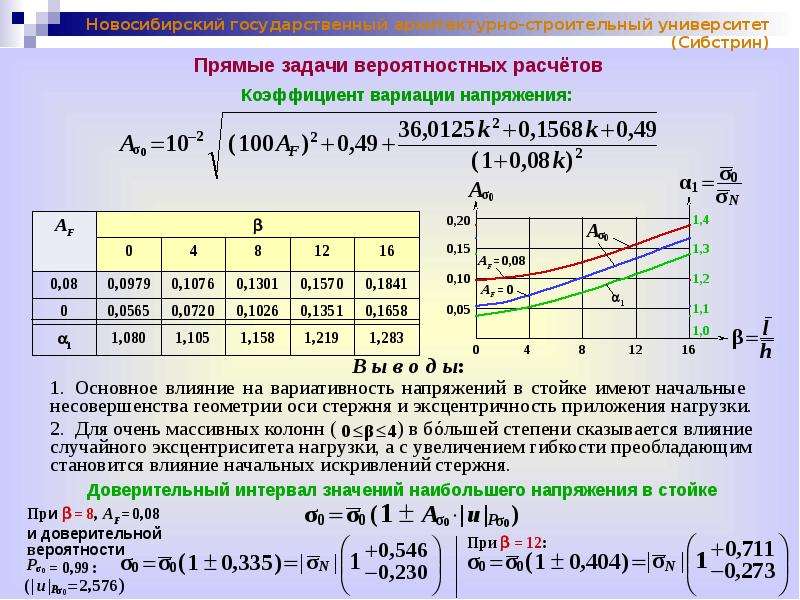
Для быстрого расчета 95%-ного доверительного интервала \(z_{0.025}\) иногда округляют 1.96 до 2.
Эти факторы надежности подчеркивают важный факт о всех доверительных интервалах. По мере того, как мы повышаем степень доверия, доверительный интервал становится все шире и дает нам менее точную информацию о величине, которую мы хотим оценить.
«Чем уверенней мы хотим быть, тем меньше мы должны быть уверены»
см. Freund и Williams (1977), стр. 266.
На практике, допущение о том, что выборочное распределение выборочного среднего, по меньшей мере, приблизительно нормальное, часто является обоснованным, либо потому, что исходное распределение приблизительно нормальное, либо потому что мы имеем большую выборку и поэтому к ней применима центральная предельная теорема.
Однако, на практике, мы редко знаем дисперсию совокупности. Когда дисперсия генеральной совокупности неизвестна, но выборочное среднее, по меньшей мере, приблизительно нормально распределено, у нас есть два приемлемых пути чтобы вычислить доверительные интервалы для среднего значения совокупности.
Вскоре мы обсудим более консервативный подход, который основан на t-распределении Стьюдента (t-распределение, для краткости).
Распределение статистики \(t\) называется t-распределением Стьюдента (англ. “Student’s t-distribution”) из-за псевдонима «Студент» (Student), использованного британским математиком Уильямом Сили Госсеттом, который опубликовал свою работу в 1908 году.В финансовой литературе, это наиболее часто используемый подход для статистической оценки и проверки статистических гипотез, касающихся среднего значения, когда дисперсия генеральной совокупности не известна, как для малого, так и для большого размер выборки.
Второй подход к доверительным интервалам для среднего по совокупности, основанного на стандартном нормальном распределении, – это z-альтернатива (англ. ‘z-alternative’). Он может быть использован только тогда, когда размер выборки является большим (в общем случае, размер выборки 30 или больше, можно считать большим).
В отличии от доверительного интервала, приведенного в Формуле 4, этот доверительный интервал использует стандартное отклонение выборки \(s\) при вычислении стандартной ошибки выборочного среднего (по Формуле 2).
Доверительные интервалы для среднего по совокупности – z-альтернатива (большая выборка, дисперсия совокупности неизвестна).
Доверительный интервал \(100 (1 – \alpha)\% \) для среднего по совокупности \( \mu \) при выборке из любого распределения с неизвестной дисперсией, когда размер выборки большой, задается формулой:
\( \Large { \overline X \pm z_{\alpha /2}{s \over \sqrt n} } \) (Формула 5)
Поскольку этот тип доверительного интервала применяется довольно часто, мы проиллюстрируем его вычисление в Примере 4.
Пример (4) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием z-статистики.
Предположим, что инвестиционный аналитик делает случайную выборку акций взаимных фондов США и рассчитывает средний коэффициент Шарпа.
[см. также: CFA – Коэффициент Шарпа]
Размер выборки равен 100, а средний коэффициент Шарпа составляет 0.45. Выборка имеет стандартное отклонение 0.30.
Рассчитайте и интерпретируйте 90-процентный доверительный интервал для среднего по совокупности всех акций взаимных фондов США с использованием фактора надежности на основе стандартного нормального распределения.
Фактор надежности для 90-процентного доверительного интервала, как указано ранее, составляет \( z_{0.05} = 1.65 \).
Доверительный интервал будет равен:
\( \begin{aligned} & \overline X \pm z_{0.05}{s \over \sqrt n } \\ &= 0.45 \pm 1.65{0.30 \over \sqrt {100}} \\ &= 0.45 \pm 1.65(0.03) = 0.45 \pm 0.0495 \end{aligned} \)
Доверительный интервал охватывает значения 0.4005 до 0.4995, или от 0.40 до 0.50, с округлением до двух знаков после запятой. Аналитик может сказать с 90-процентной уверенностью, что интервал включает среднее по совокупности.
В этом примере аналитик не делает никаких конкретных предположений о распределении вероятностей, характеризующем совокупность. Скорее всего, аналитик опирается на центральную предельную теорему для получения приближенного нормального распределения для выборочного среднего.
Скорее всего, аналитик опирается на центральную предельную теорему для получения приближенного нормального распределения для выборочного среднего.
Как показывает Пример 4, даже если мы не уверены в характере распределения совокупности, мы все еще можем построить доверительные интервалы для среднего по совокупности, если размер выборки достаточно большой, поскольку можем применить центральную предельную теорему.
Концепция степеней свободы.
Обратимся теперь к консервативной альтернативе и используем t-распределение Стьюдента, чтобы построить доверительные интервалы для среднего по совокупности, когда дисперсия генеральной совокупности не известна.
Для доверительных интервалов на основе выборок из нормально распределенных совокупностей с неизвестной дисперсией, теоретически правильный фактор надежности основан на t-распределении. Использование фактора надежности, основанного на t-распределении, имеет важное значение для выборок небольшого размера.
Применение фактора надежности \(t\) уместно, когда дисперсия генеральной совокупности неизвестна, даже если у нас есть большая выборка и мы можем использовать центральную предельную теорему для обоснования использования фактора надежности \(z\). В этом случае большой выборки, t-распределение обеспечивает более консервативные (широкие) доверительные интервалы.
t-распределение является симметричным распределением вероятностей и определяется одним параметром, известным как степени свободы (DF, от англ. ‘degrees of freedom’). Каждое значение для числа степеней свободы определяет одно распределение в этом семействе распределений.
Далее мы сравним t-распределения со стандартным нормальным распределением, но сначала мы должны понять концепцию степеней свободы. Мы можем сделать это путем изучения расчета выборочной дисперсии.
Формула 3 дает несмещенную оценку выборочной дисперсии, которую мы используем. Выражение в знаменателе, \( n – 1 \), означающее размер выборки минус 1, это число степеней свободы при расчете дисперсии совокупности с использованием Формулы 3.
Мы также используем \( n – 1 \) как число степеней свободы для определения факторов надежности на основе распределения Стьюдента. Термин «степени свободы» используются, так как мы предполагаем, что в случайной выборке наблюдения отобраны независимо друг от друга. Числитель выборочной дисперсии, однако, использует выборочное среднее.
Каким образом использование выборочного среднего влияет на количество наблюдений, отобранных независимо, для формулы выборочной дисперсии?
При выборке размера 10 и среднем значении в 10%, к примеру, мы можем свободно отобрать только 9 наблюдений. Независимо от отобранных 9 наблюдений, мы всегда можем найти значение для 10-го наблюдения, которое дает среднее значение, равное 10%. С точки зрения формулы выборочной дисперсии, здесь есть 9 степеней свободы.
Учитывая, что мы должны сначала вычислить выборочное среднее от общего числа \(n\) независимых наблюдений, только \(n – 1\) наблюдений могут быть отобраны независимо друг от друга для расчета выборочной дисперсии.
Концепция степеней свободы часто применяется в финансовой статистике, и вы встретите ее в последующих чтениях.
t-распределение Стьюдента.
Предположим, что мы делаем выборку из нормального распределения.
Коэффициент \(z = (\overline X – \mu) \Big / (\sigma \big / \sqrt n) \) нормально распределен со средним значением 0 и стандартным отклонением 1, однако, коэффициент \(t = (\overline X – \mu) \Big / (s \big / \sqrt n) \) следует t-распределению со средним 0 и \(n – 1\) степеней свободы.
Коэффициент \(t\) не является нормальным, поскольку представляет собой отношение двух случайных величин, выборочного среднего и стандартного отклонения выборки.
Определение стандартной нормальной случайной величины включает в себя только одну случайную величину, выборочное среднее. По мере увеличения степеней свободы, однако, t-распределение приближается к стандартному нормальному распределению.
На Рисунке 1 показано стандартное нормальное распределение и два t-распределения, одно с DF = 2 и одно с DF = 8.
Рисунок (1) t-распределение Стьюдента по сравнению со стандартным нормальным распределением.
Из трех распределений, показанных на Рисунке 1, стандартное нормальное распределение имеет хвосты, которые стремятся к нулю быстрее, чем хвосты двух t-распределений. t-распределение симметрично распределено вокруг среднего нулевого значения, так же как и нормальное распределение.
По мере увеличения степеней свободы, t-распределение приближается к стандартному нормальному распределению. t-распределение с DF = 8 ближе к стандартному нормальному, чем t-распределение с DF = 2.
Помимо области плюс и минус четырех стандартных отклонений от среднего значения, остальная область под стандартным нормальным распределением, как представляется, близка к 0. Однако, оба t-распределения содержать некоторую площадь под каждой кривой за пределом четырех стандартных отклонений.
t-распределения имеют более толстые хвосты, но хвосты t-распределения Стьюдента с DF = 8 сильнее напоминают хвосты нормального распределения. По мере увеличения степеней свободы, хвосты распределения Стьюдента становятся менее толстыми.
По мере увеличения степеней свободы, хвосты распределения Стьюдента становятся менее толстыми.
Для часто используемых значений распределения Стьюдента составлены таблицы. Например, для каждой степени свободы \(t_{0.10}\), \(t_{0.05}\), \(t_{0.025}\), \(t_{0.01}\) и \(t_{0.005}\) значения будут такими, что соответственно, 0.10, 0.05, 0.025, 0.01 и 0.005 вероятности останется в правом хвосте для заданного числа степеней свободы.
Значения \(t_{0.10}\), \(t_{0.05}\), \(t_{0.025}\), \(t_{0.01}\) и \(t_{0.005}\) также называют односторонними критическими значениями t на значимых уровнях 0.10, 0.05, 0.025, 0.01 и 0.005, для указанного числа степеней свободы.
Например, для DF = 30,
\(t_{0.10}\) = 1.310,
\(t_{0.05}\) = 1.697,
\(t_{0.025}\) = 2.042,
\(t_{0.01}\) = 2.457,
\(t_{0.005}\) = 2.750.
Приведем форму доверительных интервалов для среднего по совокупности, используя распределение Стьюдента.
Доверительные интервалы для среднего по совокупности (дисперсия совокупности неизвестна) – t-распределение.

Если мы делаем выборку из генеральной совокупности с неизвестной дисперсией и соблюдается одно из перечисленных ниже условий:
- выборка является большой, или
- выборка небольшая, но совокупность имеет нормальное распределение, или приблизительно нормально распределена,
то доверительный интервал \(100 (1 – \alpha)\% \) для среднего совокупности \( \mu \) задается формулой:
\( \Large { \overline X \pm t_{\alpha /2}{s \over \sqrt n} } \) (Формула 6),
где число степеней свободы для \( t_{\alpha /2}\) равно \( n-1 \), а \( n \) – это размер выборки.
Пример 5 использует данные Примера 4, но применяет t-статистику, а не z-статистику, чтобы рассчитать доверительный интервал для среднего значения совокупности коэффициентов Шарпа.
Пример (5) расчета доверительного интервала для среднего по совокупности коэффициентов Шарпа с использованием t-статистики.
Как и в Примере 4, инвестиционный аналитик стремится вычислить 90-процентный доверительный интервал для среднего по совокупности коэффициентов Шарпа, основанных на случайной выборке из 100 взаимных фондов США.
Выборочное среднее коэффициентов Шарпа составляет 0.45, а выборочное стандартное отклонение – 0.30.
Теперь, признав, что дисперсия генеральной совокупности распределения коэффициентов Шарпа неизвестна, аналитик решает вычислить доверительный интервал, используя теоретически правильную t-статистику.
Поскольку размер выборки равен 100, DF = 99. Используя таблицу степеней свободы, мы находим, что \(t_{0.05}\) = 1.66.
Этот фактор надежности немного больше, чем фактор надежности \(z_{0.05}\) = 1.65, который был использован в Примере 4.
Доверительный интервал будет:
\( \begin{aligned} & \overline X \pm t_{0.05}{s \over \sqrt n } \\ &= 0.45 \pm 1.66{0.30 \over \sqrt {100}} \\ &= 0.45 \pm 1.66(0.03) = 0.45 \pm 0.0498 \end{aligned} \)
Доверительный интервал охватывает значения 0.4002 до 0.4998, или 0.40 до 0.50, с двумя знаками после запятой. При округлении до двух знаков после запятой, доверительный интервал не изменился по сравнению с Примером 4.
В Таблице 3 приведены различные факторы надежности, которые мы использовали.
|
Выборка из: |
Статистика для выборки малого размера |
Статистика для выборки большого размера |
|---|---|---|
|
Нормальное распределение с известной дисперсией |
\(z\) |
\(z\) |
|
Нормальное распределение с неизвестной дисперсией |
\(t\) |
\(t\)* |
|
Ненормальное распределение с известной дисперсией |
не доступно |
\(z\) |
|
Ненормальное распределение с неизвестной дисперсией |
не доступно |
\(t\)* |
* Использование \(z\) также приемлемо.
Confidence Interval / Доверительный интервал
Confidence Interval / Доверительный интервал
Метод для переноса значений оценок параметра (доли, среднего, медианы, дисперсии и т.д.) с выборки на генеральную совокупность. Выбор нужного доверительного интервала зависит от типа шкалы исследуемых признаков.
Требуемый уровень подготовки пользователя: начальный.
Желательно владение методами: описательной статистики.
Навигация по странице
Доверительный интервал для доли
Онлайн-калькулятор
Доверительный интервал для доли применим к шкалам любого типа (предпочтительно – к категориальным), т.к. расчёт строится на основе частотных распределений. Сам доверительный интервал показывает, в каких границах находится интересующая доля в генеральной совокупности. Если построить интервалы отдельно для нескольких долей, то на основании них можно судить о наличии или отсутствии статистически значимых различий: если интервалы пересекаются, различий нет, если не пересекаются – различия есть. Такая процедура – аналог z-теста, в котором проверяется гипотеза о равенстве долей
(в SPSS этот тест имеет сложную реализацию через Custom Tables).
Доверительный интервал для медианы
Онлайн-калькулятор
Доверительный интервал для медианы применим к шкалам порядкового (рангового) типа и выше. Сам доверительный интервал показывает, в каких границах находится медиана признака в генеральной совокупности. Если построить интервалы отдельно для нескольких медиан, то на основании них можно судить о наличии или отсутствии статистически значимых различий: если интервалы пересекаются, различий нет, если не пересекаются – различия есть. Такая процедура – аналог некоторых непараметрических методов, в которых проверяется гипотеза о равенстве медиан.
Доверительный интервал для среднего
Онлайн-калькулятор
Доверительный интервал для среднего применим к шкалам интервального типа и выше. Сам доверительный интервал показывает, в каких границах находится математическое ожидание (среднее арифметическое) признака в генеральной совокупности. Если построить интервалы отдельно для нескольких средних, то на основании них можно судить о наличии или отсутствии статистически значимых различий: если интервалы пересекаются, различий нет, если не пересекаются – различия есть. Такая процедура – аналог t-тестов,
в которых проверяется гипотеза о равенстве математических ожиданий.
Доверительный интервал для математического ожидания
Доверительный интервал для математического ожидания – это такой вычисленный по данным интервал, который с известной вероятностью содержит математическое ожидание генеральной совокупности. Естественной оценкой для математического ожидания является среднее арифметическое её наблюденных значений. Поэтому далее в течение урока мы будем пользоваться терминами “среднее”, “среднее значение”. В задачах рассчёта доверительного интервала чаще всего требуется ответ типа “Доверительный интервал [95%; 90%; 99%] среднего числа [величина в конкретной задаче] находится от [меньшее значение] до [большее значение]”. С помощью доверительного интервала можно оценивать не только средние значения, но и удельный вес того или иного признака генеральной совокупности. Средние значения, дисперсия, стандартное отклонение и погрешность, через которые мы будем приходить к новым определениям и формулам, разобраны на уроке Характеристики выборки и генеральной совокупности.
Если среднее значение генеральной совокупности оценивается числом (точкой), то за оценку неизвестной средней величины генеральной совокупности принимается конкретное среднее, которое рассчитано по выборке наблюдений. В таком случае значение среднего выборки – случайной величины – не совпадает со средним значением генеральной совокупности. Поэтому, указывая среднее значение выборки, одновременно нужно указывать и ошибку выборки. В качестве меры ошибки выборки используется стандартная ошибка , которая выражена в тех же единицах измерения, что и среднее. Поэтому часто используется следующая запись: .
Если оценку среднего требуется связать с определённой вероятностью, то интересующий параметр генеральной совокупности нужно оценивать не одним числом, а интервалом. Доверительным интервалом называют интервал, в котором с определённой вероятностью P находится значение оцениваемого показателя генеральной совокупности. Доверительный интервал, в котором с вероятностью P = 1 – α находится случайная величина , рассчитывается следующим образом:
,
где – критическое значение стандартного нормального распределения для уровня значимости α = 1 – P, которое можно найти в приложении к практически любой книге по статистике.
Формулу доверительного интервала можно использовать для оценки среднего генеральной совокупности, если
- известно стандартное отклонение генеральной совокупности;
- или стандартное отклонение генеральной совокупности не известно, но объём выборки – больше 30.
Среднее значение выборки является несмещённой оценкой среднего генеральной совокупности . В свою очередь, дисперсия выборки не является несмещённой оценкой дисперсии генеральной совокупности . Для получения несмещённой оценки дисперсии генеральной совокупности в формуле дисперсии выборки объём выборки n следует заменить на n-1.
Пример 1. Собрана информация из 100 случайно выбранных кафе в некотором городе о том, что среднее число работников в них составляет 10,5 со стандартным отклонением 4,6. Определить доверительный интервал 95% числа работников кафе.
Решение:
,
где – критическое значение стандартного нормального распределения для уровня значимости α = 0,05.
Таким образом, доверительный интервал 95% среднего числа работников кафе составил от 9,6 до 11,4.
Пример 2. Для случайной выборки из генеральной совокупности из 64 наблюдений вычислены следующие суммарные величины:
сумма значений в наблюдениях ,
сумма квадратов отклонения значений от среднего .
Вычислить доверительный интервал 95 % для математического ожидания.
Решение:
вычислим стандартное отклонение:
,
вычислим среднее значение:
.
Подставляем значения в выражение для доверительного интервала:
.
где – критическое значение стандартного нормального распределения для уровня значимости α = 0,05.
Получаем:
.
Таким образом, доверительный интервал 95% для математического ожидания данной выборки составил от 7,484 до 11,266.
Пример 3. Для случайной выборки из генеральной совокупности из 100 наблюдений вычислено среднее значение 15,2 и стандартное отклонение 3,2. Вычислить доверительный интервал 95 % для математического ожидания, затем доверительный интервал 99 %. Если мощность выборки и её вариация остаются неизменными, а увеличивается доверительный коэффициент, то доверительный интервал сузится или расширится?
Решение:
Подставляем данные значения в выражение для доверительного интервала:
.
где – критическое значение стандартного нормального распределения для уровня значимости α = 0,05.
Получаем:
.
Таким образом, доверительный интервал 95% для среднего данной выборки составил от 14,57 до 15,82.
Вновь подставляем данные значения в выражение для доверительного интервала:
.
где – критическое значение стандартного нормального распределения для уровня значимости α = 0,01.
Получаем:
.
Таким образом, доверительный интервал 99% для среднего данной выборки составил от 14,37 до 16,02.
Как видим, при увеличении доверительного коэффициента увеличивается также критическое значение стандартного нормального распределения, а, следовательно, начальная и конечная точки интервала расположены дальше от среднего, и, таким образом, доверительный интервал для математического ожидания увеличивается.
Удельный вес некоторого признака выборки можно интерпретировать как точечную оценку удельного веса p этого же признака в генеральной совокупности. Если же эту величину нужно связать с вероятностью, то следует рассчитать доверительный интервал удельного веса p признака в генеральной совокупности с вероятностью P = 1 – α:
.
Пример 4. В некотором городе два кандидата A и B претендуют на пост мэра. Случайным образом были опрошены 200 жителей города, из которых 46% ответили, что будут голосовать за кандидата A, 26% – за кандидата B и 28% не знают, за кого будут голосовать. Определить доверительный интервал 95% для удельного веса жителей города, поддерживающих кандидата A.
Решение:
Таким образом, доверительный интервал 95% удельного веса горожан, поддерживающих кандидата A, составил от 0,391 до 0,529.
Пример 5. Чтобы проверить отношение покупателей к новому квасу, проведён опрос случайной выборки в 50 человек. Результаты обобщены в следующей таблице (0 – не понравился, 1 – понравился, 2 – нет ответа):
| 1 | 0 | 0 | 1 | 2 |
| 0 | 1 | 0 | 2 | 0 |
| 1 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 1 |
| 0 | 2 | 0 | 0 | 1 |
| 0 | 1 | 1 | 0 | 0 |
| 2 | 2 | 0 | 0 | 1 |
| 1 | 0 | 2 | 0 | 0 |
| 0 | 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 0 | 1 |
Найти доверительный интервал 95 % удельного веса покупателей, которым новый квас не понравился.
Решение.
Найдём удельный вес указанных покупателей в выборке: 29/50 = 0,58. Таким образом, , . Мощность выборки известна (n = 50). Критическое значение стандартного нормального распределения для уровня значимости α = 0,05 равно 1,96. Подставляем имеющиеся показатели в выражение интервала для удельного веса:
Таким образом, доверительный интервал 95% удельного веса покупателей, которым новый квас не понравился, составил от 0,45 до 0,71.
Всё по теме “Математическая статистика”
Как найти доверительный интервал в Excel
Программа Эксель используется для выполнения различных статистических задач, одной из которых является вычисление доверительного интервала, который применяется как наиболее подходящая замена точечной оценки при малом объеме выборки.
Хотим сразу заметить, что сама процедура вычисления доверительного интервала довольно непростая, однако, в Excel существует ряд инструментов, призванных облегчить выполнение данной задачи. Давайте рассмотрим их.
Вычисление доверительного интервала
Доверительный интервал нужен для того, чтобы дать интервальную оценку каким-либо статическим данным. Основная цель этой операции – убрать неопределенности точечной оценки.
В Microsoft Excel существует два метода выполнения данной задачи:
- Оператор ДОВЕРИТ.НОРМ – применяется в случаях, когда дисперсия известна;
- Оператор ДОВЕРИТ.СТЬЮДЕНТ– когда дисперсия неизвестна.
Ниже мы пошагово разберем оба метода на практике.
Метод 1: оператора ДОВЕРИТ.НОРМ
Данная функция впервые была внедрена в арсенал программы в редакции Эксель 2010 года (до этой версии ее заменял оператор “ДОВЕРИТ”). Оператор входит в категорию “статистические”.
Формула функции ДОВЕРИТ.НОРМ выглядит так:
=ДОВЕРИТ.НОРМ(Альфа;Станд_откл;Размер)
Как мы видим, у функции есть три аргумента:
- “Альфа” – это показатель уровня значимости, который берется за основу при расчете. Доверительный уровень считается так:
1-"Альфа". Это выражение применимо в случае, если значение “Альфа” представлено в виде коэффициента. Например, 1-0,7=0,3, где 0,7=70%/100%.(100-"Альфа")/100. Применятся это выражение, если мы считаем доверительным уровень со значением “Альфа” в процентах. Например, (100-70)/100=0,3.
- “Стандартное отклонение” — соответственно, стандартное отклонение анализируемой выборки данных.
- “Размер” – объем выборки данных.
Примечание: У данной функции наличие всех трех аргументов является обязательным условием.
Оператор “ДОВЕРИТ”, который применялся в более ранних редакциях программы, содержит такие же аргументы и выполняет те же самые функции.
Формула функции ДОВЕРИТ выглядит следующим образом:
=ДОВЕРИТ(Альфа;Станд_откл;Размер)
Отличий в самой формуле нет никаких, лишь название оператора иное. В редакциях приложения Эксель 2010 года и последующих этот оператор находится в категории “Совместимость”. В более же старых версиях программы он находится в разделе статических функций.
Граница доверительного интервала определяется следующей формулой:
X+(-)ДОВЕРИТ.НОРМ
где Х – это среднее значение по заданному диапазону.
Теперь давайте разберемся, как применять эти формулы на практике. Итак, у нас есть таблица с различными данными 10-ти проведенных замеров. При этом, стандартное отклонение совокупности данных равняется 8.
Перед нами стоит задача – получить значение доверительного интервала с 95%-ым уровнем доверия.
- Первым делом выбираем ячейку для вывода результата. Затем кликаем по кнопке “Вставить функцию” (слева от строки формул).
- Откроется окно Мастера функций. Кликнув по текущей категории функций, раскрываем список и щелкаем в нем по строке “Статистические”.
- В предложенном перечне кликаем по оператору “ДОВЕРИТ.НОРМ”, затем жмем OK.
- Перед нами появится окно с настройками аргументов функции, заполнив которые нажимаем кнопку OK.
- в поле “Альфа” указываем уровень значимости. В нашей задаче предполагается 95%-ый уровень доверия. Подставив данное значение в формулу расчета, которую мы рассматривали выше, получаем выражение:
(100-95)/100. Пишем его в поле аргумента (или можно сразу написать результат вычисления, равный 0,05). - в поле “Станд_откл” согласно нашим условия, пишем цифру 8.
- в поле “Размер” указываем количество исследуемых элементов. В нашем случае было проведено 10 замеров, значит пишем цифру 10.
- в поле “Альфа” указываем уровень значимости. В нашей задаче предполагается 95%-ый уровень доверия. Подставив данное значение в формулу расчета, которую мы рассматривали выше, получаем выражение:
- Чтобы при изменении данных не пришлось заново настраивать функцию, можно автоматизировать ее. Для это применим функцию “СЧЁТ”. Ставим указатель в область ввода информации аргумента “Размер”, затем щелкаем по значку треугольника с левой стороны от строки формул и кликаем по пункту “Другие функции…”.
- В результате откроется еще одно окно Мастера функций. Выбрав категорию “Статистические”, кликаем по функции “СЧЕТ”, затем – OK.
- На экране отобразится еще одно окно с настройками аргументов функции, которая применяется для определения числа ячеек в заданном диапазоне, в которых находятся числовые данные.
Формула функции СЧЕТ пишется так:=СЧЁТ(Значение1;Значение2;...).
Количество доступных аргументов этой функции может достигать 255 штук. Здесь можно прописать, либо конкретные числа, либо адреса ячеек, либо диапазоны ячеек. Мы воспользуемся последним вариантом. Для этого кликаем по области ввода информации для первого аргумента, затем зажав левую кнопку мыши выделяем все ячейки одного из столбцов нашей таблицы (не считая шапки), после чего жмем кнопку OK. - В результате проделанных действий в выбранной ячейке будет выведено результат расчетов по оператору ДОВЕРИТ.НОРМ. В нашей задаче его значение оказалось равным 4,9583603.
- Но это еще не конечный результат в нашей задаче. Далее требуется рассчитать среднее значение по заданному интервалу. Для этого потребуется применить функцию “СРЗНАЧ”, которая выполняет задачу по вычислению среднего значения в пределах указанного диапазона данных.
Формула оператора пишется так:=СРЗНАЧ(число1;число2;...).
Выделяем ячейку, куда планируем вставить функцию и жмем кнопку “Вставить функцию”. - В категории “Статистические” выбираем нудный оператор “СРЗНАЧ” и кликаем OK.
- В аргументах функции в значении аргумента “Число” указываем диапазон, в который входят все ячейки со значениями всех замеров. Затем кликаем OK.
- В результате проделанных действий среднее значение будет автоматически подсчитано и выведено в ячейку с только что вставленной функцией.
- Теперь нам нужно рассчитать границы ДИ (доверительного интервала). Начнем с расчета значения правой границы. Выбираем ячейку, куда хотим вывести результат, и выполняем в ней сложение результатов, полученных с помощью операторов “СРЗНАЧ” и “ДОВЕРИТ.НОРМ”. В нашем случае формула выглядит так:
A14+A16. После ее набора жмем Enter. - В результате будет произведен расчет и результат немедленно отобразится в ячейке с формулой.
- Затем аналогичным способом выполняем расчет для получения значения левой границы ДИ. Только в этом случае значение результата “ДОВЕРИТ.НОРМ” нужно не прибавлять, а вычитать из результата, полученного при помощи оператора “СРЗНАЧ”. В нашем случае формула выглядит так:
=A16-A14. - После нажатия Enter мы получим результат в заданной ячейке с формулой.
Примечание: В пунктах выше мы постарались максимально подробно расписать все шаги и каждую применяемую функцию. Однако все прописанные формулы можно записать вместе, в составе одной большой:
- Для определения правой границы ДИ общая формула будет выглядеть так:
=СРЗНАЧ(B2:B11)+ДОВЕРИТ.НОРМ(0,05;8;СЧЁТ(B2:B11)). - Точно также и для левой границы, только вместо плюса нужно поставить минус:
=СРЗНАЧ(B2:B11)-ДОВЕРИТ.НОРМ(0,05;8;СЧЁТ(B2:B11)).
Метод 2: оператор ДОВЕРИТ.СТЬЮДЕНТ
Теперь давайте познакомимся со вторым оператором для определения доверительного интервала – ДОВЕРИТ.СТЬЮДЕНТ. Данная функция была внедрена в программу относительно недавно, начиная с версии Эксель 2010, и направлена на определение ДИ выбранной совокупности данных с применением распределения Стьюдента, при неизвестной дисперсии.
Формула функции ДОВЕРИТ.СТЬЮДЕНТ выглядит следующим образом:
=ДОВЕРИТ.СТЬЮДЕНТ(Альфа;Cтанд_откл;Размер)
Давайте разберем применение данного оператора на примере все той же таблицы. Только теперь стандартное отклонение по условиям задачи нам неизвестно.
- Сначала выбираем ячейку, куда планируем вывести результат. Затем кликаем по значку “Вставить функцию” (слева от строки формул).
- Откроется уже хорошо знакомое окно Мастера функций. Выбираем категорию “Статистические”, затем из предложенного списка функций щелкаем по оператору “ДОВЕРИТ.СТЬЮДЕНТ”, после чего – OK.
- В следующем окне нам нужно настроить аргументы функции:.
- В выбранной ячейке отобразится значение доверительного интервала согласно заданным нами параметрам.
- Далее нам нужно рассчитать значения границ ДИ. А для этого потребуется получить среднее значение по выбранному диапазону. Для этого снова применим функцию “СРЗНАЧ”. Алгоритм действий аналогичен тому, что был описан в первом методе.
- Получив значение “СРЗНАЧ”, можно приступать к расчетам границ ДИ. Сами формулы ничем не отличаются от тех, что использовались с оператором “ДОВЕРИТ.НОРМ”:
- Правая граница ДИ=СРЗНАЧ+ДОВЕРИТ.СТЬЮДЕНТ
- Левая граница ДИ=СРЗНАЧ-ДОВЕРИТ.СТЬЮДЕНТ
Заключение
Арсенал инструментов Excel невероятно большой, и наряду с распространенными функциями, программа предлагает большое разнообразие специальных функций, которые помогут существенно облегчить работу с данными. Возможно, описанные выше шаги некоторым пользователям, на первый взгляд, могут показаться сложными. Но после детального изучения вопроса и последовательности действий, все станет намного проще.
Показатели сравнения частоты заболеваний | Эпидемиология
По сравнению с исследованиями, в которых просто измеряется частота заболевания в одной группе, в исследованиях связи между экспозицией и заболеванием сравнивают частоту заболевания у лиц с разным уровнем экспозиции. Чаще всего используется отношение коэффициентов, или относительный риск, определяемый как отношение коэффициентов заболеваемости у экспонированных и неэкспонированных. Может также использоваться отношение кумулятивных коэффициентов заболеваемости для экспонированной и неэкспонированной групп. Результат сравнения частоты заболевания не обязательно должен быть выражен отношением: целесообразно также оценить его разностью показателей частоты для экспонированной и неэкспонированной групп населения. При контроле систематических ошибок, любой сравнительный показатель частоты заболевания в группах с различными уровнями экспозиции можно считать показателем эффекта.
Как и простые показатели частоты, показатели эффекта должны представляться вместе с оценкой их точности. И здесь точность наилучшим образом характеризуется величиной доверительного интервала.
Вероятность того, что истинное значение показателя соответствует некоторой точке в пределах доверительного интервала, изменяется на протяжении интервала: вероятность существования такой точки постепенно снижается по мере приближения к его границам. Соответственно, на пороге доверительного интервала не происходит резкого падения вероятности. Поэтому нецелесообразно уделять слишком большое внимание точному расположению границ доверительного интервала. Неважно, включается или не включается в него отдельное значение. Иногда для интерпретации полученных результатов существенно определить, включается или не включается в доверительный интервал конкретное значение, соответствующее отсутствию связи между экспозицией и заболеванием. Такое значение составит единицу для относительного риска и отношения шансов и нуль для показателей разности. Интерпретация будет равнозначной критерию значимости гипотезы об отсутствии связи. Поскольку оценка существенности различия показателей менее информативна, чем доверительные интервалы, и легко поддается неверной интерпретации, мы настоятельно рекомендуем пользоваться для оценки точности эпидемиологических данных не критериями значимости, а доверительными интервалами. Более того, мы не рекомендовали бы использование доверительных интервалов просто для определения того, включена ли в интервал величина отсутствия связи, — т.е., использовать доверительный интервал как эквивалент критериев значимости. Дальнейшее обсуждение интерпретации доверительных интервалов и критериев значимости читатель найдет дополнительно.
Мы покажем расчет доверительного интервала для относительного риска в некоторых стандартных эпидемиологических ситуациях. Описание ситуаций, при которых используются показатели разности, следует искать в специальной литературе.
Если число наблюдений достаточно велико, чтобы воспользоваться нормальным распределением, общую формулу 95%-ного доверительного интервала для относительного риска можно рассчитать так:
где е — основание натурального логарифма, приблизительно равное 2,718, а ln — логарифмическая функция по основанию е. натуральный логарифм. Экспонента е в формуле представляет собой выражение того же рода, что использовалось в предыдущем разделе при расчете доверительных интервалов для описательных эпидемиологических показателей. Оно начинается с наблюдаемого числа, в данном случае ln(RR) (см. ниже), к которому прибавляется или от которого отнимается умноженный на 1,96 квадратный корень дисперсии var рассчитываемого числа. Общая формула расчета доверительного интервала для RR опирается на нормальное распределение. Конкретные варианты формулы отличаются только расчетом дисперсии, соответствующим типу конкретного исследования. Включение в формулу постоянной е и натурального логарифма обусловлено крайней асимметричностью распределения возможных значений относительного риска, который не может быть ниже нуля, но не имеет верхнего предела. Такая асимметричность ограничивает применимость нормального распределения, которое является симметричным. Логарифмирование делает распределение значений более симметричным, ограничивая длинный «хвост» больших чисел и вытягивая значение от 0 до 1 в сторону минус бесконечности. Приведенная формула устанавливает симметричные границы доверительного интервала в логарифмическом масштабе, преобразуя их затем в первоначальный масштаб путем потенцирования. Ниже мы приводим конкретные формулы вместе с примерами для некоторых стандартных эпидемиологических ситуаций.
Похожие статьи:
Примите к сведению
Информация на этом сайте представлена в справочных и образовательных целях и не должна быть использована как инструкция по лечению. В любых случаях необходимо консультироваться у врача.
Как рассчитать доверительные интервалы начальной загрузки для результатов машинного обучения в Python
Дата публикации 2017-06-05
Важно представить как ожидаемый навык модели машинного обучения, так и доверительные интервалы для этого навыка модели.
Доверительные интервалы обеспечивают диапазон навыков модели и вероятность того, что навык модели упадет между диапазонами при прогнозировании новых данных. Например, 95% вероятности точности классификации между 70% и 75%.
Надежным способом вычисления доверительных интервалов для алгоритмов машинного обучения является использование начальной загрузки. Это общий метод оценки статистики, который можно использовать для вычисления эмпирических доверительных интервалов, независимо от распределения оценок навыков (например, негауссовский)
В этом посте вы узнаете, как использовать загрузчик для вычисления доверительных интервалов для производительности ваших алгоритмов машинного обучения.
Прочитав этот пост, вы узнаете:
- Как оценить доверительные интервалы статистики с помощью начальной загрузки.
- Как применить этот метод для оценки алгоритмов машинного обучения.
- Как реализовать метод начальной загрузки для оценки доверительных интервалов в Python.
Давайте начнем.
- Обновление июнь / 2017: Исправлена ошибка, при которой в numpy.percentile () предоставлялись неправильные значения. Спасибо, Эли Каверк.
- Обновление март / 2018: Обновлена ссылка на файл набора данных.
Bootstrap Доверительные интервалы
Расчет доверительных интервалов с помощью начальной загрузки включает в себя два этапа:
- Рассчитать популяцию статистики
- Рассчитать доверительные интервалы
1. Рассчитать популяцию статистики
Первым шагом является использование процедуры начальной загрузки для повторной выборки исходных данных и расчета статистики интереса.
Набор данных взят с заменой. Это означает, что каждый раз, когда элемент выбирается из исходного набора данных, он не удаляется, что позволяет снова выбрать этот элемент для образца.
Статистика рассчитывается по выборке и сохраняется таким образом, чтобы мы создавали совокупность интересующей статистики.
Количество повторов начальной загрузки определяет дисперсию оценки, и чем больше, тем лучше, часто сотнями или тысячами.
Мы можем продемонстрировать этот шаг с помощью следующего псевдокода.
statistics = []
for i in bootstraps:
sample = select_sample_with_replacement(data)
stat = calculate_statistic(sample)
statistics.append(stat)2. Рассчитать доверительный интервал
Теперь, когда у нас есть совокупность интересующей статистики, мы можем вычислить доверительные интервалы.
Это делается путем упорядочения статистики, а затем выбора значений в выбранном процентиле для доверительного интервала. Выбранный процентиль в этом случае называется альфа.
Например, если мы заинтересованы в доверительном интервале 95%, то альфа будет 0,95, и мы выберем значение в 2,5% процентиля в качестве нижней границы и 97,5% процентиля в качестве верхней границы интересующей статистики.
Например, если мы вычислили 1000 статистических данных из 1000 выборок начальной загрузки, тогда нижняя граница была бы 25-м значением, а верхняя граница была бы 975-м значением, предполагая, что список статистики был упорядочен.
В этом мы рассчитываем непараметрический доверительный интервал, который не делает никаких предположений о функциональной форме распределения статистики. Этот доверительный интервал часто называют эмпирическим доверительным интервалом.
Мы можем продемонстрировать это с помощью псевдокода ниже.
ordered = sort(statistics)
lower = percentile(ordered, (1-alpha)/2)
upper = percentile(ordered, alpha+((1-alpha)/2))Bootstrap Model Performance
С помощью начальной загрузки можно оценить производительность алгоритмов машинного обучения.
Размер выборки, взятой на каждой итерации, может быть ограничен 60% или 80% доступных данных. Это будет означать, что будут некоторые образцы, которые не включены в образец. Они вызываются из сумки (OOB).
Затем модель может быть обучена на выборке данных на каждой итерации начальной загрузки и оценена на выборках из пакета, чтобы получить статистику производительности, которую можно собрать и из которой можно рассчитать доверительные интервалы.
Мы можем продемонстрировать этот процесс с помощью следующего псевдокода.
statistics = []
for i in bootstraps:
train, test = select_sample_with_replacement(data, size)
model = train_model(train)
stat = evaluate_model(test)
statistics.append(stat)Рассчитать доверительный интервал точности классификации
В этом разделе показано, как использовать загрузчик для расчета эмпирического доверительного интервала для алгоритма машинного обучения в реальном наборе данных с использованием библиотеки машинного обучения Python scikit-learn.
В этом разделе предполагается, что у вас установлены Pandas, NumPy и Matplotlib. Если вам нужна помощь в настройке среды, см. Учебник:
Сначала скачайтеНабор данных индейцев пимаи поместите его в текущий рабочий каталог с именем «pima»–индейцы-diabetes.data.csv” (Обновить:Скачать здесь).
Мы загрузим набор данных с помощью панд.
# load dataset
data = read_csv('pima-indians-diabetes.data.csv', header=None)
values = data.valuesДалее мы настроим загрузчик. Мы будем использовать 1000 итераций начальной загрузки и выберем выборку, размер которой на 50% превышает размер набора данных.
# configure bootstrap
n_iterations = 1000
n_size = int(len(data) * 0.50)Далее мы будем перебирать загрузчик
Образец будет выбран с заменой с использованиемфункция resample ()от склеарн. Все строки, которые не были включены в образец, извлекаются и используются в качестве тестового набора данных. Затем в выборку помещается классификатор дерева решений, который оценивается на тестовом наборе, рассчитывается классификационный балл и добавляется в список баллов, собранных по всем бутстрапам.
# run bootstrap
stats = list()
for i in range(n_iterations):
# prepare train and test sets
train = resample(values, n_samples=n_size)
test = numpy.array([x for x in values if x.tolist() not in train.tolist()])
# fit model
model = DecisionTreeClassifier()
model.fit(train[:,:-1], train[:,-1])
# evaluate model
predictions = model.predict(test[:,:-1])
score = accuracy_score(test[:,-1], predictions)После того, как результаты собраны, создается гистограмма, чтобы дать представление о распределении результатов. Мы обычно ожидаем, что это распределение будет гауссовым, возможно, с перекосом с симметричной дисперсией вокруг среднего.
Наконец, мы можем рассчитать эмпирические доверительные интервалы, используяпроцентиль () функция NumPy, Используется 95% доверительный интервал, поэтому выбираются значения в 2,5 и 97,5 процентилях.
Собрав все это вместе, полный пример приведен ниже.
import numpy
from pandas import read_csv
from sklearn.utils import resample
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from matplotlib import pyplot
# load dataset
data = read_csv('pima-indians-diabetes.data.csv', header=None)
values = data.values
# configure bootstrap
n_iterations = 1000
n_size = int(len(data) * 0.50)
# run bootstrap
stats = list()
for i in range(n_iterations):
# prepare train and test sets
train = resample(values, n_samples=n_size)
test = numpy.array([x for x in values if x.tolist() not in train.tolist()])
# fit model
model = DecisionTreeClassifier()
model.fit(train[:,:-1], train[:,-1])
# evaluate model
predictions = model.predict(test[:,:-1])
score = accuracy_score(test[:,-1], predictions)
print(score)
stats.append(score)
# plot scores
pyplot.hist(stats)
pyplot.show()
# confidence intervals
alpha = 0.95
p = ((1.0-alpha)/2.0) * 100
lower = max(0.0, numpy.percentile(stats, p))
p = (alpha+((1.0-alpha)/2.0)) * 100
upper = min(1.0, numpy.percentile(stats, p))
print('%.1f confidence interval %.1f%% and %.1f%%' % (alpha*100, lower*100, upper*100))Выполнение примера выводит точность классификации на каждую итерацию начальной загрузки.
Создана гистограмма из 1000 показателей точности, показывающая распределение, подобное гауссовскому.
Наконец, сообщаются доверительные интервалы, показывающие, что существует 95% вероятность того, что доверительный интервал 64,4% и 73,0% покрывает истинное мастерство модели.
...
0.646288209607
0.682203389831
0.668085106383
0.673728813559
0.686021505376
95.0 confidence interval 64.4% and 73.0%Этот же метод можно использовать для вычисления доверительных интервалов для любых других оценок ошибок, таких как среднеквадратическая ошибка для алгоритмов регрессии.
Дальнейшее чтение
Этот раздел предоставляет дополнительные ресурсы по доверительным интервалам начальной загрузки и начальной загрузки.
Резюме
В этой статье вы узнали, как использовать загрузчик для вычисления доверительных интервалов для алгоритмов машинного обучения.
В частности, вы узнали:
- Как рассчитать загрузочную оценку доверительных интервалов статистики из набора данных.
- Как применить бутстрап для оценки алгоритмов машинного обучения.
- Как рассчитать доверительные интервалы начальной загрузки для алгоритмов машинного обучения в Python.
У вас есть вопросы о доверительных интервалах?
Задайте свои вопросы в комментариях ниже.
Оригинальная статья
Уровень уверенности: что это такое?
Определения статистики> Уровень достоверности
Когда в СМИ сообщается об опросе, в его результаты часто включается уровень достоверности. Например, опрос может сообщить уровень достоверности 95%. Но что конкретно это означает? На первый взгляд может показаться, что это 95% точности. Это , близкое к к истине, но, как и многие другие статистические данные, на самом деле оно немного более определено.
Пример из реальной жизни
Пример: в недавней статье в Rasmussen Reports говорится, что «38% вероятных избирателей США теперь говорят, что их медицинское страхование изменилось из-за Obamacare». Если вы прокрутите статью до конца, вы увидите такую строку: «Погрешность выборки составляет +/- 3 процентных пункта с уровнем достоверности 95% ».
Непрактично опрашивать всех 300 миллионов жителей США, поэтому невозможно точно знать, сколько людей на самом деле ответят: «Да, моя медицинская страховка изменилась.«Мы берем выборку (скажем, 2000 человек) и, используя хорошие статистические методы, такие как простая случайная выборка, делаем наше« лучшее предположение »о том, какова эта фактическая цифра (мы называем эту неизвестную цифру параметром населения). 95-процентный уровень уверенности говорит о том, что если бы опрос или опрос повторялись снова и снова, результаты в 95% случаев совпадали бы с результатами фактического населения.
А как насчет «+/- 3 процентных пункта»?
Ширина ширины доверительного интервала говорит нам больше о том, насколько мы уверены (или не уверены) в истинной численности населения.Эта ширина указывается как плюс или минус (в данном случае +/- 3) и называется доверительным интервалом . Когда интервал и уровень достоверности сложены вместе, вы получите разброс в процентах. В этом случае вы ожидаете, что результаты будут от 35 (38-3) до 41 (35 + 3) процентов, в 95% случаев.
Факторы, влияющие на доверительные интервалы (ДИ)
- Размер популяции: обычно это не влияет на CI, но может быть фактором, если вы работаете с небольшими и известными группами людей.
- Размер выборки: чем меньше ваша выборка, тем меньше вероятность того, что вы будете уверены, что результаты отражают истинный параметр генеральной совокупности.
- Процент: экстремальные ответы дают большую точность. Например, если 99 процентов избирателей поддерживают однополые браки, вероятность ошибки невелика. Однако, если 49,9 процента голосующих «за», а 50,1 процента – «против», то вероятность ошибки выше.
0% и 100% доверительный уровень
Уровень достоверности 0% означает, что вы вообще не уверены, что, если вы повторите опрос, вы получите те же результаты.Уровень достоверности 100% означает, что нет никаких сомнений в том, что , если вы повторите опрос, вы получите те же результаты. На самом деле, вы никогда не публиковали бы результаты опроса, если бы у вас не было никакой уверенности в том, что ваша статистика точна (вы бы, вероятно, повторили опрос, используя более совершенные методы). В статистике не существует 100-процентного уровня достоверности, если вы не опросили все население – и даже в этом случае вы, вероятно, не сможете быть на 100 процентов уверены, что ваш опрос не был подвержен каким-либо ошибкам или предвзятости.
Доверительный коэффициент
Коэффициент достоверности – это уровень достоверности, выраженный как пропорция, а не как процент. Например, если у вас уровень достоверности 99%, коэффициент достоверности будет 0,99.
В целом, чем выше коэффициент, тем больше вы уверены, что ваши результаты точны. Например, коэффициент 0,99 более точен, чем коэффициент 0,89. Крайне редко можно увидеть коэффициент 1 (это означает, что вы уверены, что ваши результаты полностью, 100% точны).Нулевой коэффициент означает, что вы вообще не уверены, что ваши результаты точны.
В следующей таблице перечислены коэффициенты достоверности и эквивалентные уровни достоверности.
| Доверительный коэффициент (1 – α) | Уровень достоверности (1 – α * 100%) |
| 0,90 | 90% |
| 0,95 | 95% |
| 0,99 | 99% |
Ссылки
Бейер, В.H. Стандартные математические таблицы CRC, 31-е изд. Бока Ратон, Флорида: CRC Press, стр. 536 и 571, 2002.
Gonick, L. (1993). Мультяшный справочник по статистике. HarperPerennial.
Кляйн, Г. (2013). Карикатура Введение в статистику. Hill & Wamg.
Vogt, W.P. (2005). Словарь статистики и методологии: нетехническое руководство для социальных наук. МУДРЕЦ.
Нужна помощь с домашним заданием или контрольным вопросом? С помощью Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области.Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
Таблица Т-распределения (один хвост и два хвоста)
Посмотрите видео, чтобы получить краткий обзор того, как читать таблицу распределения t, или просмотрите таблицы ниже.
Для получения дополнительной информации о частях таблицы t, в том числе о том, как их вычислить, см .: степени свободы и альфа-уровень.
Т-образный распределительный стол (один хвост)
Чтобы просмотреть таблицу Т-распределения для двух хвостов, щелкните здесь.
| df | а = 0,1 | 0,05 | 0,025 | 0,01 | 0,005 | 0,001 | 0,0005 |
|---|---|---|---|---|---|---|---|
| ∞ | т a = 1,282 | 1,645 | 1,960 | 2,326 | 2,576 | 3,091 | 3,291 |
| 1 | 3.078 | 6,314 | 12,706 | 31,821 | 63,656 | 318,289 | 636,578 |
| 2 | 1.886 | 2,920 | 4,303 | 6,965 | 9,925 | 22,328 | 31,600 |
| 3 | 1,638 | 2,353 | 3,182 | 4,541 | 5,841 | 10,214 | 12,924 |
| 4 | 1.533 | 2,132 | 2,776 | 3,747 | 4.604 | 7,173 | 8,610 |
| 5 | 1.476 | 2,015 | 2,571 | 3,365 | 4,032 | 5,894 | 6,869 |
| 6 | 1,440 | 1,943 | 2.447 | 3,143 | 3.707 | 5,208 | 5,959 |
| 7 | 1.415 | 1,895 | 2,365 | 2,998 | 3,499 | 4,785 | 5,408 |
| 8 | 1,397 | 1,860 | 2.306 | 2,896 | 3,355 | 4,501 | 5,041 |
| 9 | 1,383 | 1,833 | 2,262 | 2,821 | 3,250 | 4,297 | 4,781 |
| 10 | 1.372 | 1,812 | 2,228 | 2,764 | 3,169 | 4,144 | 4,587 |
| 11 | 1,363 | 1,796 | 2.201 | 2,718 | 3,106 | 4,025 | 4,437 |
| 12 | 1,356 | 1,782 | 2,179 | 2,681 | 3,055 | 3,930 | 4,318 |
| 13 | 1.350 | 1.771 | 2,160 | 2,650 | 3,012 | 3,852 | 4,221 |
| 14 | 1,345 | 1,761 | 2,145 | 2,624 | 2,977 | 3,787 | 4,140 |
| 15 | 1,341 | 1,753 | 2,131 | 2,602 | 2,947 | 3,733 | 4,073 |
| 16 | 1.337 | 1,746 | 2,120 | 2,583 | 2,921 | 3.686 | 4,015 |
| 17 | 1,333 | 1,740 | 2,110 | 2,567 | 2,898 | 3.646 | 3,965 |
| 18 | 1,330 | 1,734 | 2,101 | 2,552 | 2,878 | 3,610 | 3,922 |
| 19 | 1.328 | 1,729 | 2,093 | 2,539 | 2,861 | 3,579 | 3.883 |
| 20 | 1,325 | 1,725 | 2,086 | 2,528 | 2,845 | 3,552 | 3,850 |
| 21 | 1,323 | 1,721 | 2,080 | 2,518 | 2,831 | 3,527 | 3,819 |
| 22 | 1.321 | 1,717 | 2,074 | 2,508 | 2,819 | 3,505 | 3,792 |
| 23 | 1,319 | 1,714 | 2,069 | 2,500 | 2,807 | 3,485 | 3,768 |
| 24 | 1,318 | 1,711 | 2,064 | 2.492 | 2,797 | 3,467 | 3,745 |
| 25 | 1.316 | 1.708 | 2,060 | 2.485 | 2,787 | 3,450 | 3,725 |
| 26 | 1,315 | 1.706 | 2,056 | 2.479 | 2,779 | 3,435 | 3.707 |
| 27 | 1,314 | 1.703 | 2,052 | 2.473 | 2,771 | 3,421 | 3.689 |
| 28 | 1.313 | 1.701 | 2,048 | 2,467 | 2,763 | 3,408 | 3.674 |
| 29 | 1,311 | 1,699 | 2,045 | 2.462 | 2,756 | 3,396 | 3,660 |
| 30 | 1,310 | 1.697 | 2,042 | 2.457 | 2,750 | 3,385 | 3.646 |
| 60 | 1.296 | 1.671 | 2 000 | 2.390 | 2,660 | 3,232 | 3,460 |
| 120 | 1,289 | 1,658 | 1,980 | 2,358 | 2,617 | 3,160 | 3,373 |
| 1000 | 1,282 | 1.646 | 1,962 | 2,330 | 2,581 | 3,098 | 3,300 |
| df | а = 0.2 | 0,10 | 0,05 | 0,02 | 0,01 | 0,002 | 0,001 |
|---|---|---|---|---|---|---|---|
| ∞ | т a = 1,282 | 1,645 | 1,960 | 2,326 | 2,576 | 3,091 | 3,291 |
| 1 | 3,078 | 6,314 | 12,706 | 31,821 | 63,656 | 318,289 | 636,578 |
| 2 | 1.886 | 2,920 | 4,303 | 6,965 | 9,925 | 22,328 | 31,600 |
| 3 | 1,638 | 2,353 | 3,182 | 4,541 | 5,841 | 10,214 | 12,924 |
| 4 | 1,533 | 2,132 | 2,776 | 3,747 | 4.604 | 7,173 | 8,610 |
| 5 | 1.476 | 2,015 | 2,571 | 3,365 | 4,032 | 5,894 | 6,869 |
| 6 | 1,440 | 1,943 | 2.447 | 3,143 | 3.707 | 5,208 | 5,959 |
| 7 | 1,415 | 1,895 | 2,365 | 2,998 | 3,499 | 4,785 | 5,408 |
| 8 | 1.397 | 1,860 | 2.306 | 2,896 | 3,355 | 4,501 | 5,041 |
| 9 | 1,383 | 1,833 | 2,262 | 2,821 | 3,250 | 4,297 | 4,781 |
| 10 | 1,372 | 1,812 | 2,228 | 2,764 | 3,169 | 4,144 | 4,587 |
| 11 | 1.363 | 1,796 | 2.201 | 2,718 | 3,106 | 4,025 | 4,437 |
| 12 | 1,356 | 1,782 | 2,179 | 2,681 | 3,055 | 3,930 | 4,318 |
| 13 | 1,350 | 1.771 | 2,160 | 2,650 | 3,012 | 3,852 | 4,221 |
| 14 | 1.345 | 1,761 | 2,145 | 2,624 | 2,977 | 3,787 | 4,140 |
| 15 | 1,341 | 1,753 | 2,131 | 2,602 | 2,947 | 3,733 | 4,073 |
| 16 | 1,337 | 1,746 | 2,120 | 2,583 | 2,921 | 3.686 | 4,015 |
| 17 | 1.333 | 1,740 | 2,110 | 2,567 | 2,898 | 3.646 | 3,965 |
| 18 | 1,330 | 1,734 | 2,101 | 2,552 | 2,878 | 3,610 | 3,922 |
| 19 | 1,328 | 1,729 | 2,093 | 2,539 | 2,861 | 3,579 | 3.883 |
| 20 | 1.325 | 1,725 | 2,086 | 2,528 | 2,845 | 3,552 | 3,850 |
| 21 | 1,323 | 1,721 | 2,080 | 2,518 | 2,831 | 3,527 | 3,819 |
| 22 | 1,321 | 1,717 | 2,074 | 2,508 | 2,819 | 3,505 | 3,792 |
| 23 | 1.319 | 1,714 | 2,069 | 2,500 | 2,807 | 3,485 | 3,768 |
| 24 | 1,318 | 1,711 | 2,064 | 2.492 | 2,797 | 3,467 | 3,745 |
| 25 | 1,316 | 1.708 | 2,060 | 2.485 | 2,787 | 3,450 | 3,725 |
| 26 | 1.315 | 1.706 | 2,056 | 2.479 | 2,779 | 3,435 | 3.707 |
| 27 | 1,314 | 1.703 | 2,052 | 2.473 | 2,771 | 3,421 | 3.689 |
| 28 | 1,313 | 1.701 | 2,048 | 2,467 | 2,763 | 3,408 | 3.674 |
| 29 | 1.311 | 1,699 | 2,045 | 2.462 | 2,756 | 3,396 | 3,660 |
| 30 | 1,310 | 1.697 | 2,042 | 2.457 | 2,750 | 3,385 | 3.646 |
| 60 | 1,296 | 1.671 | 2 000 | 2.390 | 2,660 | 3,232 | 3,460 |
| 120 | 1.289 | 1,658 | 1,980 | 2,358 | 2,617 | 3,160 | 3,373 |
| 8 | 1,282 | 1,645 | 1,960 | 2,326 | 2,576 | 3,091 | 3,291 |
Ссылки
Бейер, В. (2017). Справочник таблиц вероятностей и статистики 2-е издание. CRC Press.
————————————————– —————————-
Нужна помощь с домашним заданием или контрольным вопросом? С помощью Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области.Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
Определение, пошаговые статьи, видео
В комплекте:
- Что такое Т-распределение?
- TI 83 ступени.
- TI 89 ступеней.
- Другие статьи о T-Dist
Распределение T (также называемое распределением T Стьюдента ) – это семейство распределений, которые выглядят почти идентичными кривой нормального распределения, только немного короче и толще.Распределение t используется вместо нормального распределения, когда у вас есть небольшие выборки (подробнее об этом см: t-оценка по сравнению с z-оценкой). Чем больше размер выборки, тем больше t-распределение похоже на нормальное распределение. Фактически, для размеров выборки более 20 (например, с большим количеством степеней свободы) распределение почти точно такое же, как и нормальное распределение.
Как рассчитать балл для распределения T
Когда вы посмотрите на таблицы t-распределения, вы увидите, что вам нужно знать «df.Это означает «степени свободы» и составляет всего лишь размер выборки минус один.
Шаг 1. Вычтите единицу из размера выборки. Это будут ваши степени свободы.
Шаг 2: Найдите df в левой части таблицы t-распределения. Найдите столбец под вашим альфа-уровнем (альфа-уровень обычно указывается вам в вопросе).
Для получения более подробных инструкций, включая видео , см .: t формула оценки.
Использует
T-распределение (и связанные с ним t-баллы) используются при проверке гипотез, когда вы хотите выяснить, следует ли вам принять или отклонить нулевую гипотезу.
Центральная область на этом графике – это область приема, а хвост – область или области отклонения. На этом конкретном графике двустороннего теста область отклонения заштрихована синим цветом. Область в хвосте может быть описана с помощью z-значений или t-показателей. Например, изображение слева показывает область в 5% хвостов (по 2,5% с каждой стороны). Z-оценка будет 1,96 (из z-таблицы), что представляет собой 1,96 стандартного отклонения от среднего. Нулевая гипотеза будет отклонена, если z меньше -1.96 или больше 1,96.
Как правило, это распределение используется, когда у вас небольшой размер выборки (до 30) или вы не знаете стандартное отклонение генеральной совокупности. Для практических целей (то есть в реальном мире) это почти всегда так. Итак, в отличие от вашего класса элементарной статистики, вы, вероятно, будете использовать его в реальных жизненных ситуациях чаще, чем нормальное распределение. Если размер вашей выборки достаточно велик, два распределения практически одинаковы.
Посмотрите видео или прочтите ниже:
Взгляните на традиционную T-таблицу из учебников, и вы действительно найдете много T-таблиц, которые могут быть немного подавляющими.Вместо того, чтобы изучать таблицы, вы можете использовать графический калькулятор TI 83 , чтобы помочь вам найти значения T.
Вас могут попросить найти площадь под кривой T или (как Z-баллы) вам может быть предоставлена определенная область и предложено найти T-балл.
В поисках критического значения TI 83
Щелкните здесь, чтобы увидеть нашу статью о поиске критических значений T на TI 83.
T на TI 83: шаги
Пример задачи : Найдите площадь под кривой T со степенями свободы 10 для P (1 ≤ X ≤ 2).Используйте t-распределение на TI 83.
Шаг 1: Нажмите 2nd VARS 5, чтобы выбрать tcdf (.
Шаг 2: Введите нижнюю границу, верхнюю границу и степени свободы. Нижняя граница – это наименьшее число, а верхняя граница – наибольшее число: 1,2,10
.Теперь на экране должно отображаться tcdf (1,2,10)
Шаг 3: Нажмите ENTER. Ответ: ,13752549 , или примерно 13,38% .
Вот как найти распределение T на TI 83!
Посетите мой канал YouTube, чтобы получить дополнительную статистику, помощь и советы.
По большинству вопросов о Т-распределении вам обычно дается вся информация, необходимая для подключения к калькулятору и получения T-балла . Вас могут попросить найти площадь под кривой T или (как Z-баллы) вам может быть предоставлена определенная область и предложено найти T-балл.
РаспределениеT на TI 89 шагов
Примечание : Для этих процедур необходимо установить редактор STAT / LIST. Вы можете бесплатно скачать копию с сайта TI.
Пример задачи : Найдите площадь под кривой T со степенями свободы 10 для P (1 ≤ X ≤ 2).
Шаг 1: Нажмите ПРИЛОЖЕНИЯ.
Шаг 2: Дважды нажмите ENTER, чтобы войти в редактор STATS / LIST.
Шаг 3: Нажмите F5 для F5Distr .
Шаг 4: Выберите 6 для 6: t Cdf .
Шаг 5: Введите 1 в поле для Нижнее значение .
Шаг 6: Введите 2 в поле для Верхнее значение .
Шаг 7: Введите 10 в поле для градусов свободы, df .
Шаг 8: Нажмите ENTER. Это возвращает результат .133753 .
Пример задачи: найти оценку T со значением 0,25 слева и df 10.
Шаг 1: Нажмите ПРИЛОЖЕНИЯ.
Шаг 2: Дважды нажмите ENTER, чтобы войти в редактор STAT / LIST. 99 в поле для нижнего значения.
Вот как найти T-распределение на TI 89!
- Как построить доверительный интервал на основе данных с помощью t-Dist.
- T-тест: что это такое и как его рассчитать.
- Т-тест независимых образцов.
- Приближение Саттертуэйта.
- Формула T-Score.
Посетите наш канал YouTube, чтобы увидеть сотни статистических видео.
Список литературы
Бейер, В. Х. Стандартные математические таблицы CRC, 31-е изд.Бока Ратон, Флорида: CRC Press, стр. 536 и 571, 2002.
Фишер, Р. А. Статистические методы для научных работников, 10-е изд. Эдинбург: Оливер и Бойд, 1948.
Шпигель, Очерк теории и проблем теории вероятностей и статистики М. Р. Шаума. Нью-Йорк: McGraw-Hill, стр. 116-117, 1992.
Нужна помощь с домашним заданием или контрольным вопросом? С помощью Chegg Study вы можете получить пошаговые ответы на свои вопросы от эксперта в данной области.Ваши первые 30 минут с репетитором Chegg бесплатны!
Комментарии? Нужно опубликовать исправление? Пожалуйста, оставьте комментарий на нашей странице в Facebook .
Доверительные интервалы
Интервал 4 плюс-минус 2
Доверительный интервал – это диапазон значений , мы почти уверены, что наше истинное значение находится в пределах .
Пример: Средняя высота
Мы измеряем рост 40 случайно выбранных мужчин и получаем средний рост 175 см ,
Нам также известно, что стандартное отклонение роста мужчин составляет 20 см .
95% доверительный интервал (мы покажем, как его вычислить позже):
175 см ± 6,2 см
Это говорит о том, что истинное среднее значение ВСЕХ мужчин (если бы мы могли измерить их рост), вероятно, находится в диапазоне от 168,8 до 181,2 см.
А может и не быть!
«95%» означает, что 95% экспериментов, подобных тому, что мы только что провели, будут включать истинное среднее значение, а 5% – не .
Таким образом, вероятность того, что наш доверительный интервал НЕ включает истинное среднее значение, составляет 1 из 20 (5%).
Расчет доверительного интервала
Шаг 1 : начать с
Примечание: мы должны использовать стандартное отклонение для всей совокупности , но во многих случаях мы этого не узнаем.
Мы можем использовать стандартное отклонение для выборки , если у нас достаточно наблюдений (по крайней мере, n = 30, надеюсь, больше).
В нашем примере:
- количество наблюдений n = 40
- среднее X = 175
- стандартное отклонение с = 20
Шаг 2 : решите, какой доверительный интервал мы хотим: 95% или 99% являются обычным выбором. Затем найдите здесь значение «Z» для этого доверительного интервала:
| Доверие Интервал | Z |
| 80% | 1.282 |
| 85% | 1,440 |
| 90% | 1,645 |
| 95% | 1,960 |
| 99% | 2,576 |
| 99,5% | 2,807 |
| 99,9% | 3,291 |
Для 95% значение Z равно 1,960
Шаг 3 : используйте это значение Z в этой формуле для доверительного интервала
X ± Z с √n
Где:
- X – среднее значение
- Z – выбранное значение Z из таблицы выше
- s – стандартное отклонение
- n – количество наблюдений
А у нас:
175 ± 1.960 × 20 √40
Это:
175 см ± 6,20 см
Другими словами: от 168,8 см до 181,2 см
Значение после ± называется пределом погрешности
Предел погрешности в нашем примере 6,20 см
Калькулятор
У нас есть калькулятор доверительного интервала, который облегчит вам жизнь.
Симулятор
У нас также есть очень интересный симулятор нормального распределения.где мы можем начать с некоторого теоретического «истинного» среднего и стандартного отклонения, а затем взять случайные выборки.
Это помогает нам понять, как случайные выборки иногда могут быть очень хорошими или плохими при представлении лежащих в основе истинных значений.
Другой пример
Пример: Яблоневый сад
Яблоки достаточно большие?
На деревьях сотни яблок, поэтому вы случайным образом выбираете 46 яблок и получаете:
- Среднее из 86
- стандартное отклонение 6.2
Итак, посчитаем:
X ± Z с √n
Мы знаем:
- X – это среднее значение = 86
- Z – значение Z = 1,960 (из таблицы выше для 95%)
- с – стандартное отклонение = 6,2
- n – количество наблюдений = 46
86 ± 1,960 × 6,2 √46 = 86 ± 1.79
Таким образом, истинное среднее значение (всех сотен яблок) составляет , вероятно, находится между 84,21 и 87,79
Истинное Среднее
А теперь представьте, что мы можем сразу собрать ВСЕ яблоки и измерить их ВСЕ с помощью упаковочной машины (такая роскошь, как правило, не встречается в статистике!)
И истинное среднее значение оказывается 84,9
Разложим все яблоки на земле от самых маленьких до самых больших:
Каждое яблоко – это зеленая точка,
, за исключением наших наблюдений, которые синие
Наш результат не был точным… это случайно, в конце концов … но истинное среднее находится в пределах нашего доверительного интервала 86 ± 1,79 (другими словами от 84,21 до 87,79)
Теперь истинное среднее значение может не находиться в пределах доверительного интервала , но в 95% случаев оно будет!
95% всех «95% доверительных интервалов» будут включать истинное среднее значение.
Может быть, у нас был этот образец со средним значением 83,5:
Каждое яблоко – зеленая точка,
наши наблюдения отмечены фиолетовым
Это не включает истинное среднее значение. Ожидайте, что это произойдет в 5% случаев при доверительном интервале 95%.
Итак, как мы узнаем, является ли взятый нами образец одним из «счастливых» 95% или неудачных 5%? Если мы не сможем измерить все население, как указано выше, мы просто не знаем .
Это риск при выборке, у нас может быть плохая выборка.
Пример из исследования
Вот доверительный интервал, использованный в фактических исследованиях дополнительных упражнений для пожилых людей :
Что там говорится? Глядя на «Мужскую» строчку мы видим:
- 1226 мужчин (47.6% всех людей)
- имел “HR” (см. Ниже) со средним значением 0,92 ,
- и 95% доверительный интервал (95% ДИ) от 0,88 до 0,97 (что также составляет 0,92 ± 0,05)
«ЧСС» – это показатель пользы для здоровья (чем ниже, тем лучше), поэтому эта линия говорит о том, что истинная польза от упражнений (для более широкой популяции мужчин) (для более широкой популяции мужчин) с вероятностью 95% находится между 0,88 и 0,97
* Примечание для любопытных: «ЧСС» часто используется в медицинских исследованиях и означает «коэффициент опасности», где чем ниже, тем лучше, поэтому ЧСС равняется 0.92 означает, что у испытуемых было лучше, а 1,03 означает немного хуже.
Стандартное нормальное распределение
Все это основано на идее стандартного нормального распределения, где значение Z – это “Z-оценка”.
Например, Z для 95% составляет 1,960, и здесь мы видим, что диапазон от -1,96 до +1,96 включает 95% всех значений:
От -1,96 до +1,96 стандартное отклонение составляет 95%
Если применить это к нашему образцу, то это выглядит так:
Также с -1.От 96 до +1,96 стандартного отклонения, поэтому включает 95%
Заключение
Доверительный интервал основан на среднем и стандартном отклонении. Его формула:
X ± Z с √n
Где:
- X – среднее значение
- Z – значение Z из таблицы ниже
- s – стандартное отклонение
- n – количество наблюдений
| Доверие Интервал | Z |
| 80% | 1.282 |
| 85% | 1,440 |
| 90% | 1,645 |
| 95% | 1,960 |
| 99% | 2,576 |
| 99,5% | 2,807 |
| 99,9% | 3,291 |
Доверительный интервал для среднего
Доверительный интервал в среднем
Автор (ы)
Дэвид М.переулок Помогите поддержать этот бесплатный сайт, купив свои книги на Amazon по одной из этих ссылок:
Naked Statistics: Stripping the Dread of the Data
Статистика
, 4-е издание
Статистика для чайников (для чайников (образ жизни))
Предварительные требования
Области При нормальном распределении, выборка Распределение среднего, Введение к оценке, введение до доверительных интерваловЦели обучения
- Используйте калькулятор обратного нормального распределения, чтобы найти значение z использовать для доверительного интервала
- Вычислить доверительный интервал среднего значения, когда σ равно известно
- Определите, следует ли использовать t-распределение или нормальное распределение
- Вычислить доверительный интервал для среднего значения при оценке σ
Просмотр мультимедийной версии
Когда вы вычисляете уверенность интервал от среднего, вы вычисляете среднее значение выборки, чтобы оценить среднее значение населения.Очевидно, если вы уже знали среднее значение для генеральной совокупности, доверительный интервал не потребуется. Однако, чтобы объяснить, как строятся доверительные интервалы, мы будем работать в обратном направлении и начнем с предположения характеристик населения. Затем мы покажем, как можно использовать образцы данных. используется для построения доверительного интервала.
Предположим, что веса 10-летних детей обычно распределяются со средним значением 90 и стандартным отклонением из 36.Каково выборочное распределение среднего для выборки размер 9? Напомним из раздела о выборочном распределении среднего значения выборки распределение – μ, а стандартное ошибка среднего
Для данного примера выборочное распределение среднего имеет среднее значение 90 и стандартное отклонение 36/3 = 12. Обратите внимание, что стандартное отклонение выборочного распределения это стандартная ошибка.На рисунке 1 показано это распределение. Затененный площадь представляет собой средние 95% распределения и простирается с 66,48 до 113,52. Эти пределы были вычислены путем сложения и вычитая 1,96 стандартного отклонения из среднего значения 90 как следует:
90 – (1,96) (12) = 66,48
90 + (1,96) (12) = 113,52
Значение 1,96 основано на том факте, что 95% области нормального распределения находится в пределах 1.96 стандартных отклонений среднего; 12 – стандартная ошибка среднего.
Рисунок 1. Выборочное распределение среднее значение для N = 9. Средние 95% распределения – это заштрихованные.
Рисунок 1 показывает, что 95% средств больше не используются. чем на 23,52 единицы (1,96 стандартного отклонения) от среднего значения 90.Теперь рассмотрим вероятность того, что среднее значение выборки вычислено в случайной выборке находится в пределах 23,52 единиц от среднего значения генеральной совокупности из 90. Поскольку 95% распределения находится в пределах 23,52 от 90, вероятность того, что среднее значение по любой данной выборке будет в пределах 23,52 от 90 составляет 0,95. Это означает, что если мы неоднократно вычислить среднее значение (M) из выборки и создать интервал ранжирования от M – 23,52 до M + 23,52, этот интервал будет содержать популяцию означают 95% случаев.В общем, вы вычисляете 95% доверительный интервал для среднего значения по следующей формуле:
Нижний предел = M – Z ,95 σ M
Верхний предел = M + Z ,95 σ M
, где Z .95 – номер стандарта требуются отклонения от среднего нормального распределения содержать 0,95 площади и σ M стандартная ошибка среднего.
Если вы внимательно посмотрите на эту формулу уверенности интервале, вы заметите, что вам нужно знать стандартное отклонение (σ) чтобы оценить среднее значение. Это может показаться нереальным, и Это. Однако вычисление доверительного интервала, когда σ равно знать легче, чем когда необходимо оценить σ, и служит педагогическая цель. Позже в этом разделе мы покажем, как для вычисления доверительного интервала для среднего, когда σ имеет быть оцененным.
Предположим, что были выбраны следующие пять чисел из нормального распределения со стандартным отклонением 2,5: 2, 3, 5, 6 и 9. Чтобы вычислить доверительный интервал 95%, запустите путем вычисления среднего и стандартной ошибки:
M = (2 + 3 + 5 + 6 + 9) / 5 = 5.
σ M = =
1.118.
Z .95 можно найти с помощью обычного
калькулятор распределения и указав, что заштрихованная область
равно 0.95 и указав, что вы хотите, чтобы область находилась между
точки отсечки. Как показано на рисунке 2, значение составляет 1,96. Если бы ты хотел
чтобы вычислить доверительный интервал 99%, вы должны установить
заштрихованная область до 0,99, и результат будет 2,58.
Рисунок 2. 95% площади находится между -1,96 и 1,96.
Обычный Калькулятор распределения
Доверительный интервал может быть вычислен следующим образом:
Нижний предел = 5 – (1.96) (1,118) = 2,81
Верхний предел = 5 + (1,96) (1,118) = 7,19
Вы должны использовать t распространение, а не нормальное распределение, когда дисперсия неизвестна и должна быть оценена из выборочных данных. Когда размер выборки большой, скажем, 100 или выше, t-распределение очень похоже на стандартное нормальное распределение. Однако при меньшем размере выборки t распределение лептокуртическое, что означает, что у него относительно больше очков в хвосте, чем у него нормальное распределение.В результате вам нужно расширять от среднего, чтобы содержать заданную долю площади. Отзывать что при нормальном распределении 95% распределения находится в пределах 1,96 стандартного отклонения среднего. Используя t-распределение, если у вас размер выборки всего 5, 95% площади находится в пределах 2,78 стандартного отклонения среднего. Поэтому стандарт ошибка среднего будет умножена на 2,78, а не на 1.96.
Значения t, которые будут использоваться в доверительном интервале можно посмотреть в таблице t-распределения. Маленькая версия такой таблицы приведена в таблице 1. Первый столбец df означает для степеней свободы и для доверительных интервалов в среднем, df равно N – 1, где N – размер выборки.
Таблица 1. Сокращенная таблица t.
| df | 0.95 | 0,99 |
|---|---|---|
| 2 | 4,303 | 9,925 |
| 3 | 3,182 | 5.841 |
| 4 | 2,776 | 4,604 |
| 5 | 2,571 | 4,032 |
| 8 | 2.306 | 3,355 |
| 10 | 2,228 | 3,169 |
| 20 | 2,086 | 2.845 |
| 50 | 2,009 | 2,678 |
| 100 | 1,984 | 2.626 |
Вы также можете использовать “обратный t Распределение “калькулятор, чтобы найти значения t для использования в доверительных интервалах. Вы узнаете больше о t-распределении в следующем разделе.
Предположим, что выбраны следующие пять чисел. из нормального распределения: 2, 3, 5, 6 и 9 и что стандартное отклонение не известно.Первые шаги – вычислить образец среднее и дисперсия:
M = 5
с 2 = 7,5
Следующим шагом является оценка стандартной ошибки среднего. Если мы знали дисперсию населения, мы могли бы использовать следующие формула:
Вместо этого мы вычисляем оценку стандартной ошибки (s M ):
= 1,225
Следующий шаг – найти значение t.В виде из таблицы 1 видно, что значение 95% -ного интервала для df = N – 1 = 4 равно 2,776. Затем вычисляется доверительный интервал. так же, как и при σ M . Единственный Отличия в том, что s M и t скорее чем σ M и Z.
Нижний предел = 5 – (2,776) (1,225) = 1,60
Верхний предел = 5 + (2,776) (1,225) = 8,40
В более общем плане формула 95% достоверности интервал в среднем:
Нижний предел = M – (t CL ) (s M )
Верхний предел = M + (t CL ) (s M )
где M – выборочное среднее, т CL t для желаемого уровня достоверности (0.95 в приведенном выше примере), и s M – оцененная стандартная ошибка среднего.
Закончим разбором Струпа Данные. В частности, мы вычислим доверительный интервал по среднему баллу разницы. Напомним, что 47 субъектов назвали цвет чернил, которыми были написаны слова. Названия противоречили друг другу чтобы, например, они назвали цвет чернил слова «синий» написано красными чернилами.В правильный ответ – сказать “красный” и игнорировать факт что слово “синий”. Во втором случае испытуемые называли цвет чернил цветных прямоугольников.
Таблица 2. Время отклика в секундах для 10 испытуемых.
| Именование цветного прямоугольника | Вмешательство | Разница |
|---|---|---|
| 17 | 38 | 21 год |
| 15 | 58 | 43 год |
| 18 | 35 год | 17 |
| 20 | 39 | 19 |
| 18 | 33 | 15 |
| 20 | 32 | 12 |
| 20 | 45 | 25 |
| 19 | 52 | 33 |
| 17 | 31 год | 14 |
| 21 год | 29 | 8 |
Таблица 2 показывает разницу во времени между интерференцией. и условия цветового обозначения 10 из 47 испытуемых.Значение разница во времени для всех 47 испытуемых составляет 16,362 секунды, а стандартное отклонение составляет 7,470 секунды. Стандартная ошибка среднее – 1,090. Таблица t показывает критическое значение t для 47 – 1 = 46 степеней свободы составляет 2,013 (для 95% доверительного интервала). Поэтому уверенность интервал вычисляется следующим образом:
Нижний предел = 16,362 – (2,013) (1,090) = 14,17
Верхний предел = 16.362 + (2,013) (1,090) = 18,56
Следовательно, интерференционный эффект (разность) для всего население, вероятно, будет между 14,168 и 18,555 секунд.
Обязательно поместите файл данных в каталог по умолчанию.
Файл данных data = read.csv (file = “stroop.csv”)
data $ diff = data $ interfer-data $ colors
t.test (data $ diff)
[1] 14.16842 18,55498
attr (, “conf.level”)
[1] 0,95
Пожалуйста, ответьте на вопросы:
Калькулятор доверительного интервала
Используйте этот калькулятор для вычисления доверительного интервала или допустимой погрешности, предполагая, что выборочное среднее, скорее всего, следует нормальному распределению. Используйте калькулятор стандартного отклонения, если у вас есть только необработанные данные.
Что такое доверительный интервал?
В статистике доверительный интервал – это диапазон значений, который определяется с помощью наблюдаемых данных, рассчитанных на желаемом уровне достоверности, который может содержать истинное значение изучаемого параметра.Уровень достоверности, например 95% уровень достоверности, относится к тому, насколько надежна процедура оценки, а не к степени уверенности в том, что вычисленный доверительный интервал содержит истинное значение изучаемого параметра. Желаемый уровень достоверности выбирается до вычисления доверительного интервала и указывает долю доверительных интервалов, которые при построении с учетом выбранного уровня достоверности по бесконечному количеству независимых испытаний будут содержать истинное значение параметра.
Доверительные интервалы обычно записываются как (некоторое значение) ± (диапазон). Диапазон можно записать как фактическое значение или в процентах. Его также можно записать как просто диапазон значений. Например, все следующие эквивалентные доверительные интервалы:
20,6 ± 0,887
или
20,6 ± 4,3%
или
[19,713 – 21,487]
Расчет доверительных интервалов:
Вычисление доверительного интервала включает определение выборочного среднего X и стандартного отклонения генеральной совокупности σ, если это возможно.Если стандартное отклонение генеральной совокупности использовать нельзя, то стандартное отклонение выборки s можно использовать, когда размер выборки больше 30. Для размера выборки больше 30 стандартное отклонение генеральной совокупности и стандартное отклонение выборки будут аналогичными. В зависимости от того, какое стандартное отклонение известно, уравнение, используемое для расчета доверительного интервала, различается. Для целей этого калькулятора предполагается, что стандартное отклонение генеральной совокупности известно или размер выборки достаточно велик, поэтому стандартное отклонение генеральной совокупности и стандартное отклонение выборки аналогичны.Отображается только уравнение для известного стандартного отклонения.
Где Z – значение Z для выбранного уровня достоверности, X – среднее значение выборки, σ – стандартное отклонение, а n – размер выборки. Предполагая следующее с уровнем достоверности 95%:
Х = 22,8
Z = 1.960
σ = 2,7
п = 100
Доверительный интервал:22,8 ± 0,5292
Z-значения для доверительных интервалов
| Уровень достоверности | Значение Z |
| 70% | 1.036 |
| 75% | 1.150 |
| 80% | 1.282 |
| 85% | 1.440 |
| 90% | 1.645 |
| 95% | 1.960 |
| 98% | 2,326 |
| 99% | 2,576 |
| 99,5% | 2,807 |
| 99,9% | 3,291 |
| 99,99% | 3.891 |
| 99,999% | 4,417 |
Доверительный интервал
Статистики используют доверительный интервал для описания степени неопределенности связанный с выборочной оценкой совокупности параметр.
Как интерпретировать доверительные интервалы
Предположим, что 90% доверительный интервал утверждает, что среднее значение по совокупности больше 100 и меньше 200. Как бы вы интерпретировали это утверждение?
Некоторые думают, что с вероятностью 90% Среднее значение популяции находится между 100 и 200.Это неверно. Как и любое население параметр, среднее значение по совокупности является константой, а не случайная переменная. Это не меняется. В вероятность того, что константа попадает в любой заданный диапазон всегда 0,00 или 1,00.
уровень уверенности описывает неопределенность, связанную с методом отбора проб . Предположим, мы использовали тот же метод выборки для выбора разные выборки и для вычисления другой интервальной оценки для каждого образца.Некоторые интервальные оценки будут включать истинное население параметр, а некоторые нет. Уровень достоверности 90% означает что мы ожидаем, что 90% интервальных оценок будут включать показатель численности населения; уровень достоверности 95% означает, что 95% интервалов будут включать параметр; и так далее.
Требования к данным доверительного интервала
Чтобы выразить доверительный интервал, вам понадобятся три части Информация.
Учитывая эти входные данные, диапазон доверительного интервала равен определяется статистикой выборки + Погрешность . И неопределенность, связанная с доверительный интервал определяется доверительным уровнем.
Часто предел погрешности не указывается; вы должны рассчитать это. Ранее мы описывали как вычислить погрешность.
Как построить доверительный интервал
Есть четыре шага для построения доверительного интервала.
- Определите образец статистики. Выберите статистику (например, среднее значение выборки, пропорция выборки), которые вы будете использовать для оценить параметр популяции.
- Выберите уровень достоверности. Как мы отметили в предыдущем разделе, уровень достоверности описывает неопределенность выборки метод. Часто исследователи выбирают уверенность 90%, 95% или 99%. уровни; но можно использовать любой процент.
- Найдите погрешность.Если вы работаете над домашним заданием
проблема или тестовый вопрос, допустимая погрешность может быть указана.
Однако часто вам необходимо вычислить погрешность,
на основе одного из следующих уравнений.
Погрешность = Критическое значение * Стандартное отклонение статистики
Погрешность = Критическое значение * Стандартная ошибка статистики
Для руководства см. как вычислить погрешность. - Укажите доверительный интервал.Неопределенность обозначается
по уровню уверенности. И диапазон уверенности
интервал определяется следующим уравнением.
Доверительный интервал = статистика выборки + Погрешность
В примере задачи в следующем разделе применяются четыре вышеуказанных шага. для построения 95% доверительного интервала для среднего балла. Следующий несколько уроков обсуждают эту тему более подробно.
Калькулятор размера выборки
Как вы уже догадались, четыре шага, необходимые для определения достоверности interval может включать в себя множество трудоемких вычислений.Stat Trek’s Калькулятор размера выборки сделает эту работу за вас – быстро, легко и безошибочный. Помимо построения доверительного интервала, калькулятор создает сводный отчет, в котором перечислены основные результаты и аналитическая документация. техники. Всякий раз, когда вам нужно построить доверительный интервал, рассмотрите с помощью калькулятора размера выборки. В калькулятор бесплатный. Его можно найти в Stat Trek. главное меню на вкладке Stat Tools. Или вы можете нажать кнопку ниже.
Калькулятор размера выборкиПроверьте свое понимание
Проблема 1
Предположим, мы хотим оценить средний вес взрослого мужчины в Округ Декалб, Джорджия. Мы выбираем случайную выборку из 1000 мужчин из население 1000000 человек и взвесьте их. Мы находим, что средний человек в нашей выборке весит 180 фунтов, и стандартное отклонение образец 30 фунтов.Что такое 95% доверительный интервал.
(А) 180 + 1,86
(В) 180 + 3,0
(К) 180 + 5,88
(Г) 180 + 30
(E) Ничего из вышеперечисленного
Решение
Правильный ответ (А). Чтобы указать доверительный интервал, работаем через четыре шага ниже.
- Определите образец статистики.Поскольку мы пытаемся оценить средний вес в популяции, выбираем средний вес в нашей выборке (180) в качестве выборочной статистики.
- Выберите уровень достоверности. В этом случае уровень достоверности определяется для нас в задаче. Мы работаем с 95% уровень уверенности.
- Найдите погрешность. Ранее мы описывали как вычислить погрешность.
Ключевые шаги показаны ниже.
- Найдите стандартную ошибку.Стандартная ошибка (SE)
означает:
SE = s / sqrt (n)
SE = 30 / sqrt (1000) = 30 / 31,62 = 0,95
- Найдите критическое значение. Критическое значение – это коэффициент, используемый для
вычислить погрешность. Чтобы выразить критическую ценность
как
t оценка
(t *), выполните следующие действия.
- Вычислить альфа (α):
α = 1 – (уровень достоверности / 100) = 0.05
- Найдите критическую вероятность (p *):
p * = 1 – α / 2 = 1 – 0,05 / 2 = 0,975
- Найдите
степени свободы (df):
df = n – 1 = 1000 – 1 = 999
- Критическое значение статистика t, имеющая 999 степеней свободы и совокупная вероятность равно 0.975. t Калькулятор распределения, мы находим, что критическое значение составляет 1,96.
Примечание: Мы могли бы также выразить критическое значение как z-оценка. Поскольку размер выборки велик, анализ z-показателя дает Тот же результат – критическое значение, равное 1,96.
- Вычислить альфа (α):
- Расчетная погрешность (ME):
ME = критическое значение * стандартная ошибка
ME = 1.96 * 0,95 = 1,86
- Найдите стандартную ошибку.Стандартная ошибка (SE)
означает:
- Укажите доверительный интервал. Диапазон уверенности интервал определяется статистикой выборки + Погрешность . А неопределенность обозначается уровнем достоверности. Следовательно, этот 95% доверительный интервал составляет 180 + 1,86.
